

0x00 前提
本文主要面向熟悉Kong的读者,关于Kong的介绍、安装、使用不在这里赘述。 代码仓库地址:github.com/tzssangglas…
0x01 为什么有这个插件?
Kong开源版提供了限流插件,使用的是固定窗口算法,固定窗口存在惊群效应,即发生在窗口边界附近的流量突发会导致处理请求的速度增加一倍,因为它允许在短时间内同时处理当前窗口和下一个窗口的请求,并且新窗口会持续不可用状态直到新窗口结束。
Kong企业版提供了高级限流插件,支持滑动窗口算法,关于此插件的介绍,参考docs.konghq.com/enterprise/…
由于暂时买不了企业版,于是就想自己实现一个限流插件,支持滑动窗口,并且是分布式限流的,需要使用到Redis做集群缓存,考虑到大多数生产环境不会单机部署Redis,所以附带支持Redis-Sentinel。
0x02 滑动窗口算法
限流算法主要有桶类的算法和时间窗口类的算法。
令牌桶和漏桶算法比较适合阻塞式限流,比如一些后台 job 类的限流,超过了最大访问频率之后,请求并不会被拒绝,而是会被阻塞到有令牌后再继续执行。
对于像秒杀接口这种对响应时间比较敏感的限流场景,会比较适合选择基于时间窗口的否决式限流算法,其中滑动时间窗口限流算法空间复杂度较高,内存占用会比较多,所以对比来看,尽管固定时间窗口算法处理临界突发流量的能力较差,但实现简单,而简单带来了好的性能和不容易出错,所以固定时间窗口算法也不失是一个好的秒杀接口限流算法。(摘自高并发下的限流分析)
一般在网关上的限流算法不会选择令牌桶,漏洞之类的桶的算法。原因如上述,阻塞式限流意味着只要客户端不断开链接,这个请求最终还是会被执行,导致请求随着时间积压,网关处理不及时,响应变慢,后来的请求得不到执行。
而滑动窗口算法的问题在于占用内存较高,计算过程复杂,如果在网关上使用滑动窗口算法,会拖慢平均响应时间,相应的内存使用较高。
伪滑动窗口算法正好可以解决这个问题,关于伪滑动窗口算法,具体参考blog.cloudflare.com/counting-th…
这个算法在CloudFlare在生产环境中得到验证。虽然做不到像真正的滑动窗口算法那样精确,但我认为我们在做限流的时候,限流值也是估算出来的,当设置了一个限流值,并不代表只要流量稍微超过一点限流值,后端服务就会挂掉。所以在网关上使用的限流算法,可以允许可控的误差存在。使用限流的真正目的不是为了将流量精确地限制在某一个范围内,而是将流量控制在后端服务的承载能力之内。
简要介绍一下这个算法。
伪滑动窗口算法的真正核心在于使用来自前一个计数器的信息来推断请求速率的精确近似值,换种说法就是将前一个窗口的实际请求量作为权重,带入本次窗口请求量计算。随着本次窗口的时间流逝,前一个窗口实际请求量的权重越来越低。这也是保留了滑动窗口的精髓。
假设我在一个API端点上设置了每分钟50个请求的限制。请求计数器类似下图
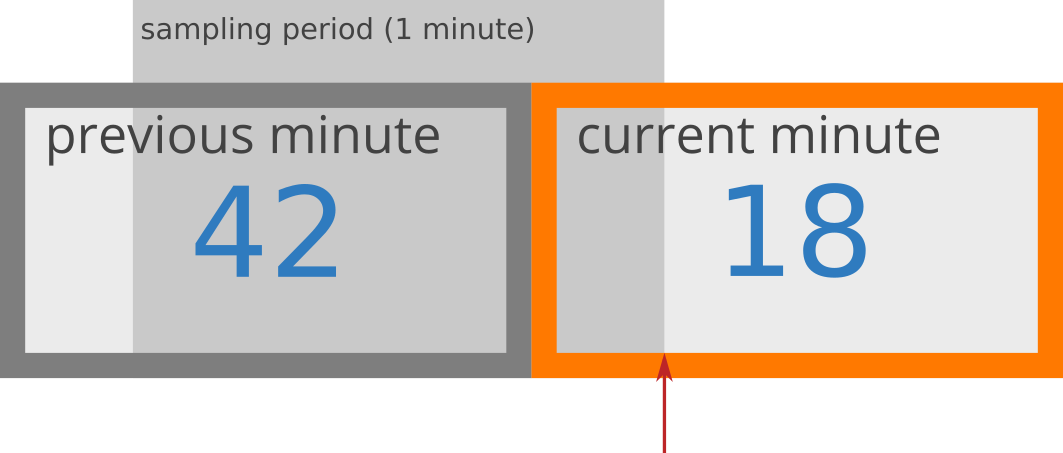
在这种情况下,我在15秒前启动的当前分钟内执行了18个请求,在前一分钟内执行了42个请求。基于这个信息,速率近似是这样计算的
rate = 42 * ((60-15)/60) + 18
= 42 * 0.75 + 18
= 49.5 requests
如果在接下来的一秒内再来请求,就会超过每分钟50个请求的限制。
该算法假设在前一个采样期间(可以是任何时间段)请求速率恒定,这就是为什么结果只是实际速率的近似值。
该算法作为OpenResty的第三方库,在github上开源,参考github.com/ElvinEfendi…
这个算法实现在单机上表现的有点问题,移植到分布式环境下这个问题变成一个小漏洞。
local function last_sample_count(self, sample, now_ms)
local a_window_ago_from_now = now_ms - self.window_size
local last_counter_key = get_counter_key(self, sample, a_window_ago_from_now)
--step2: 然后get,拿到上一个窗口的计数器
return self.store:get(last_counter_key) or 0
end
function _M.add_sample_and_estimate_total_count(self, sample)
