

-
什么是数据库:“按照数据结构组织、管理、存储数据的仓库。”是一个长期存储在计算机内、有组织、可共享、统一管理的大量数据的集合。
-
四层架构
· 连接层
· 服务层(含Optimizer查询优化器)
· 引擎层
· 存储层
- 存储引擎
查看提供的所有引擎:show engines;
查看mysql当前默认的存储引擎:show variables like '%storage_engine%';
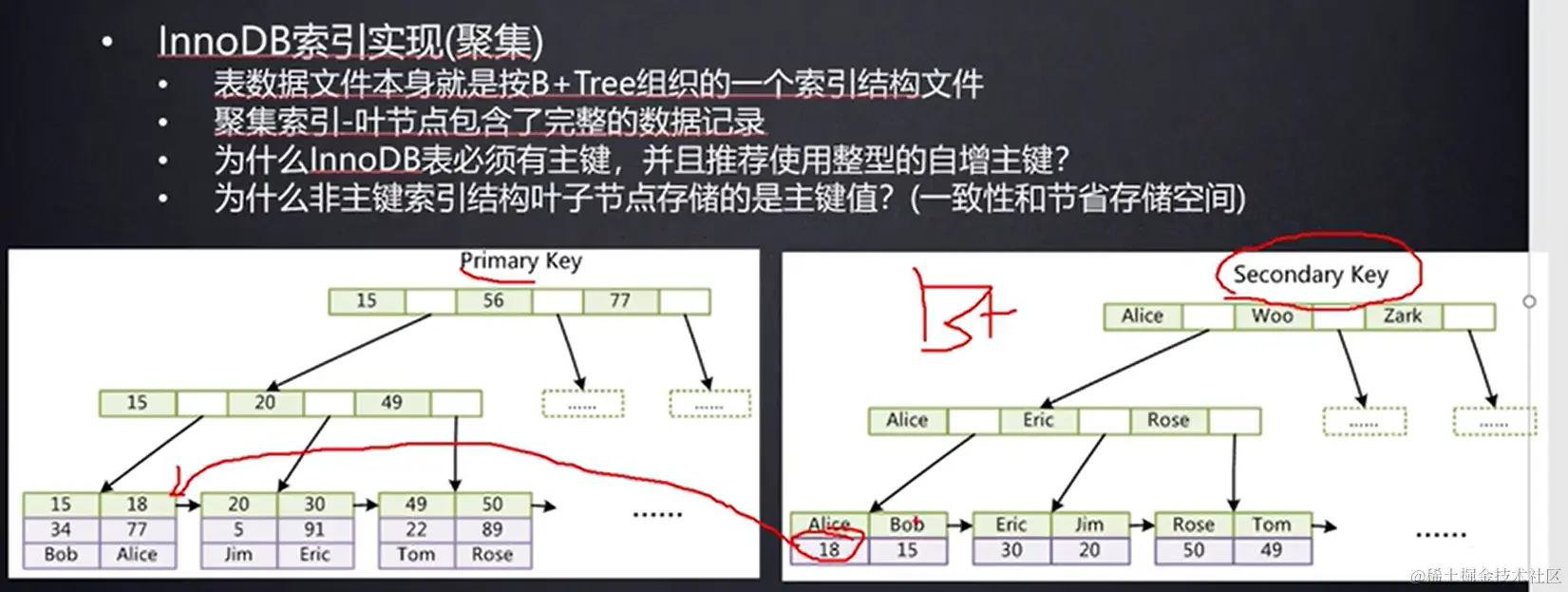
InnoDB存储引擎:mysql默认的事务型引擎;支持主外键;行级锁,适合高并发;缓存时,不仅缓存索引还要缓存真实数据,对内存要求较高,而且内存大小对性能有决定性的影响;表空间大;innodb 索引 使用 B+TREE。 innodb 主键为聚簇索引,基于聚簇索引的增删改查效率非常高。
MyISAM存储引擎:不支持事务;不支持主外键;表级锁;只缓存索引,不缓存真实数据;表空间小;myisam 索引使用 B-TREE(?)。
其它引擎:Archive、Memory、BlackHole、Federated……
- 索引定义:一种排好序的快速查找数据结构。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上
我们平常所说的索引,如果没有特别指明,都是指B树(多路搜索树,并不一定是二叉的)结构组织的索引。其中聚集索引,次要索引,覆盖索引, 复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引。当然,除了B+树这种类型的索引之外,还有哈稀索引(hash index)等。
B树和B+树的区别:
补充:为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引?
