

一滴水,用显微镜看,也是一个大世界。本文已被 https://www.yourbatman.cn 收录,里面一并有Spring技术栈、MyBatis、JVM、中间件等小而美的专栏供以免费学习。关注公众号【BAT的乌托邦】逐个击破,深入掌握,拒绝浅尝辄止。
✍前言
各位好,我是YourBatman。从本文起,终于要和Jackson的“高级”部分打交道了,也就是数据绑定jackson-databind模块。通过接触它的高级API,你会持续的发现,前面花那么多篇幅讲的core核心部分是价值连城的。毕竟村上春树也告诉过我们:人生没有无用的经历嘛。
jackson-databind包含用于Jackson数据处理器的通用 数据绑定功能和树模型。它构建在Streaming API之上,并使用Jackson注解进行配置。它就是Jackson提供的高层API,是开发者使用得最多的方式,因此重要程度可见一斑。
虽然Jackson最初的用例是JSON数据绑定,但现在它也可以用于其它数据格式,只要存在解析器和生成器实现即可。但需要注意的是:类的命名在很多地方仍旧使用了“JSON”这个词(比如JsonGenerator),尽管它与JSON格式没有实际的硬依赖关系。
小贴士:底层流式API使用的I/O进行输入输出,因此理论上是支持任何格式的

版本约定
- Jackson版本:
2.11.0 - Spring Framework版本:
5.2.6.RELEASE - Spring Boot版本:
2.3.0.RELEASE
从本文开始,新增导包:
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
Tips:jackson-databind模块它强依赖于jackson-core和jackson-annotations,只需要导入此包,另外两个它自动会帮带进来。
这里需要说明几句:我们知道core包中还有个
jackson-annotations,难道不讲了吗?其实不是,是因为单独讲jackson-annotations并无意义,毕竟注解还得靠数据绑定模块来解析,所以先搞定这个后再杀回去。
✍正文
据我了解,很多小伙伴对Jackson的了解起源于ObjectMapper,止于ObjectMapper。那行,作为接触它的第一篇文章咱们就轻松点,以应用为主来整体的认识它。
功能介绍
ObjectMapper是jackson-databind模块最为重要的一个类,它完成了coder对数据绑定的几乎所有功能。它是面向用户的高层API,底层依赖于Streaming API来实现读/写。ObjectMapper主要提供的功能点如下:
- 它提供读取和写入JSON的功能(最重要的功能)
- 普通POJO的序列化/反序列化
- JSON树模型的读/写
- 它可以被高度定制,以使用不同风格的JSON内容
- 使用Feature进行定制
- 使用可插拔
com.fasterxml.jackson.databind.Module模块来扩展/丰富功能
- 它还支持更高级的对象概念:比如多态泛型、对象标识
- 它还充当了更为高级(更强大)的API:ObjectReader和ObjectWriter的工厂
ObjectReader和ObjectWriter底层亦是依赖于Streaming API实现读写
尽管绝大部分的读/写API都通过ObjectMapper暴露出去了,但有些功能函数还是只放在了ObjectReader/ObjectWriter里,比如对于读/写 长序列 的能力你只能通过ObjectReader#readValues(InputStream) / ObjectWriter#writeValues(OutputStream)去处理,这是设计者有意为之,毕竟这种case很少很少,没必要和常用的凑合在一起嘛。
数据绑定
数据绑定分为简单数据绑定和完全数据绑定:
- 简单数据绑定:比如绑定int类型、List、Map等…
@Test
public void test1() throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
// 绑定简单类型 和 Map类型
Integer age = objectMapper.readValue("1", int.class);
Map map = objectMapper.readValue("{\"name\": \"YourBatman\"}", Map.class);
System.out.println(age);
System.out.println(map);
}
运行程序,输出:
1
{name=YourBatman}
- 完全数据绑定:绑定到任意的Java Bean对象…
准备一个POJO:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Person {
private String name;
private Integer age;
}
绑定数据到POJO:
@Test
public void test2() throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
Person person = objectMapper.readValue("{\"name\": \"YourBatman\", \"age\": 18}", Person.class);
System.out.println(person);
}
运行程序,输出:
Person(name=YourBatman, age=18)
ObjectMapper的使用
在应用及开发中,ObjectMapper绝对是最常使用的,也是你使用Jackson的入口,本文就列列它的那些使用场景。
小贴士:树模型会单独成文介绍,体现出它的重要性
写(序列化)
提供writeValue()系列方法用于写数据(可写任何类型),也就是我们常说的序列化。
- writeValue(File resultFile, Object value):写到目标文件里
- writeValue(OutputStream out, Object value):写到输出流
