

不完美 Kubernetes Storage:Volume, PersistentVolume, PersistentVolumeClaim, Provisioner, StorageClass, VolumeClaimTemplate and StatefulSet - Part 4
回顾
在part3中,我们已经了解了Kubernetes Storage中的以下概念。
- Volume
- PersistentVolume
- PersistentVolumeClaim
- Static Provisioning
- Dynamic Provisioning
- StorageClass
- Provisioner
那么请问有哪几种方法可以让pod内的某个container将数据保存到pod所在node的某个目录下面?提示:到目前为止我们知道最少有三种方法:
- Volume
- Persisten Volume
- Provisioner
StatefulSet
StatefulSet的出现,是为了解决Deployment所遇到的问题。Deployment使用来解决stateless pod的部署问题,在遇到需要mount volume的pod的时候,Deployment会遇到问题,所以Kubernetes引入了StatefulSet。
Deployment遇到的问题
还是来看一个具体的例子。
# sc-definition.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: google-storage
provisioner: kubernetes.io/gcd-pd
# pvc-definition.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: data-volume
spec:
accessModes:
- ReadWriteOnce
storageClassName: google-storage
resource:
requests:
storage: 500Mi
# deploy-random-number-generator.yaml
apiVersion: app/v1
kind: Deployment
metadata:
name: random-number-generator
label:
app: random-number-generator
spec:
replica: 1
selector:
matchLabels:
app: random-number-generator
template:
metadata:
labels:
app: random-number-generator
spec:
containers:
- image: alpine
name: alpine
command: ["/bin/sh", "-c"]
args: ["shuf -i 0-100 -n 1 >> /opt/number.txt"]
volumeMounts:
- name: data-volume
mountPath: /opt
restartPolicy: OnFailure
volumes:
- name: data-volume
persistentVolumeClaim:
claimName: data-volume
平平无奇的一个示例,和系列中之前的示例是类似的,只不过用Deployment替换了之前示例中的Pod。但是现在需要你回答几个问题。
- 当pod被删除,但ReplicaSet重新部署pod后,新的pod是会mount之前的PV,还是会被Provisioner分配新的PV?
- 如果replica被设定为3,那么这3个pod是mount同样的PV,还是每个pod会被分配自己的PV?
- 当replica被设定为3,那么当某一个pod被删除,然后又被ReplicaSet重新部署部署后,新的pod是会mount之前的PV,还是会被Provisioner分配新的PV?
Deployment无法回答以上问题,因为一开始我们就用错了对象,Deployment不是用来解决以上问题的,如果不幸因为误解使用Deployment管理mount了volume的pod,那么你很有可能会遇到类似的典型Kubernetes问题。
When dynamically creating a PVC and then referencing it from within a deployment, this claim becomes global across the deployment. So if I increase the deployment to more than one pod, everything from pod no. 2 onwards will fail as it the other pods will also attempt to claim the volume, but will be unable to do.