local now_ms = ngx_now() * 1000
local counter_key = get_counter_key(self, sample, now_ms)
local expiry = self.window_size * 2 / 1000 --seconds
--step1: 先incr,本次请求在本窗口的计数器上+1,
local count, err = self.store:incr(counter_key, 1, expiry)
if err then
return nil, err
end
local last_count = last_sample_count(self, sample, now_ms)
local last_rate = last_count / self.window_size
local elapsed_time = now_ms - window_started_at(self, now_ms)
local estimated_total_count = last_rate * (self.window_size - elapsed_time) + count
return estimated_total_count, nil
end
这里先增加计数器的值(step1),然后估算本窗口的访问量(step2)。分别对应两个针对shared dict的操作,incr和get,这两个方法各自都是原子性的,是线程安全操作。但是这两个原子操作组合起来就不是线程安全操作了,在并发场景下,incr会先执行,导致当前窗口的计数器暴增,然后在估算本次窗口的请求量时,get到爆增后的计数器值,判定本窗口触发限流。
如果并发流量一直持续,导致爆增后的计数器被带入下一个窗口,或者在本窗口开始时,爆增导致本窗口的计数器超过估算的限流值,将直接判定触发限流,导致持续不可用状态。
我对这个漏洞做了修复
local function add_sample_and_estimate_total_count(counter_dict, limit_key, limit, window_size)
local now_ms = ngx_now() * 1000
--step1: 先get,拿到上一个窗口的计数器
local last_count, last_counter_key = last_sample_count(counter_dict, limit_key, window_size, now_ms)
local last_rate = last_count / window_size
local elapsed_time = now_ms - window_started_at(window_size, now_ms)
local counter_key = get_counter_key(limit_key, now_ms, window_size)
--step2: 然后get,并且 + 1,获取本窗口的计数器时算上本次请求
local count = store_get(counter_dict, counter_key) or 0
local estimated_total_count = last_rate * (window_size - elapsed_time) + count + 1
local should_throttle = estimated_total_count > limit
if should_throttle then
return should_throttle, counter_key, last_counter_key
end
local expiry = window_size * 2 / 1000
--step2: 最后如果未触发限流,则执行incr
store_incr(counter_dict, counter_key, 1, expiry)
return false
end
简要来说就是先get计数器的值,然后在估算请求量的时候+1,将本次请求也算上,决定是否触发限流,如果限流,则直接return,不会incr。只有在不触发限流的时候,才执行incr,即本次请求在计数器上+1。
这样改完之后,在并发场景下表现良好,计数器不会爆增,计数器值限制在限流值范围内。
0x03 同步策略
首先为什么需要同步策略?