- String writeValueAsString(Object value):写成字符串形式,此方法最为常用
- writeValueAsBytes(Object value):写成字节数组
byte[]
@Test
public void test3() throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
System.out.println("----------写简单类型----------");
System.out.println(objectMapper.writeValueAsString(18));
System.out.println(objectMapper.writeValueAsString("YourBatman"));
System.out.println("----------写集合类型----------");
System.out.println(objectMapper.writeValueAsString(Arrays.asList(1, 2, 3)));
System.out.println(objectMapper.writeValueAsString(new HashMap<String, String>() {{
put("zhName", "A哥");
put("enName", "YourBatman");
}}));
System.out.println("----------写POJO----------");
System.out.println(objectMapper.writeValueAsString(new Person("A哥", 18)));
}
运行程序,输出:
----------写简单类型----------
18
"YourBatman"
----------写集合类型----------
[1,2,3]
{"zhName":"A哥","enName":"YourBatman"}
----------写POJO----------
{"name":"A哥","age":18}
读(反序列化)
提供readValue()系列方法用于读数据(一般读字符串类型),也就是我们常说的反序列化。
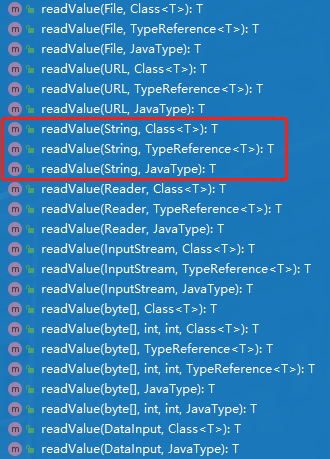
readValue(String content, Class<T> valueType):读为指定class类型的对象,此方法最常用readValue(String content, TypeReference<T> valueTypeRef):T表示泛型类型,如List<T>这种类型,一般用于集合/Map的反序列化- readValue(String content, JavaType valueType):Jackson内置的JavaType类型,后再详解(使用并不多)
@Test
public void test4() throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
System.out.println("----------读简单类型----------");
System.out.println(objectMapper.readValue("18", Integer.class));
// 抛错:JsonParseException 单独的一个串,解析会抛错
// System.out.println(objectMapper.readValue("YourBatman", String.class));
System.out.println("----------读集合类型----------");
System.out.println(objectMapper.readValue("[1,2,3]", List.class));
System.out.println(objectMapper.readValue("{\"zhName\":\"A哥\",\"enName\":\"YourBatman\"}", Map.class));
System.out.println("----------读POJO----------");
System.out.println(objectMapper.readValue("{\"name\":\"A哥\",\"age\":18}", Person.class));
}
运行程序,输出:
----------读简单类型----------
18
----------读集合类型----------
[1, 2, 3]
{zhName=A哥, enName=YourBatman}
----------读POJO----------
Person(name=A哥, age=18)
不同于序列化,可以把“所有”写成为一个字符串。反序列化场景有它特殊的地方,比如例子中所示:不能反序列化一个“单纯的”字符串。
泛型擦除问题
从例举出来的三个read读方法中,就应该觉得事情还没完,比如这个带泛型的case:
@Test
public void test5() throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
System.out.println("----------读集合类型----------");
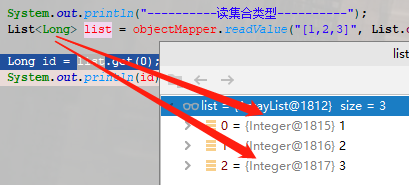
List<Long> list = objectMapper.readValue("[1,2,3]", List.class);
Long id = list.get(0);
System.out.println(id);
}
运行程序,抛错:
----------读集合类型----------
java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.Long
at cn.yourbatman.jackson.core.ObjectMapperDemo.test5(ObjectMapperDemo.java:100)
...