意思是说,如果使用Dynamic Provisioning的方法创建了PVC,而且在deployment中引用了这个PVC,那么这个PVC对于整个deployment来说是全局的。所以如果当replica的值大于1时,最多只会有一个pod会被成功创建,因为其他的pod都会尝试着去claim这个PV,而这个PV已经被第1个成功创建的pod一对一的bind了。
解决以上问题需要新的工具——StatefulSet。为了理解StatefulSet,我们先来看一个典型的Stateless和Stateful应用。
Stateless & Stateful
Deployment是被设计用来管理“无状态(Stateless)”pod的,每个pod都完全一致。

如上图所示,对于绿色的服务back-end,每个replica的pod都在一个back-end Service之后,back-end是负载均衡的(可能Service的类型是Loadbanlancer或者ClusterIP),用户并不知道自己的服务请求到底被Service分配到了哪个具体的pod。要达到这种效果,pod必须是无状态的;如果pod保存了状态,那么它就是“有状态(Stateful)”的了,再使用这个结构就会造成运行前后数据不一致而导致的数据败坏。
以session方式登录来举例,如果front-end到back-end的第一次请求被Service分配到了ip为19.244.0.5的pod,且具体处理这个请求的container在自己内部保存了session,若front-end的第二次请求被分配到了IP为10.244.0.6的pod,这个pod中负责处理请求的container并不知道session的内容,则会认为用户没有登录。
这就好比用户在一开始登录成功后,点击了一下页面进行具体浏览,结果页面蹦出来对话框说用户没有登录,请再次登录一样。前后数据不一致,导致用户登录数据的败坏。
