

不完美 Kubernetes Storage:Volume, PersistentVolume, PersistentVolumeClaim, Provisioner, StorageClass, VolumeClaimTemplate and StatefulSet - Part 2
回顾
在 part1 中,我们已经熟悉了Docker的以下概念。
- Storage Driver
- Volume
- Volume Driver Plugin
- Binding Mount
- Volume Mount
Kubernetes Storage中的Volume概念与Docker Storage中Volume的概念是类似的。
Kubernetes Volume
我们先来看一个Kubernetes Volume的例子:
apiVersion: v1
kind: Pod
metadata:
name: random-number-generator
spec:
containers:
- image: alpine
name: alpine
command: ["/bin/sh", "-c"]
args: ["shuf -i 0-100 -n 1 >> /opt/number.txt"]
volumeMounts:
- name: data-volume
mountPath: /opt
volumes:
- name: data-volume
hostPath:
path: /data
type: Directory
这段代码的意思是:一个名叫random-number-generator 的pod,在自己内部运行了一个名叫alpine的container,这个container在运行的时候生成了一个0-100的随机数,例如56, 然后把生成的数字写入了container的/opt/number.txt 文件。 这个container在建立的时候先mount了一个叫做data-volume 的volume到自己的/opt目录。 因此这个随机数并不是写在了container内部,而是写在了这个volume上。至于这个volume到底是啥,alpine container并不知道,也不关心。 Volume的真实身份由pod负责,container并不参与。
那这个名叫data-volume的volume到底是啥呢?根据random-number-generator这个pod的描述,这个volume是一个hostPath,指向random-number-generator pod所在node的/data目录。
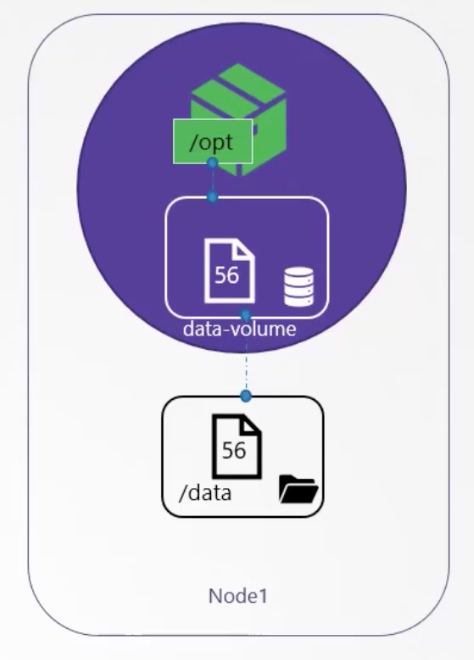
hostPath是Kubernetes Volume的一个类型,它和Docker Volume Driver Plugin中的local是一样的,都是将host目录包裹成volume的形式,然后被 mount到container上。
Kubernetes Volume的类型有点类似Docker Volume Driver Plugin,它也提供了包括云存储的很多类型。具体可以看这里。
这一切看起来都很美好,直到有新的需求出现,导致Kubernetes Storage的设计概念出现了非直觉和混乱。
Volume 遇到的挑战
Kubernets Volume的设计清晰、简单、易于理解并不易用错。但是这个设计概念在真正的工业化使用时有一个很大的问题:很难自动化。
其根本原因在于,volume在被mount的时候,是必须真实物理存在的,就是说Kubernetes无法让container去挂载一个没有被分配资源的volume。
我们知道Kubernetes的本职工作是大规模排程器,它需要管理非常多的nodes, pods, containers......等等。如果仅仅使用Volume这个工具,那么涉及到 storage的pods所需的volume都需要预先手动分配好,否则pods无法被自动建立并分配到nodes。而“预先手动分配好”这个动作,就完全背离了Kubernetes 设计的初衷。而引起这个问题的最主要原因,就是资源的获取分配与真实使用之间没有完全解耦。
那有什么好方法可以解决呢?
对于如何应对新的需求,设计师是很清楚的,一定是:增加间接层。
如果我们可以预先分配好一大片Volume Pool,然后让pod在有需要的时候,自动地从这个池子里面切一块拿走不就好了? 需要Storage的Pod只需要在建立的时候宣称 (Claim) 拥有池子里面的资源,而不用具体管资源是怎么分配的,不就解决了之前Pod建立时,资源必须物理真实存在的问题吗?这样通过增加一个“Volume Pool”的概念,将资源的分配与mount解耦开了,不就解决了自动化的问题了吗?
一般设计师都会这样想并且设计,但是非常遗憾的是Kubernets当初并没有这样做。如果有大神碰巧看到这篇小文,并且知道kubernets为什么当初没有这样设计,麻烦告诉我。Thanks in advance!
