-
有限事件集:E={i1,i2,…,im}
-
同时事件集:SEti 表示有多个事件在时间点 ti 同时发生
-
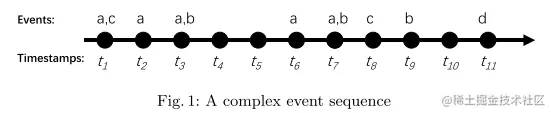
复杂事件序列:S=<(SEt1,t1),(SEt2,t2),…,(SEtn,tn)>,且该复杂事件序列是按照时间顺序排列,其中 SEti⊆E (额外规定:在复杂事件序列中,忽视那些没有事件发生的时间点)
-
发生:设存在一个复杂事件序列 S=<(SEt1,t1),(SEt2,t2),…,(SEtn,tn)>,某个情节 α 在事件序列 S 中的某个时间段 [ts,te] 发生,其中 Xi⊆SEi (子集关系)
-
发生集:occSet(α) 表示情节 α 在 S 上的所有发生时间段
-
情节:情节 α 是一组非空有序同时事件集合,α=<X1,X2,…,Xp>,其中 Xi⊆E
-
并行情节:包含单一事件(single event)集合(含有多个)的情节称为并行情节(parallel episode)
-
串行情节:每个事件集只有一个事件的情节称为串行情节(serial episode)
-
支持度:sup(α)=∣{ts∣[ts,te]∈occSet(α)}∣,即情节 α 在事件序列 S 上有多少次发生
-
频繁情节挖掘:在指定的发生时间窗口中,在复杂事件序列 S 中挖掘那些支持度大于阈值的情节 α
-
top-k 频繁情节挖掘:在频繁情节挖掘的基础上取消设置阈值,改成通过 top-k list 对阈值进行自增
-
局部列表:在第一次计算一元事件的支持度来提升阈值后,删除那些低阈值的事件,剩下的频繁事件组成局部列表(Location List,垂直结构)locList(e) 表示为事件 e 在事件序列中的所有位置组成的列表,有 sup(e)=∣locList(e)∣
-
绑定列表:boundList(e)={[t,t]∣e∈SEt∈S′},其中 S′ 是经过阈值筛选后剩下的事件序列;复合情节ep 与 e 的系列扩展的绑定列表定义为 boundList(serialExtension(ep,e))={[u,w]∣[u,v]∈boundList(ep)∧[w,w]∈boundList(e)∧w−u<winlen∧v<w},其中 sup(ep)=∣{ts∣[ts,te]∈boundList(ep)}∣
因为 EMMA 算法因为阈值设定原因,会忽略掉那些本可以与其它情节组成频繁情节的非频繁情节,所以TKE把阈值设置成1自增,即考虑了低支持度情节组合的可能。而且与top-k高效用项集挖掘一样,list结构同样利用堆实现优先队列结构。这篇算法比较简单,可以作为Episode pattern mining入门算法,了解一下并行情节和串行情节是怎么代码实现的。


