

导读
阅读完此文,你会了解:
1、常用的WebGL渲染文字的方法
2、朝向相机的策略
3、POI碰撞检测的策略
4、POI的背景或背景图如何和文字做混合渲染
渲染方式
在WebGL中渲染文字,并不是一件简单的事情。
DOM
简单且常用到的渲染文字的方法是通过 dom 生成 html 元素。该方法只需要了解一个三维坐标点是如何投影到屏幕坐标,每次相机或者是坐标变化时,改变其css样式中的坐标或是transform,就可以实现一个具有所有dom元素该有css样式的文字效果。
更多的计算可以参考:WebGL 文字 - HTMLwebglfundamentals.org
DOM文字
这种方法适用于对于文本样式要求较高,且数量不多的场景。
TextGeometry
刚刚学习THREE.JS的同学,会有一些比较洋气的方法,直接通过TextGeometry,生成三维文字的网格,这种出来的效果就是很立体,适合做突出文字展示的场景,并不适合文字做辅助信息展示的场合,而且生成的文字网格顶点数量也很大。

Canvas
普适性较好的方式是使用文字贴图,通过上传纹理做文字贴图的方法,比较适合做大量文字渲染的场景。下图为早期百度地图的文字雪碧图示例,他们采用的技术是在后端根据有样式需求,将瓦片的文字雪碧图渲染出来传给前端。

使用Canvas的动态绘制文字贴图,为了减少纹理上传的次数,需要将文字渲染到一张大图上。生成雪碧图简单的做法可以保存一个网格数据,记录当前雪碧图每行的横向标尺,以及行高,每次渲染poi的时候找到合适的槽位。
计算纹理贴图:
grid = [{ left, height, bottom}]
const getGridRow = function (text, fontSize) {
const gridLength = grid.length
const tWidth = text.length * fontSize
const tHeight = fontSize
let rowIndex = grid.findIndex((d, i) => {
return ((canvasWidth - d.left) >= tWidth) && (d.height >= tHeight)
})
if (rowIndex < 0) {
const bottom = grid[gridLength - 1].bottom + height
grid.push({
left: 0,
bottom: bottom,
height: height
})
rowIndex = gridLength
}
return grid[rowIndex]
}
对于每个POI,维护一份其在雪碧图上的坐标范围:起始坐标以及宽高,用来计算其uv。其中文字的高度用fontSize获得,文字的宽度用measureText来做测量。
const getPoiUvOffset = function (text, fontSize) {
const fontSizeBuf = fontSize * 1.2
const row = getGridRow(text, fontSizeBuf)
ctx.font = fontSize
ctx.textBaseline = 'middle'
const tHeight = fontSizeBuf
const tWidth = ctx.measureText(text).width
const poi = {
text: text,
startX: row.left,
startY: row.bottom - fontSizeBuf,
width: tWidth / 2,
height: tHeight / 2
}
ctx.fillText(poi.text, poi.startX, row.bottom - tHeight / 2)
return [
startX / canvasWidth,
1 - startY / canvasHeight,
tWidth / canvasWidth,
tHeight / canvasHeight
const getPoiUvOffset = function (text, fontSize) {
const fontSizeBuf = fontSize * 1.2
const row = getGridRow(text, fontSizeBuf)
ctx.font = fontSize
ctx.textBaseline = 'middle'
const tHeight = fontSizeBuf
const tWidth = ctx.measureText(text).width
const poi = {
text: text,
startX: row.left,
startY: row.bottom - fontSizeBuf,
width: tWidth / 2,
height: tHeight / 2
}
ctx.fillText(poi.text, poi.startX, row.bottom - tHeight / 2)
return [
startX / canvasWidth,
1 - startY / canvasHeight,
tWidth / canvasWidth,
tHeight / canvasHeight
]
}]
}
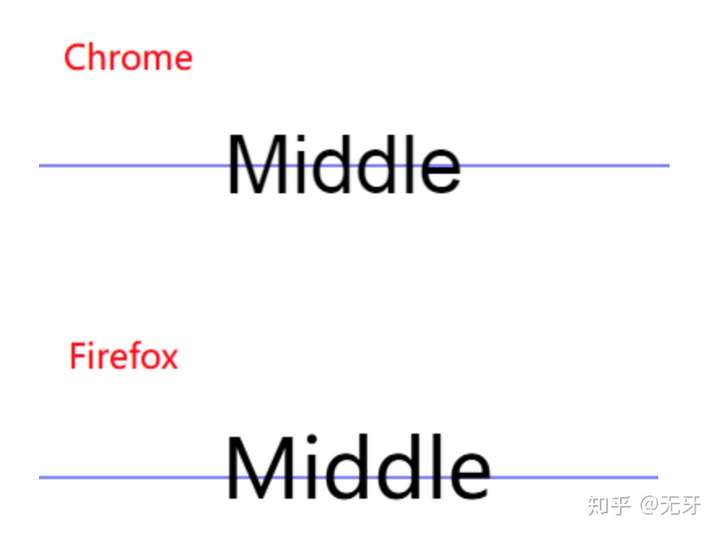
在做文字雪碧图的时候,我们发现不同的浏览器对于基线的表现方式略有不同,如果高度使用fontSize,就很容易有文字被砍了“头”,或者是砍了“脚”的现象出现。因此我们在计算文字雪碧图的时候,会采用middle的对齐方式,行间距*1.2倍,以留下浏览器兼容性的buffer。