PersistentVolume 和 PersistentVolumeClaim
让我们来看看Kubernete当时是怎么做的吧。Kubernets在当时引入了两个概念,PersistentVolume和PersistentVolumeClaim,让我们看看当时Kubernets的开发团队是怎么想的:
A
PersistentVolume(PV) is a piece of storage in the cluster that has been provisioned by an administrator. It is a resource in the cluster just like a node is a cluster resource. PVs are volume plugins like Volumes but have a lifecycle independent of any individual pod that uses the PV. This API object captures the details of the implementation of the storage, be that NFS, iSCSI, or a cloud-provider-specific storage system.
A
PersistentVolumeClaim(PVC) is a request for storage by a user. It is similar to a pod. Pods consume node resources and PVCs consume PV resources. Pods can request specific levels of resources (CPU and Memory). Claims can request specific size and access modes (e.g., can be mounted once read/write or many times read-only).
PV 的定义里面需要注意的关键词是administrator,PVC的定义里面需要注意的关键词是user。这两段话的意思是,先由集群的administrator分配好PV, 然后user需要的时候进行PVC。乍看好像没有什么问题,很合理呀,但是需要明确的是,PVC和PV是一对一关系。重要的事情说三遍,一对一关系,一对一关系,一对一关系。当我搞明白PV和PVC的这种一对一关系时是感到很挠头的,这个设计真是相当的……只能说,“不一般”。
那么一对一关系到底是什么意思呢?
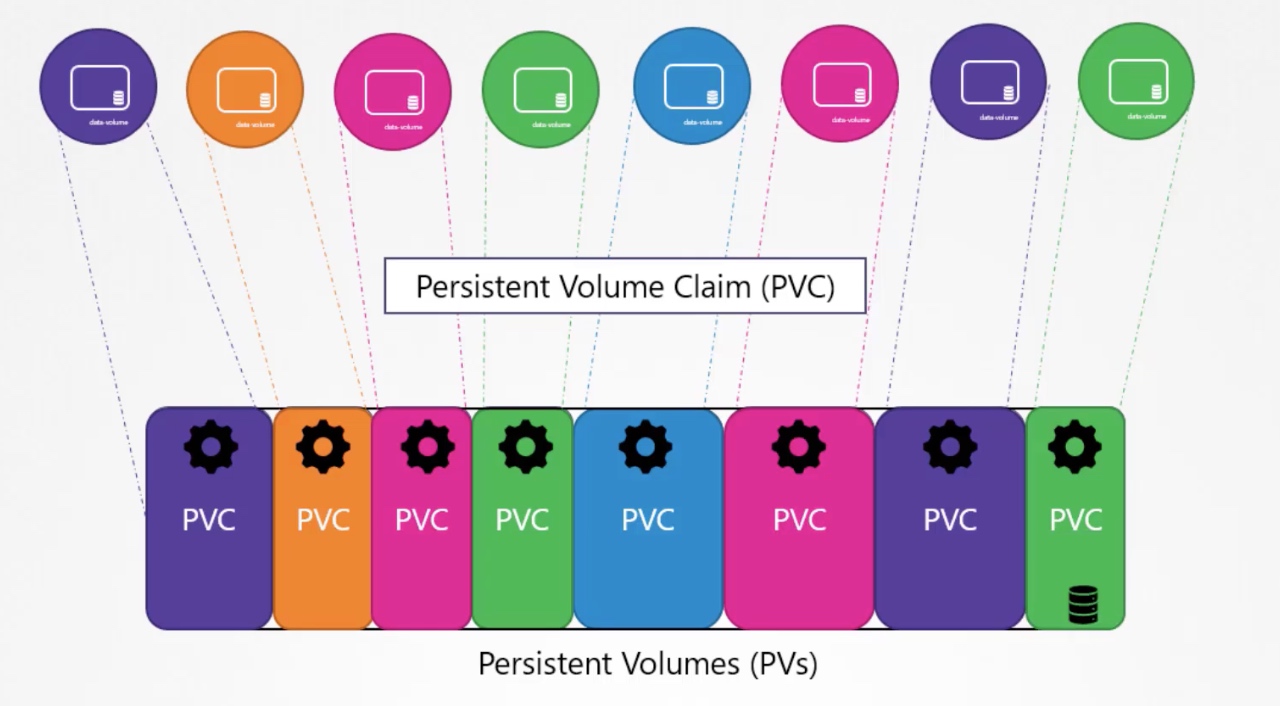
一对一关系的意思是,administrator预先分配一系列PV,使用者在使用的时候,会创建一个PVC,这个PVC会设定一些资源需求约束,当PVs中的某个PV如果可以满足这个约束,且这个PV没有被其他PVC所“占用”,那么这个PV会被分配到这个PVC。这个分配的过程被称为PVC到PV的Binding。PV一旦被某个PVC Binding,则这个PV和PVC就建立了一对一关系,这个PV就不能再被其他PVC Binding了。在默认情况下,Binding是Kubernets自动匹配完成的,不需要人为干预。
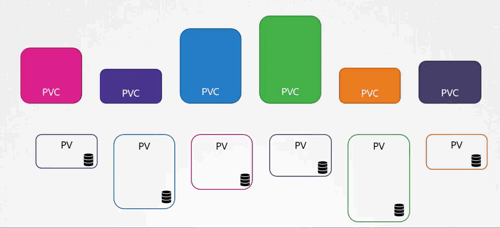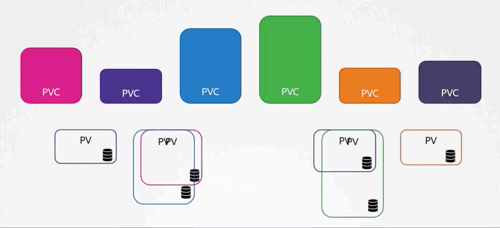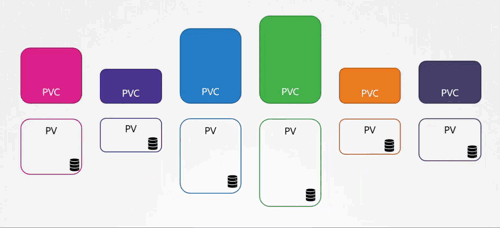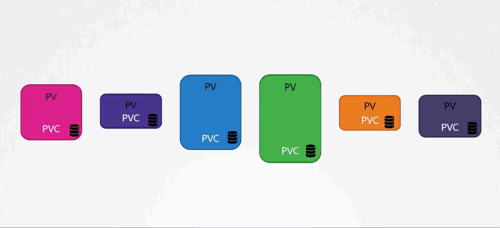
我们来看一个实际的例子。
# pv-definition.yaml
apiVersion: v1
kind: PersistneVolume
