

简介:本文由阿里巴巴高级产品专家高旸(吾与)分享,主要介绍新一代Serverless实时计算引擎的产品特性及核心功能。
一.实时计算 Flink 版 – 产品定位与目标
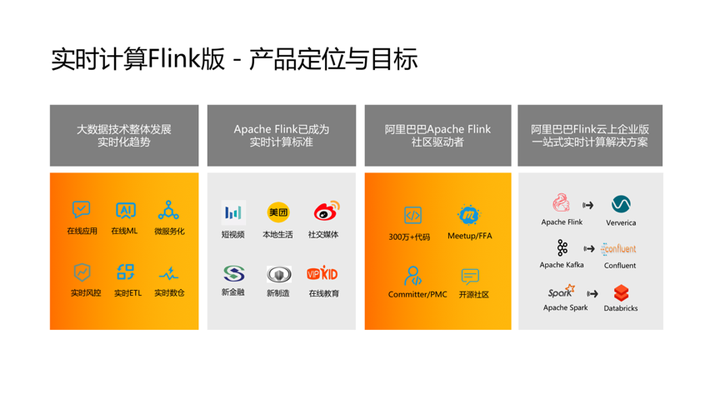
首先,介绍一下实时计算Flink版产品定位与目标。近些年来可以明显的看到大数据技术整体发展趋势是“实时化”。
-
在线应用,越来越多的业务场景和应用都逐渐演变为在线的应用,比如直播、短视频等都更强调实时化。
-
在线ML,机器学习也从传统的离线机器学习向在线机器学习演进。
-
微服务化,微服务现在也非常流行在算法层面做充分的解耦。
-
实时风控,如金融风控、内容安全的风控以及纯粹安全角度的风控等也在逐步发展为实时化。
-
实时ETL,实时数据的抽取、过滤、聚合,然后产生结果。
-
实时数仓,T+1的数据报表已无法满足客户当前需求,需要从整体包括实时链路增量数据的统一维度来做联邦查询,突出统一的报表,随之衍生出来的实时数仓。
从整个技术栈的发展情况可以看到实时化已经成为大数据技术发展的必然趋势,Flink主打的也是实时化场景。
其次,Apache Flink已经成为国内实时计算的事实标准。目前,阿里云实时计算 Flink 版已经在国家相关部门进行国标、院标的申请,如实时计算标准、融合计算标准,包括了流计算、批计算、ML、图计算等。可以看到很多国内主要的互联网公司都在使用 Flink 或阿里云实时计算 Flink 版。传统的金融公司、大型制造业等随着在线支付、5G的到来、车联网的引入,也开始探索引入大数据的实时化,采用 Flink 作为数据计算的核心引擎。
第三,阿里巴巴一直在主导Flink社区,积极推进Flink技术演进并全力投入Flink社区运营。2019年1月,阿里巴巴完成了对 Flink 创始团队,即Flink商业化母公司Ververica的收购。可以看到从2019年开始阿里云包括整个阿里集团开始对 Flink社区进行大量的投入。
-
贡献代码300万+行
-
举办 Flink 社区 Meetup 并引入 Flink 品牌大会 Flink Forward
-
全球最大的 Flink Committer / PMC 团队
-
开源社区的引导者
第四,从当前主流的计算引擎来看,每款开源产品背后都有一家商业化公司为其提供支撑。像Databricks与开源Spark, Confluent与开源Kafka关系类似,阿里云实时计算Flink版是开源Flink的商业化品牌,为企业及客户提供一站式实时计算商业化解决方案及云上SLA保障。
二.实时计算 Flink 版 – 产品功能介绍