异常栈里指出:Long id = list.get(0);这一句出现了类型转换异常,这便是问题原因所在:泛型擦除,参考图示如下(明明泛型类型是Long,但实际装的是Integer类型):
 对这种问题,你可能会“动脑筋”思考:写成
对这种问题,你可能会“动脑筋”思考:写成[1L,2L,3L]这样行不行。思想很活跃,奈何现实依旧残酷,运行抛错:
com.fasterxml.jackson.core.JsonParseException: Unexpected character ('L' (code 76)): was expecting comma to separate Array entries
at [Source: (String)"[1L,2L,3L]"; line: 1, column: 4]
...
这是典型的泛型擦除问题。该问题只可能出现在读(反序列化)上,不能出现在写上。那么这种问题怎么破?
在解决此问题之前,我们得先对Java中的泛型擦除有所了解,至少知道如下两点结论:
- Java 在编译时会在字节码里指令集之外的地方保留部分泛型信息
- 泛型接口、类、方法定义上的所有泛型、成员变量声明处的泛型都会被保留类型信息,其它地方的泛型信息都会被擦除
此问题在开发过程中非常高频,有了此理论作为支撑,A哥提供两种可以解决本问题的方案供以参考:
方案一:利用成员变量保留泛型
理论依据:成员变量的泛型类型不会被擦除
@Test
public void test6() throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
System.out.println("----------读集合类型----------");
Data data = objectMapper.readValue("{\"ids\" : [1,2,3]}", Data.class);
Long id = data.getIds().get(0);
System.out.println(id);
}
@lombok.Data
private static class Data {
private List<Long> ids;
}
运行程序,一切正常:
----------读集合类型----------
1
方案二:使用官方推荐的TypeReference<T>
官方早早就为我们考虑好了这类泛型擦除的问题,所以它提供了TypeReference<T>方便我们把泛型类型保留下来,使用起来是非常的方便的:
@Test
public void test7() throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
System.out.println("----------读集合类型----------");
List<Long> ids = objectMapper.readValue("[1,2,3]", new TypeReference<List<Long>>() {
});
Long id = ids.get(0);
System.out.println(id);
}
运行程序,一切正常:
----------读集合类型----------
1
本方案的理论依据是:泛型接口/类上的泛型类型不会被擦除。
对于泛型擦除情况,解决思路是hold住泛型类型,这样反序列化的时候才不会抓瞎。但凡只要一抓瞎,Jackson就木有办法只能采用通用/默认类型去装载喽。
加餐
自2.10版本起,给ObjectMapper提供了一个子类:JsonMapper,使得语义更加明确,专门用于处理JSON格式。
严格意义上讲,ObjectMapper不局限于处理JSON格式,比如后面会讲到的它的另外一个子类
YAMLMapper用于对Yaml格式的支持(需额外导包,后面见~)
另外,由于构建一个ObjectMapper实例属于高频动作,因此Jackson也顺应潮流的提供了MapperBuilder构建器(2.10版本起)。我们可以通过此构建起很容易的得到一个ObjectMapper(以JsonMapper为例)实例来使用:
@Test
public void test8() throws JsonProcessingException {
JsonMapper jsonMapper = JsonMapper.builder()
.configure(JsonReadFeature.ALLOW_SINGLE_QUOTES, true)
.build();
Person person = jsonMapper.readValue("{'name': 'YourBatman', 'age': 18}", Person.class);
System.out.println(person);
}
运行程序,正常输出:
Person(name=YourBatman, age=18)
✍总结
本文内容很轻松,讲述了ObjectMapper的日常使用,使用它进行读/写,完成日常功能。
对于写来说比较简单,一个writeValueAsString(obj)方法走天下;但对于读来说,除了使用readValue(String content, Class<T> valueType)自动完成数据绑定外,需要特别注意泛型擦除问题:若反序列化成为一个集合类型(Collection or Map),泛型会被擦除,此时你应该使用readValue(String content, TypeReference<T> valueTypeRef)方法代替。
小贴士:若你在工程中遇到
objectMapper.readValue(xxx, List.class)这种代码,那肯定是有安全隐患的(但不一定报错)