字符集
此外,对于英文这种有限可枚举的字符场景,也通常会用到字符集的方法,即一次性上传字符所有纹理,记录下所有字符的位置,在渲染文本的时候,逐字符拼接达到效果。这种方法的好处是纹理贴图一旦生成就无需再更新,但是在放大时,就会出现较明显的模糊痕迹。

SDF
为了解决字符缩放时的清晰度问题,地理场景中也常常会用到SDF(有向距离场)字符。SDF的方法旨在用较小的像素数,解决各种尺度的文字渲染问题。具体的说,就是通过距离场记录像素网格中,每个点到边缘的距离,符号为外负内正,这样就通过矢量距离描述了字符中的边缘,在着色器中,结合smoothstep对边缘处做平滑处理,就可以轻易化解边缘问题。

lowp vec4 color=fill_color;
highp float gamma=EDGE_GAMMA/(fontScale*u_gamma_scale);
lowp float buff=(256.0-64.0)/256.0;
if (u_is_halo) {
color=halo_color;
gamma=(halo_blur*1.19/SDF_PX+EDGE_GAMMA)/(fontScale*u_gamma_scale);
buff=(6.0-halo_width/fontScale)/SDF_PX;
}
lowp float dist=texture2D(u_texture,tex).a;
highp float gamma_scaled=gamma*gamma_scale;
highp float alpha=smoothstep(buff-gamma_scaled,buff+gamma_scaled,dist);
gl_FragColor=color*(alpha*opacity*fade_opacity);
sdf的生成方法可参考:github.com/mapbox/tiny… 。
使用SDF的方法,也是需要生成一个字符集,如下是高德地图的SDF字符集。
 高德地图字符集
高德地图字符集
SDF方法整体上看,可以很好的解决字体放大时的清晰度问题,但是在较小字体时的表现会使拐角过于平滑。由于在我们的业务场景中,POI通常不会超过20px,且常用中文字符集要5000+,合成最后的字符集一个字32px算的话,需要5张1024* 1024的字符集,所以我们在短暂的尝试了SDF方法之后,采用了在Canvas上将字体放大两倍渲染的方法。
POI朝向
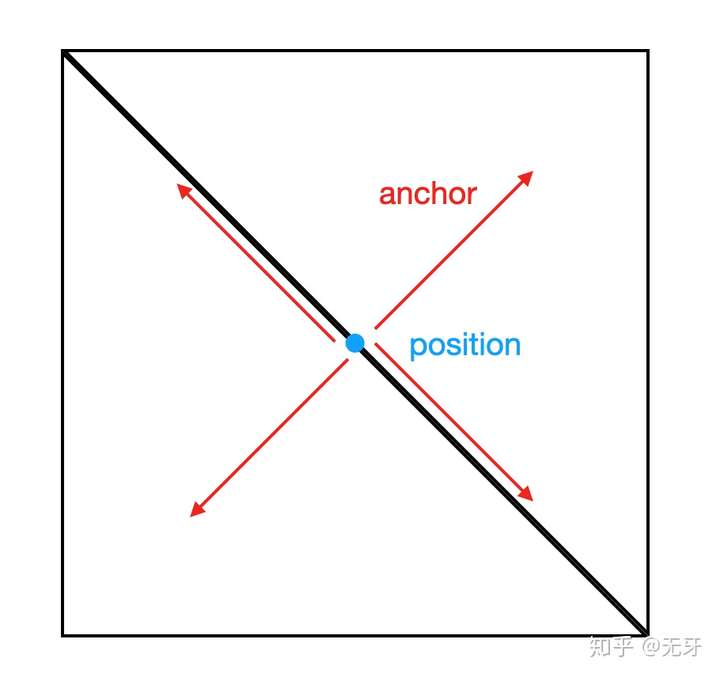
POI需要像billboard一样永远朝向相机,且用户输入的fontSize通常是像素值,在计算网格面的时候,需要在vs的部分,将其做三维坐标到屏幕坐标及尺寸的转换。