如果我们改为“无状态”设计,使用token的方式来做登录,每次用户点击页面都会附带上自己的登录token,则无论这个点击被负载均衡器分配到哪个back-end的pod中,其container都可以通过token来获得用户是否已经登录的信息,则不会产生用户登录数据的败坏。
面对现实,程序架构不可能设计成完全无状态的,数据总要存储吧?在Kubernets体系下,需要把所有有状态的部分封装在某个接口后面,然后在这个接口后面,由这些有状态部分自行管理副本和负载均衡。
Kubernetes之外
为了更好的理解StatefulSet,我们先来看看在Kubernetes之外我们怎么做。我们需要3台服务器,其中1台配置为maste,其余两台配置为slave。外部程序和master的地址打交道,master自动管理loadbalance和replica。
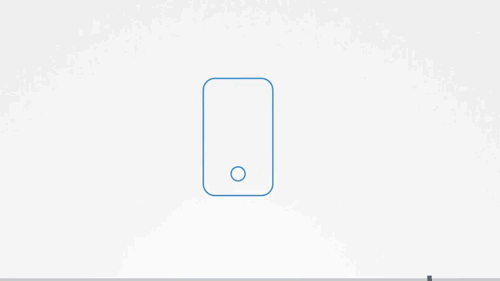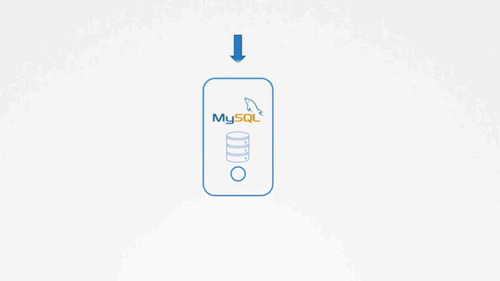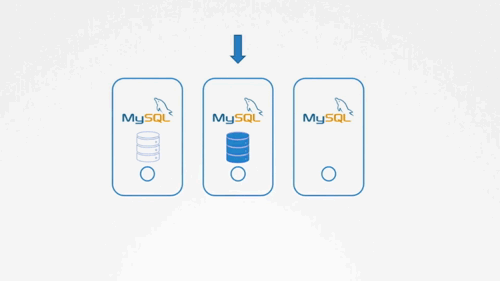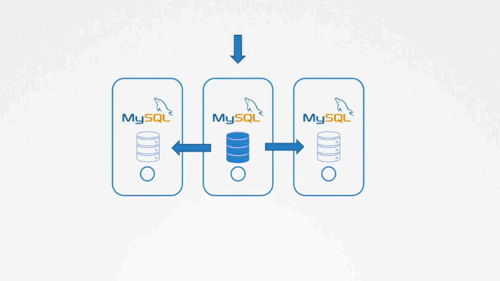
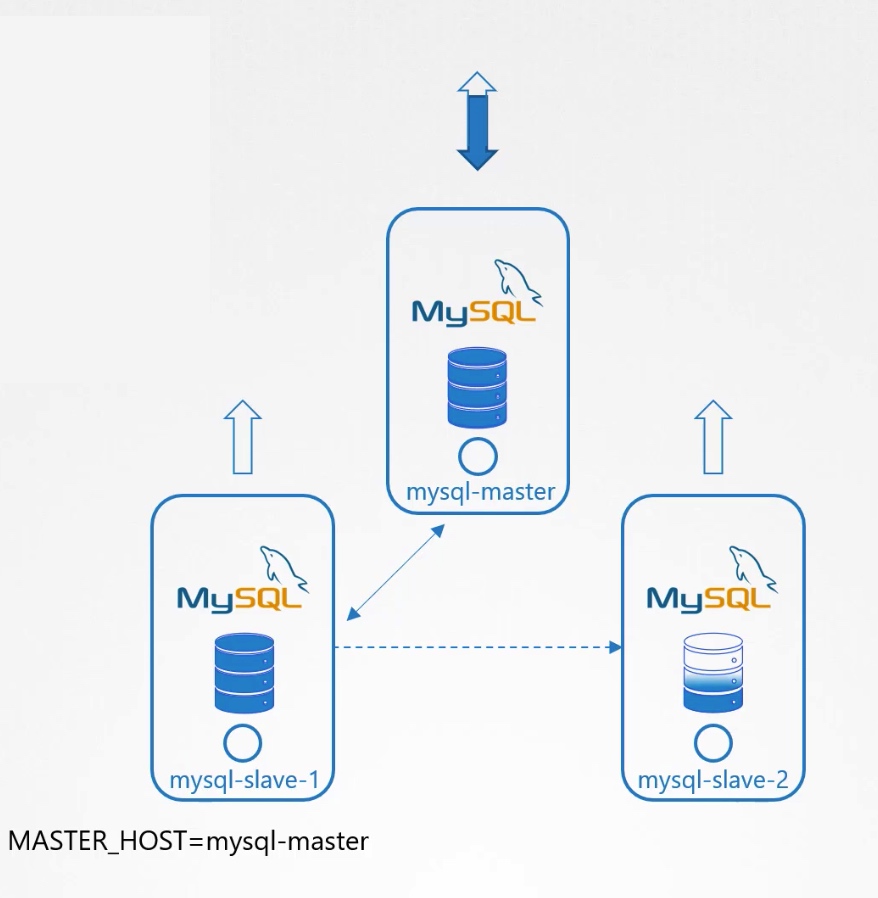
我们来看一下具体的步骤。 1.先建立一个master节点,然后建立slaves节点。
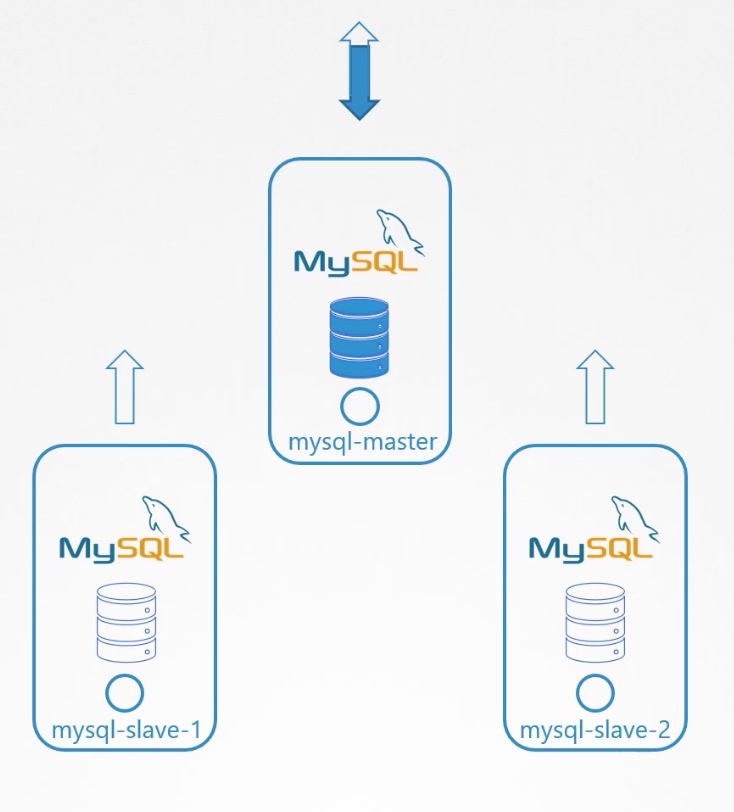
2.把master的数据clone给slave-1。
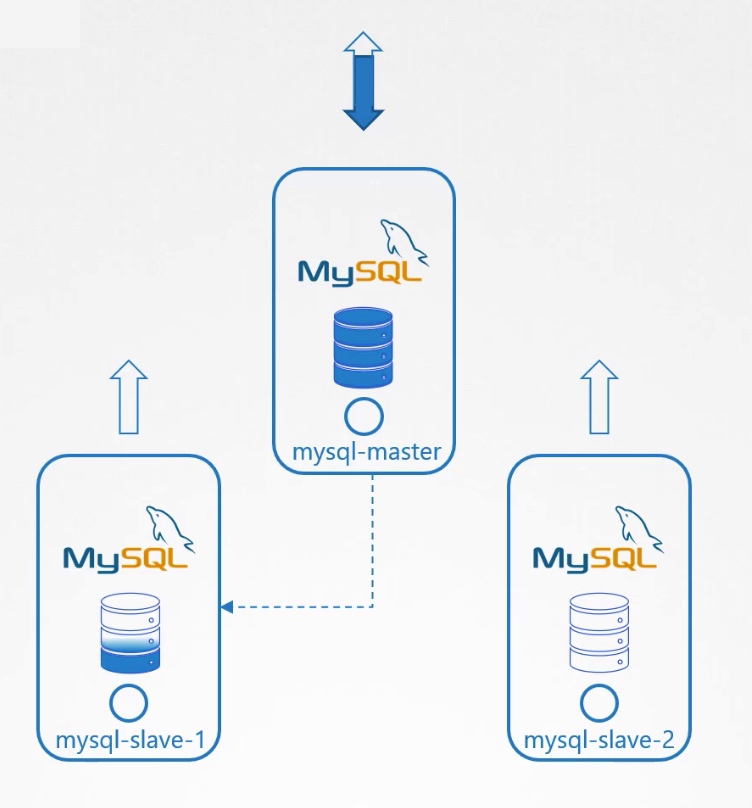
3.使能从master到slave-1的continuous replication。
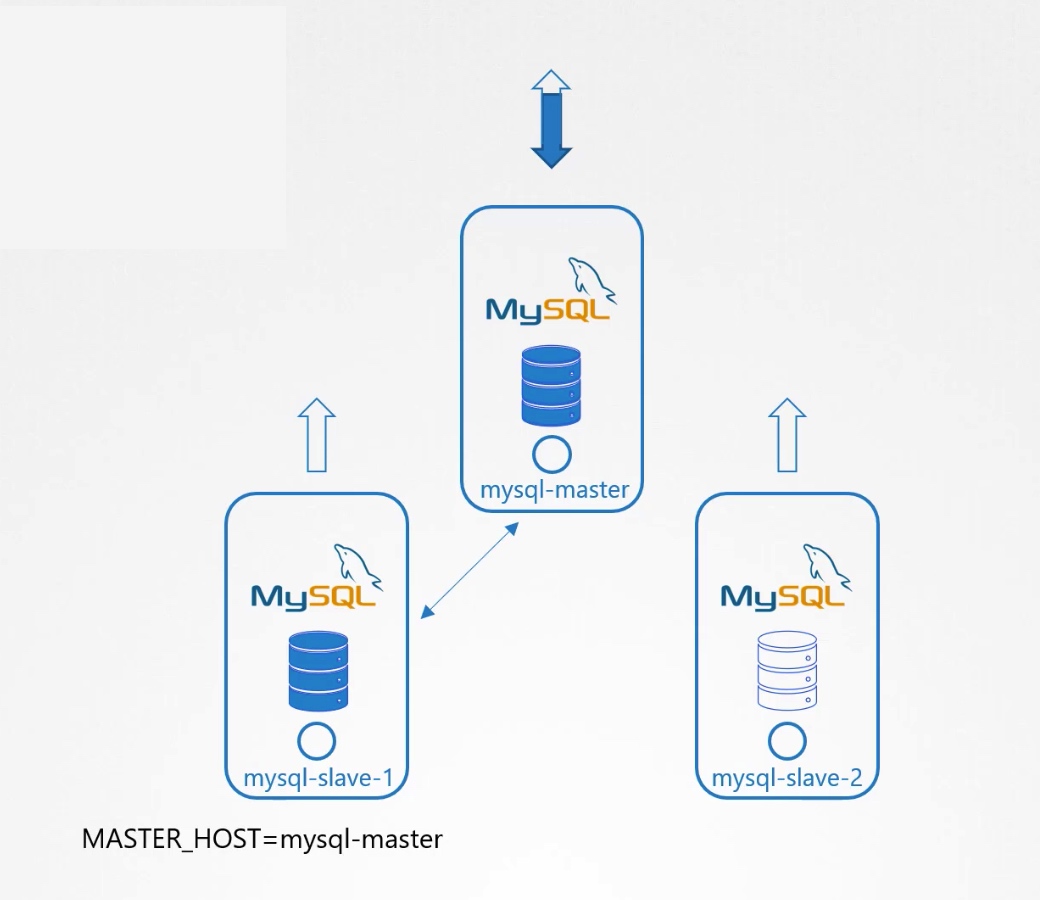
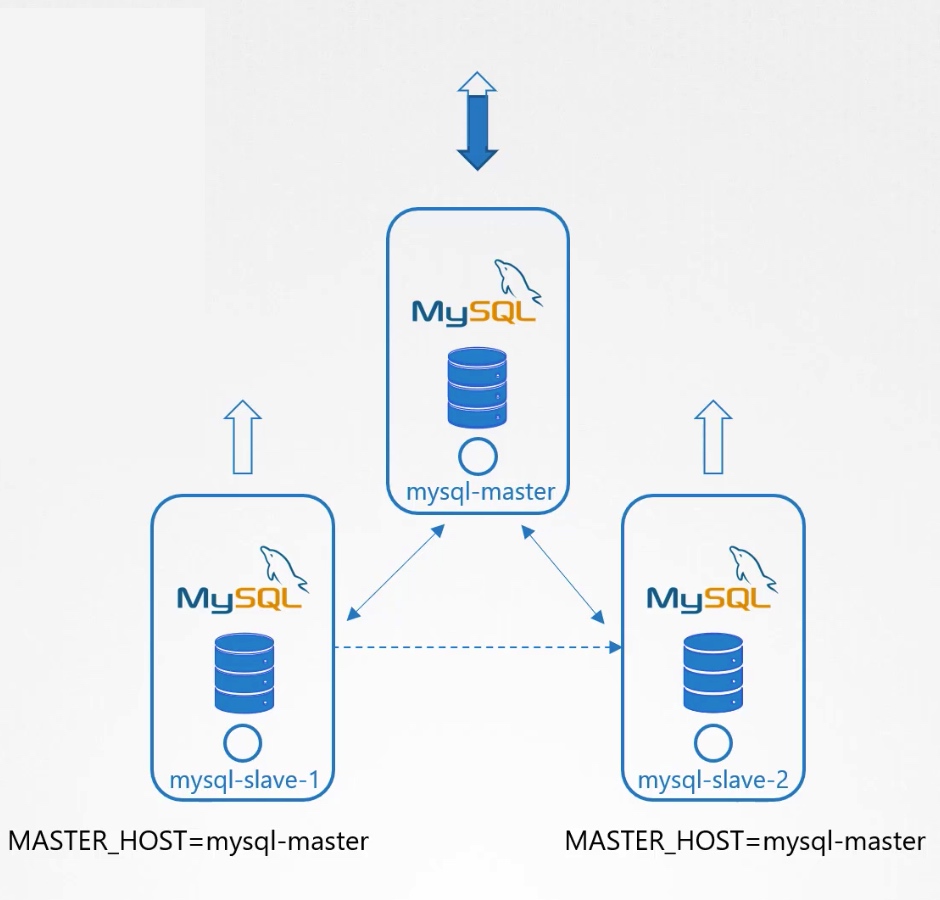