如果是部署单节点的Kong,那么不存在同步问题。
但是我们在使用Kong的时候,基本都是部署Kong集群,这也是Kong提供的重要能力之一。那即使部署Kong集群,也可以选择本地限流,即在Kong实例里面限流,实例间的限流数据不共享。一般情况下看,这样不会有问题,但是如果Kong集群进行扩容和缩容,会导致全局限流值大小随着集群规模起伏,达不到限流的目的。限流的配置应当与Kong集群规模无关,而是与限流需要保护的后端服务的承载能力有关。
并且一般把Kong作为流量网关,不会是直接顶在流量最前面。在Kong的前面,应该会有一层LB,LB转发流量到Kong集群。LB的策略如果不是轮询,那么会存在流量倾斜,即把大部分流量导入Kong集群中的某一个实例。
以上这两个原因,是需要集群限流的场景。集群限流背后的问题,就是同步策略的选择。
Kong开源的限流插件也提供集群限流能力,可以把节点的数据同步到全局的数据存储区,数据存储区可以是Kong自身所使用的分布式数据库Cassandra,或者用户自建的Redis。但是这里有问题,集群限流模式下,会把每个请求都写入到基础数据存储区,然后读取。这样性能问题就会暴露出来,相当于每个请求都连一次数据库,那么数据库的性能瓶颈就是网关的性能瓶颈。关于这个插件在集群限流场景下存在的问题,参考:docs.konghq.com/hub/kong-in…
所以在进行同步策略选型时,考虑到不能让每个请求都触发连一次数据库,限流计算所需要的数据只从本地内存中读取,后台的定时任务定期同步内存中的限流数据到全局数据存储区,并且计算全局的限流数据和应当分配到每个节点的限流数据,计算结果更新到本地节点的内存中。
使用集中式数据存储的另一个缺点是在检查速率限制计数器时增加了延迟。不幸的是,即使检查像Redis这样的快速数据存储,也将导致每个请求的毫秒级额外延迟。
为了以最小的延迟做出这些速率限制确定,必须在内存中本地进行检查。这可以通过放宽费率检查条件并使用最终一致的模型来完成。例如,每个节点可以创建一个数据同步周期,该周期将与集中式数据存储同步。每个节点会定期为它看到的每个使用者和窗口将计数器增量推送到数据存储区,这将自动更新值。然后,该节点可以检索更新的值以更新其内存版本。群集中各节点之间的收敛→发散→重新收敛的循环最终是一致的。

节点收敛的周期性速率应该是可配置的。当流量分布在群集中的多个节点上时(例如,坐在循环平衡器之后),较短的同步间隔将导致较少的数据点分散,而较长的同步间隔则对数据存储区造成的读取/写入压力较小,并且开销较小在每个节点上获取新的同步值。(摘自How to Design a Scalable Rate Limiting Algorithm)
这种策略必然存在延迟和不准确,但是我认为为了性能,可以容忍。限流本身也不是为了精确控制流量,只要控制在设置的流量水位线浮动范围内即可,过于精确的控制必然导致计算复杂和存储复杂。
在进行全局限流数据和节点限流数据的重平衡计算时,我直接选择了计算平均值,用全局数据/Kong节点数量。虽然我觉得同步模型选择的没问题,但是这整个同步过程和计算模型我觉得还有改进空间。
欢迎探讨
0x04 参考
0x05 致谢
限流算法从Elvin Efendi的lua-resty-global-throttle 的源码修改而来。