我们将网格面的所有顶点用(0,0)表示,再附加一个anchor值表示其4个顶点的拉伸方向,就有一个面的最终顶点位置为 vec2(position) + vec2(anchor) * vec2(width, height),得到下面的顶点变换:
vec4 projected_position = projectionMatrix * modelViewMatrix * vec4(position.xyz, 1.);
gl_Position = vec4(projected_position.xy / projected_position.w + (a_anchor * a_size) * 2.0 / u_resolution, 0.0,1.0);
 顶点计算方法
顶点计算方法
碰撞检测
通过canvas贴图生成的POI文字,以纹理的形式贴到三维场景中的Mesh上,最终在着色器中换算为朝向屏幕的二维坐标。地图场景中的POI熙熙攘攘,多到重叠。这就需要做一些碰撞检测,让重叠的POI隐藏。
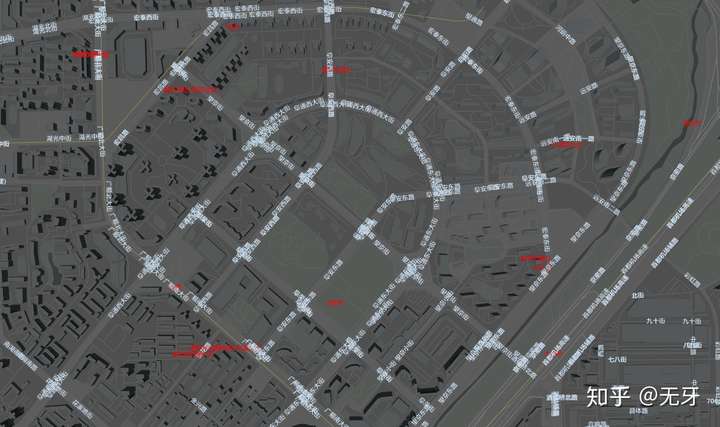
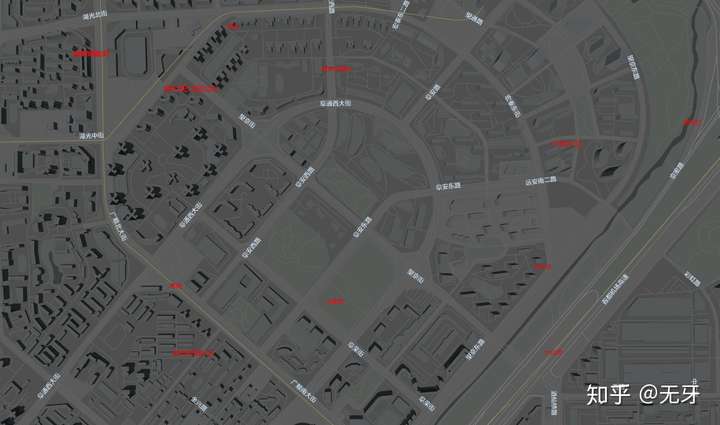
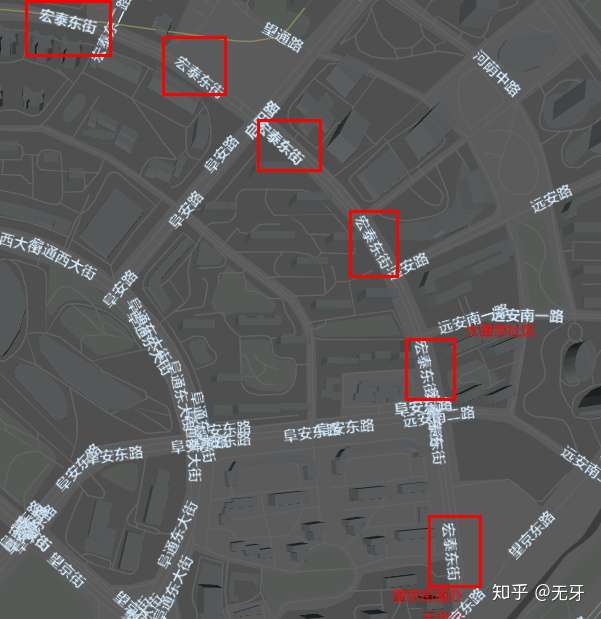
图中,红色字为POI,白色字为路名称。碰撞检测前,文字之间会有许多相交重叠的情况,杂乱无章,影响阅读体验;碰撞检测之后,显得有序,体验更好。接下来我们介绍一下碰撞检测的算法以及显示效果的优化。
算法
每个文本都有一个矩形的包围盒,包围盒可以旋转,检测这些包围盒之间能否产生碰撞,就可以得出文本能否在地图上可见。维护一个数组visibleArray,用于存储可以在地图上显示出来的文本。在地图上,从第一个文本开始放置,并将第一个文本存储在visibleArray中;以后每次放置新的文本,都和visibleArray中文本进行碰撞检测;如果a0中存在文本和此文本产生碰撞,表示该文本不能在地图上可见;反之,将会在该文本在地图上可见,并将该文本放入visibleArray中。
function textCollision (texts) {
const visibleArray = [] // 存储可见文本
for (let i = 0; i < texts.length; i++) {
if ((i === 0) || (!visibleArray.some(item => isCollision(texts[i].bbox, item)))) { // 第一个文本或者不和已经可见的文本产生碰撞的文本会被标记为可见
texts[i].visible = true
visibleArray.push(texts[i])
}
}
}
实现 isCollision() 函数需要了解一下包围盒的3种关系:


对文本进行碰撞检测就是检测文本包围盒之间是否存在内含与相交的关系。
内含关系检测
如果一个矩形包围盒在另一个矩形包围盒内部,那么这个矩形包围盒的四个顶点都在另一个矩形包围盒内部。
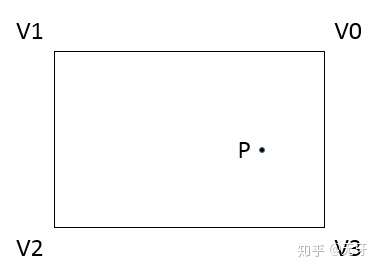
如果满足条件:
(0 < dot(PV0,V1V0) < dot(V1V0,V1V0)) && (0 < dot(PV0,V3V0) < dot(V3V0,V3V0))
那么,点P在矩形V0V1V2V3内部。
循环检测四个顶点,如果4个顶点都满足以上条件,那么这两个矩形存在内含的关系。
/**
* 点P是否在矩形rect内部
*/
function isPointInRect (rect, P) {
const [V0, V1, V2, V3] = rect.getVertexes()
return (0 <= dot(PV0, V1V0) <= dot(V1V0, V1V0)) && (0 <= dot(PV0, V3V0) <= dot(V3V0, V3V0))
}
/**
* 获取rect0中内含的rect1的顶点的数量
*/
function getContainedVertexesNum (rect0, rect1) {
const vertexes1 = rect1.getVertexes()
let count = 0
for (let i = 0; i < vertexes1.length; i++) {
if (isPointInRect(rect0, vertexes1[i])) {
count++
}
}
return count
}
/**
* 两个矩形是否存在内含关系
*/
function isContained (rect0, rect1) {
return (getContainedVertexesNum(rect0, rect1) === 4) || (getContainedVertexesNum(rect1, rect0) === 4)
}
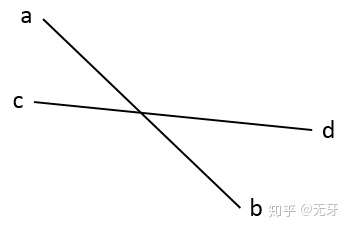
如果两个矩形包围盒相交,那么两个矩形至少可检测到一组边相交。如果线段ab与cd相交,a点和b点分别在线段cd两侧,c点和d点也必须同时在线段ab两侧。
如果满足条件:
cross(ab, ac) * cross(ab, ad) <= 0
那么点c点d分别在线段ab的两侧。
如果同时满足:
(cross(ab, ac) * cross(ab, ad) <= 0) && (cross(cd, ca) * cross(cd, cb) <= 0)
那么线段ab与线段cd相交。
检测矩形包围盒边是否相交:
/**
* 两个矩形是否相交
*/
function isRectIntersect (rect0, rect1) {
const borders0 = this.getBorders()
const borders1 = rect.getBorders()
for (let i = 0; i < borders0.length; i++) {
for (let j = 0; j < borders1.length; j++) {
if (isLineIntersect(borders0[i], borders1[j])) {
return true
}
}
}
return false
}
/**
* 两个线段是否存在相交关系
*/
function isLineIntersect (line0, line1) {
const v0 = {
x: line0.v1.x - line0.v0.x,
y: line0.v1.y - line0.v0.y
}
const v1 = {
x: line1.v1.x - line1.v0.x,
y: line1.v1.y - line1.v0.y
}
const ret0 = cross(v0, line1.v0) * cross(v0, line1.v1) <= 0
const ret1 = cross(v1, line0.v0) * cross(v1, line0.v1) <= 0
return ret0 && ret1
}
function cross (v0, v1) {
return v0.x * v1.y - v0.y * v1.x
}
isCollision()函数最终可实现为:
/**
* 矩形是否碰撞
*/
function isCollision (rect0, rect1) {
return isRectIntersect(rect0, rect1) || isContained(rect0, rect1)
}
碰撞检测优化
碰撞检测是十分耗时的,严重影响了用户体验,我们从以下几个方面进行了优化。
减少要进行碰撞检测的文本数据量
减少文本数量可以从两个方面进行,一是在地图样式编辑器中设置不同层级下哪种文本类型需要显示,二是制定文本减少的策略。
在不同的层级下,人们关注的文本也是不同的。比如,在低层级下,人们只会关注高速名称、国道名称等,在高层级下才会去关注更加具体的道路名称,比如乡道名称。在进行样式配置时,需要设定哪个层级显示哪一类文本,样式配置中显示出来的文本才会进行下一步的过滤。
碰撞检测时机
首先第一次的碰撞检测,发生在当前屏幕内所有瓦片加载完毕后,而后每次伴随有新旧瓦片交替的场景,都是选择在所有瓦片加载后才进行碰撞检测。
当用户进行交互时,也不必在交互过程中进行文本碰撞检测,而是在交互结束时,进行碰撞检测。
结论
经过上面减少数据量和碰撞检测时机的优化,每次碰撞检测的时间从原先的100ms减少到10ms以下,提升了用户交互时的体验。
文字背景色
用canvas画出来的文字,总是会有一个挥之不去的黑边,这个与canvas无关,推测是在纹理做上传时候导致的。