metadata:
name: pv-vol1
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 1Gi
awsElasticBlockStore:
volumeID: xxxx-xxxx
fsType: ext4
# pvc-definition.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-claim
spec:
accessModes:
- ReadwriteOnce
resources:
requests:
storage: 500Mi
# pod-definition.yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-frontend
image: nginx
volumeMounts:
- name: my-volume
mountPath: "/var/www/html"
volumes:
- name: my-volume
persistentVolumeClaim:
claimName: my-claim
一个名叫my-pod的pod,mount一个volume到自己的目录/var/www/html,这个volume来自于一个叫做my-claim的PVC。
这个叫做my-claim的PVC,需要最少500Mi空间的PV,Kubernetes系统左看右看,发现有一个还没有被Bind的PV,这个PV使用的是AWS Elastic Block Store,1Gi大小,ext4w文件系统,可以满足这个PVC的需求,所以被bind到了这个PVC。
如果系统中又有一个PVC需要500Mi,会出现什么情况呢?这个时候系统中没有多余的PV了,这个PVC只能等待administrator分配新的PV。
所以PV、PVC的设计概念,实际上添加了两个间接层,一个间接层PV用于隔离存储需求和实际存储物理类型,一个间接层PVC用于隔离Pod的Volume和PV。
这种设计机制导致了以下几个问题。
-
资源浪费。就像上面的例子,如果administrator事先分配了1Gi的PV,但是PVC只需要500Mi,如果这个PV被bind到这个PVC,会导致500Mi的浪费。如果另外一个名叫my-claim2的PVC需要500Mi,则这个my-claim2会被pending,直到满足my-claim2的PV被administrator所建立。
-
Administrator和user的角色分类事实上失败了。为了解决上面的问题,administrator会一直和user进行沟通,询问user需要分配PV的具体大小。最后administrator和user都会感到厌烦,所以干脆administrator授权给user自己分配PV自己用。
-
自动化失败。最终实质问题是,PV的粒度到底控制到哪个地步是好的?500Mi,1Gi?如果分配的都是500Mi的PV,那么如果PVC要求的是1Gi?如果PV分配的都是1Ti,嗯,估计只有云服务商高兴。
所以最终结果是,user在运行pod前,要么自己手动分配自己需要的PV,要么和administrator沟通,让administrator手动分配自己需要的PV。
好吧,这样和直接使用volume的情况并无不同。所以到目前为止,Kubernetes既没有解决Volume所遇到的挑战,还引入了PV和PVC这样两个间接层,人为增加了概念和操作复杂度。
那如何解决这个问题呢?聪明的设计师在面对新问题的时候肯定会采取合理的解决方案:增加间接层。
所以Kubernets引入了Provisioner和StorageClass这两个概念。
Kubernets Storage 概念总结
- Volume
- PersistentVolume
- PersistentVolumeClaim