-
B+树的磁盘读写代价更低
-
B+树的查询效率更加稳定
-
聚簇索引:数据行在磁盘的排列和索引排序保持一致。(叶子节点包含完整数据记录--索引和数据,如InnoDB)
-
主键索引:设定为主键后数据库会自动建立索引,innodb为聚簇索引。
单值索引:即一个索引只包含单个列,一个表可以有多个单值索引。
唯一索引:索引列的值必须唯一,但允许有空值。
复合索引:即一个索引包含多个列。
(数据库操作期间,对于相同的多个列建索引,复合索引比单值索引所需要的开销更小;当表的行数远大于索引列的数目时可以使用复合索引)
-
哪些情况需要创建索引:
(1)主键自动创建索引。
(2)经常被查询的字段建立索引。
(3)被其它表关联的字段(JOIN)、外键关系建立索引。
(4)排序字段(ORDER BY后的字段)。
(5)统计或分组的字段(GROUP BY后的字段)。
- 哪些情况不要创建索引:
(1)表记录太少。
(2)经常增删改的字段。
(3)where条件用不到的字段。
(4)数据重复且分布平均的表字段。
-
EXPLAIN:使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈
字段意义:
id: select查询的序列号。表示执行select子句或操作表的顺序。 id相同,从上到下执行;id不同,id值越大,执行优先级越高,越先被执行。
select_type: 查询的类型(普通查询SIMPLE、联合查询UNION、子查询SUBQUERY……)
table: 表示这一行数据来自哪张表。
type: system>const>eq_ref>ref>range>index>ALL (常见类型最好到最差排列) system:表只有一行记录(等于系统表)。 const:表示通过索引一行就找到了,如where id='1'。 eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。。 ref:非唯一性索引扫描,返回匹配某个单独值的所有行。 range:只检索给定范围的行,使用一个索引来选择行。 index:全索引扫描。 ALL:全表扫描。 备注:一般来说,得保证查询至少达到range级别,最好能达到ref。
possible_keys:显示可能应用在这张表中的索引,一个或多个。
key:实际使用的索引。如果为NULL,则没有使用索引。 (查询中若使用了覆盖索引,则该索引和查询的select字段重叠)
key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数。
rows:显示MySQL认为它执行查询时必须检查的行数。
extra:包含不适合在其他列中显示但十分重要的额外信息。 Using filesort:说明mysql会对数据使用一个外部的索引排序,而不是按照表 内的索引顺序进行读取。 Using temporary:使了用临时表保存中间结果,MySQL在对查询结果排序时使用 临时表(常见于order by、group by)。 Using index:表示相应的select操作中使用了覆盖索引(Covering Index), 避免访问了表的数据行,效率不错!如果同时出现using where,表明索引被用 来执行索引键值的查找;如果没有同时出现using where,表明索引只是用来读取 数据而非利用索引执行查找。 Using where:表明使用了where过滤。 using join buffer:使用了连接缓存。 impossible where:where子句的值总是false,不能用来获取任何元组。 select tables optimized away:。。。
索引覆盖:①一个索引 ②包含了(或覆盖了)[select子句]与查询条件[Where子句]中 ③所有需要的字段就叫做覆盖索引。
- 使用索引的规则:
(1)全值匹配最优;
(2)最佳左前缀原则;
(3)不在索引上做任何操作(计算、函数、类型转换等),否则索引失效并转为全表扫描;
(4)存储引擎不能使用索引中范围条件右边的列(range)
(5)尽量使用索引覆盖;
(6)!=、<>、is not null、or会导致索引失效;
(7)like以通配符开头,会导致索引失效;如果以具体值开头,其后面列索引不会失效;
(8)字符串不加单引号索引失效。
(9)join表时,保证被驱动表的join字段已经建立索引(left join 建右表索引,right join建左表索引);
(10)小表驱动大表(参考指标:磁盘io);
(11)用in时,大表放在括号外;用exists时,大表放在括号内(根据执行顺序达到小表驱动大表的目的)
(12)使用ORDER BY时,重要指标:是否发生Using filesort;可以与where后的列连起来使用最佳左前缀法则,(但ORDER BY后的列不能颠倒顺序,where后的列顺序无关)进而达到Useing index;排序顺序不一致(一个升序一个降序)会导致索引失效;
(13)GROUP BY实质是先排序后分组。
- mysql锁机制:
(1)表锁:偏向MyISAM存储引擎,开销小,加锁快;无死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
加了表锁之后:读锁会阻塞写,不会堵塞读;而写锁则会读写都阻塞。
如:开启两个会话,session1和session2,对tbl进行操作。
加读锁:session1只能读tbl表,不能读其它表,且不能写任何表;sessoin2可以读tbl和其它表,且对tbl表的写会阻塞。
加写锁:session1可以读写tbl,但不能读其它表;而session2对tbl的读被阻塞。
(2)行锁:偏向InnoDB存储引擎,开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
无索引行锁会升级为表锁。
间隙锁(危害性能):当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(GAP Lock)。
- 事务
事务是由一组SQL语句组成的逻辑处理单元,事务具有以下4个属性,通常简称为事务的ACID属性。
原子性(Atomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
持久性(Durable):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
- 并发处理事务的问题:
更新丢失:当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题--最后的更新覆盖了由其他事务所做的更新。
脏读:一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。(事务A读取到了事务B已修改但尚未提交的的数据,还在这个数据基础上做了操作。此时,如果B事务回滚,A读取的数据无效,不符合一致性要求。)
不可重复读:在一个事务内,多次读同一个数据。在这个事务还没有结束时,另一个事务也访问该同一数据。那么,在第一个事务的两次读数据之间。由于第二个事务的修改,那么第一个事务读到的数据可能不一样,这样就发生了在一个事务内两次读到的数据是不一样的,因此称为不可重复读,即原始读取不可重复。 (一个事务范围内两个相同的查询却返回了不同数据。)
幻读:一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据。(事务A 读取到了事务B提交的新增数据,不符合隔离性。)
- 事务的隔离级别:
15.MVCC