解决黑边问题,我们需要准确的识别出字和背景的边界。假设背景是黑色(0x000000),那么通过两个特定的颜色分别表示填充色和边框色,可以准确的找到边界,利用边界做颜色混合,此方法需将文字的填色方式从canvas调整到fs中。我们利用g通道,区分字的填充色和边框色,用r通道,区分字的填充部分和非填充部分。这样就有:
vec4 textColor = texture2D( texture, uv );
vec4 fontColor = mix(v_strokecolor, v_fillcolor, textColor.g);
fontColor.a *= fontColor.r;
其中fontColor是结合g通道,混合的字体颜色,其透明度通过乘以纹理颜色的r值,得到字体的边界,以及边界外不显示。

某些场景下,还需要给文字一些背景色,背景图。
这就需要在着色器中模拟一个透明物体从后向前渲染,颜色blending的过程。
通过公式颜色混合公式:
可以得到:
vec3 rgb = mix(backgroundColor.rgb * backgroundColor.a, fontColor.rgb, fontColor.a);
float a = fontColor.a + backgroundColor.a * (1. - fontColor.a);
vec4 color = vec4(rgb / a, a);
其中最后的除法,是因为考虑到字体颜色存在透明度,背景色也存在透明度,那么叠加出来的颜色,也是应该有透明度的。

有了这样的混合逻辑,就可以任性的在文字后面想加什么加什么,比如加个背景图:
文字渲染相关的内容就这么多。结尾处还是想说,矢量字体(SDF)是十分火的字体渲染方式。碰撞检测的优化也可以放到worker里做,或者将检测的计算分摊到多帧计算,以避免阻塞UI。各种各样的优化方式,有兴趣的朋友可以一起探讨~
请期待下一期:《地图建筑渲染》