4.等待slave-1建立完毕。 5.从slave-1 clone数据到slave-2
6.使能从master到slave-2的continuous replication。
7.等待slave-2建立完毕。
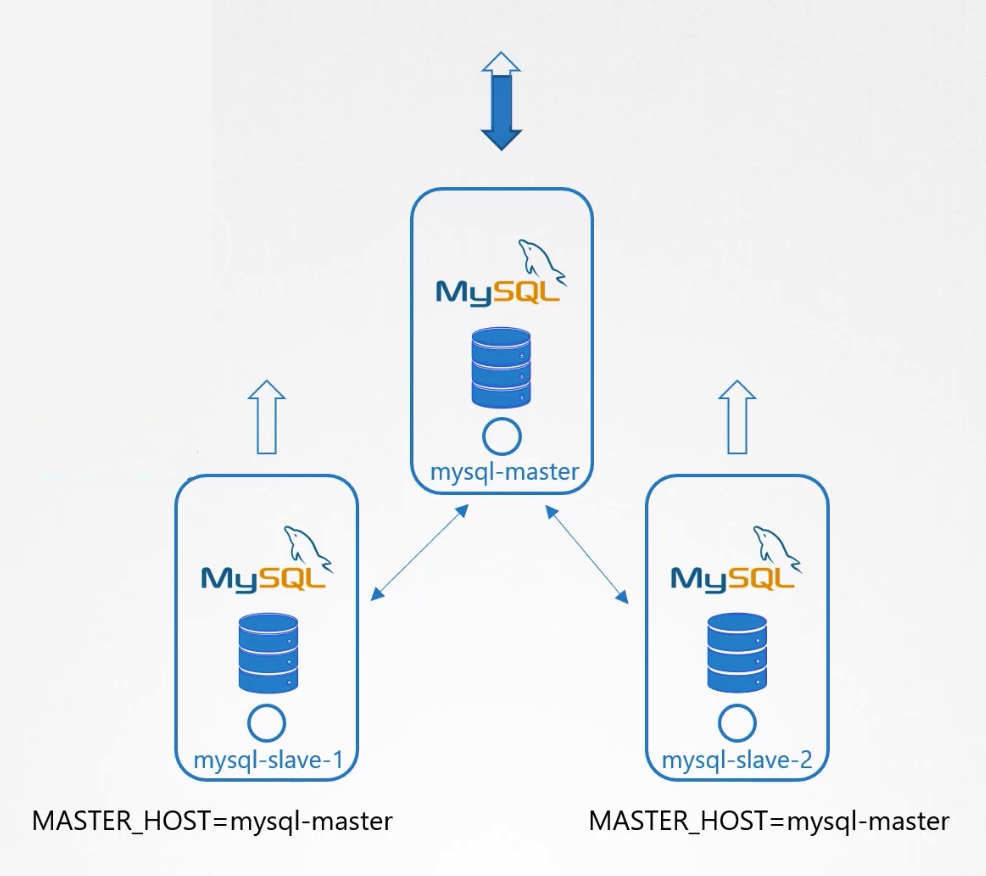
Kubernets之内
如果上述架构和步骤放到Kubernetes内部,我们发现Deployment是无法满足我们的需求的。
- 无法控制Pod建立的先后顺序。Deployment是试图同时建立Pod的。
- 无法固定的访问指定的Pod。Deployment所建立的Pod名称是随机的。一个Pod被撤销后再次建立,其名称和IP都会发生变化。
- 无法自动在每个Pod中的Container可以自动获取独立的存储空间。存储空间的claim是共享的。
所以Kubernetes提供了一个新的工具——StatefulSet,来统一解决上述问题。
