

今天来聊一聊内存问题,在前端这一块,内存一直是一个被忽略的问题,但是有过后端语言和C系语言开发者,对内存堆栈都是了如指掌的,本人编程启蒙于从事C#开发,很早就灌输内存栈堆思想,前端这一块其实也有很多资深程序员对内存掌控非常精准,但对于刚毕业或者刚接触JavaScript基础的开发者来说,内存栈堆使用是一个很陌生的领域,此文在这里将个人理解的方式来阐述前端内存掌控。
前端大部份的内存增长过快,一般都是滥用闭包 、迭代闭包 、 轮询异步代码造成的,这里我们一步一步慢慢解析,我尽量简单明了的解释。
function main(i) {
return function(n) {
console.log(i);
return i + n;
}
}
var cb = main(1);
console.log("function cb:", cb(2)); //function cb : 3
这是一个很常见的一个闭包方法,结果也很明显,首先我们从这个简单的闭包代码来开始解析,我们先思考,cb(2) == 3是如何运作出来的?很多人会不假思索的说 1 + 2 == 3!但是作为具有内存经验的开发者来说,思索的不是结果,而是cb & i & n的分配问题。
首先,i 和 n是基础值类型,前端中的值类型是被分配在栈中的,内存中具有栈和堆的说法,我们先不讨论内存栈和堆,后面在谈,现在只需要记住,前端的值类型在栈中。cb 是main函数的内部function引用地址,前端函数是第一等公民,在面向对象时, 函数也是作为对象的类型基石,所以cb是引用类型,cb则分配到内存堆中。
在上述表达中,很明显,cb是一个引用main函数的闭包环境和内部函数的引用块,i 和 n分别是闭包环境中的实参变量和函数形参变量,我们看下图来理解这句话。
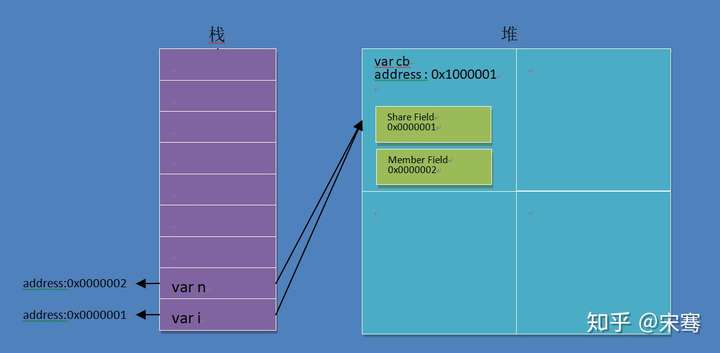
接下来,我们按上图的模型来改一下前端代码。
function main(i) {
return function(n) {
console.log(i);
return i + n;
}
}
var cb = main(1);
console.log(cb(2)); //console.log ->1 3
console.log(cb(3)); //console.log ->1 4
按我绘制你的内存模型图看,i是cb引用外部环境的公共作用域变量,与cb自己的内部成员字段进行运行,得出结果3和4,但是我们再思考,如何证明cb(2)和cb(3)都是在调同一个内存地址0x0000001(var i)呢?
function main(i) {
return function(n) {
console.log(i);
return (i += n);
}
}
var result = 10;
var cb = main(result);
console.log(cb(2)); //console.log -> 10 12
console.log(cb(3)); //console.log -> 12 15
console.log(result); //console.log -> 10
我们来看看这段代码在内存中的模型图,然后我在一步一步解析我的证明。
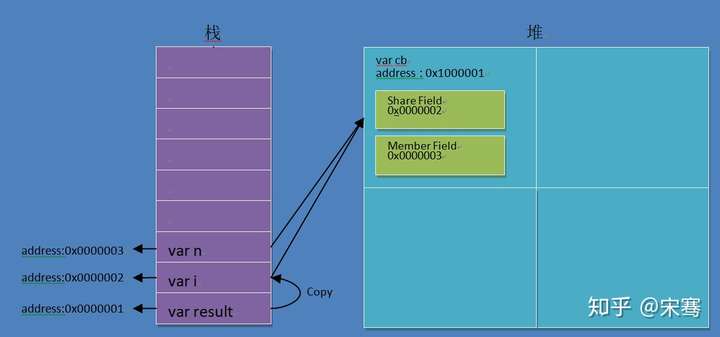
现在,我们来一步一步的解析上面代码在内存中运行的过程。
0x0000001 = 10;
//首先我们在全局中申请一个值内存空间 result = 10,假如0x0000001是result的内存寻址。
0x0000002 = Copy(0x0000001);
//我们在持行var cb = main(result)操作的时候,相当于把result内存寻址中的值共享给形参i变量,
//创建0x0000002地址,并且Copy(0x0000001)值。
0x1000001 = Heap(0x0000003) -> { 0x0000002 + 0x0000003 }
//main(result)会返回一个闭包环境给变量cb,0x0000002的即成为了0x1000001的作用域内共享变量,
//同时0x1000001具有特定行为寻址引用。
0x0000002 = Modify(0x0000002 + 0x0000003) -> Drop(0x0000003);
//cb(2),则对实参n进行申请了一个新的内存空间0x0000003,并且运算0x0000002 + 0x0000003寻址中的值,
//将结果重新赋值给0x0000002,在函数运行完成后,对0x0000003寻址进行回收。
Print(0x0000002);
//打印0x0000002寻址中的值。
0x1000001 = Heap(0x0000003) -> { 0x0000002 + 0x0000003 }
//cb(3)在次运行,0x1000001寻址中的Heap引用不变,但是上次cb(2)运行完后的实参n,
//也就是0x0000003是被Drop释放了,
//cb(3),会在次创建实参n,假如这次实参n内存地址还是0x0000003。
0x0000002 = Modify(0x0000002 + 0x0000003) -> Drop(0x0000003)
//cb(3)运行后,运算0x0000002 + 0x0000003寻址中的值,对闭包环境中的共享变量0x0000002在次赋值,
//函数运行完成后,回收寻址0x0000003。
Print(0x0000002)
//在次打印0x0000002寻址中的值。
Exit -> Drop(0x1000001);
//退出程序(关闭浏览器)后回收闭包寻址。
上面详细的推演了内存中运算过程,相信大家看出整个内存操作过程中,只有0x0000002的寻址没有被修改过,而实参变量n(0x000003)在每次运行cb()的过程中,都发生成寻址创建、回收等变化,假如0x0000002在cb()每次运行过程中,也发生了同样的寻址创建、回收,那么0x0000002 + 0x0000003运算结果肯定会出现0x0000002值丢失的情况,运算结果肯定不是我们看到的10 12 12 15,而是 10 12 10 13。
上述已经证明了我之前表述的cb(2) 和 cb(3)是调用同一个内存地址,到这里,大家应该能大概的了解内存使用栈和堆的基础认识,但是,这篇文章主要目的是解决前端内存暴增,异常增长等行为,上面的内容只是铺垫,下回更新,再来解析内存优化问题。