接下来主要介绍实时计算Flink版的核心产品功能。Ververica Platform源自于德国Apache Flink创始团队,是一个非常成熟的、稳定的,经过海外多年企业级客户使用和打磨锤炼的商业化产品。今年被引入到中国地区做商业化落地,它主要分为三个部分:
1.开发模块
-
SQL开发平台:近些年,大数据开发逐渐SQL化,从商业分析师到业务人员都可以通过SQL快速介入到业务逻辑的开发处理,极大提升了效率并且节省了人力。
-
Job作业全生命周期管理:从作业的提交到停止,整个生命周期上传下载,都可以进行管理。
-
图形化 Metrics:开源社区的Flink提供的监控指标相对较少,而商业化产品做了大量的埋点,可以看到很细腻的指标。
-
丰富的Connectors:支持数据转变成实时化,充分挖掘数据资产,可以做更多的分析,激活商机促成转化。
2.运维模块
-
全链路监控报警:对于公司包括银行,全链路的监控十分重要。尤其是上了生产系统以后,对全链路的指标监控报警要求极高,也是 Ververica Platform非常重要的功能之一。
-
OIDC & RBAC:权限认证,从互联网行业向或传统行业来看,深度上云时传统企业对权限的管控、访问管理要求严格,OIDC & RBAC可完全匹配金融或者银行、保险公司的要求。
-
智能化配置调优:配合SQL开发平台,使用智能化调优的功能可自动通过内置的规则引擎帮助客户调整一些主要配置参数,使作业的资源配置或资源消耗达到最优性价比。 既能够省资源,又能够高效地完成作业。
-
弹性资源管理:从作业task manager到job manager,做资源的弹性管理,即客户负载较高的时候,可以申请更多资源;负载低的时候可以释放多余的资源,提高资源利用率,节省成本。
3.性能
-
SQL引擎优化:与开源 Flink 相比,商业版的SQL更加强大。
-
执行引擎的优化:专业的 Runtime 团队对网络和shuffer部分进行持续优化。
-
存储引擎优化:商业版的Gemini存储引擎在一些标杆的客户现场的做过验证和测试,整体上商业版Flink的性能是开源Flink性能的三倍。
4.底座
实时计算Flink版可以基于整个阿里云计算平台的EMR平台,也可以基于K8S容器平台,包括最新的按量计费Serverless底座等,基于安全容器隔离,弹性伸缩能力更强。
三.实时计算 Flink 版 功能使用详解
1.SQL 集成
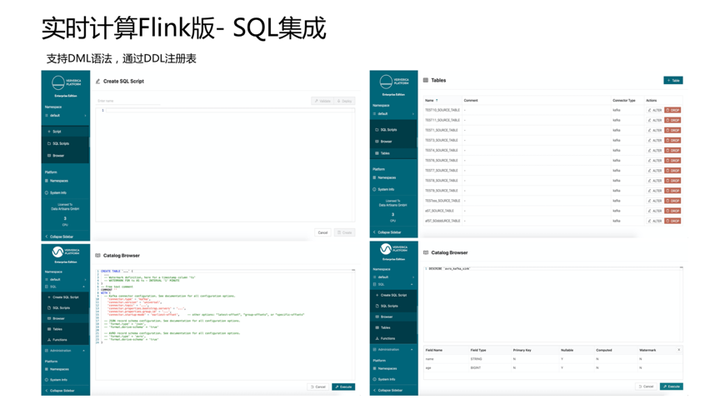
大数据处理的交互界面,当前业界普遍的共识或倾向是SQL。SQL整体更简单,门槛更低,数据分析师、业务人员可以快速上手,大幅度提高人效和开发效率。
上图绿色界面,是德国团队开发的Ververica Platform,整体界面风格简洁直接,没有过多繁杂冗余的交互。目前Ververica Platform提供丰富的SQL语义支持,包括支持DML及DDL等完整的SQL语义。
2.DataStream 作业管理

Ververica Platform支持各种作业提交方式。有标准模式及高级模式。在提交的过程中可以灵活选择各种参数及配置。目前Ververica Platform支持各种内核,既可以支持开源内核(例如:开源Flink v1.10、Flink v1.11以及未来的开源版本),也支持商业化内核(例如: Ververica Runtime) 。当然商业化内核在性能和功能上有更多的插件化增强,可实现对客户作业的完美兼容。
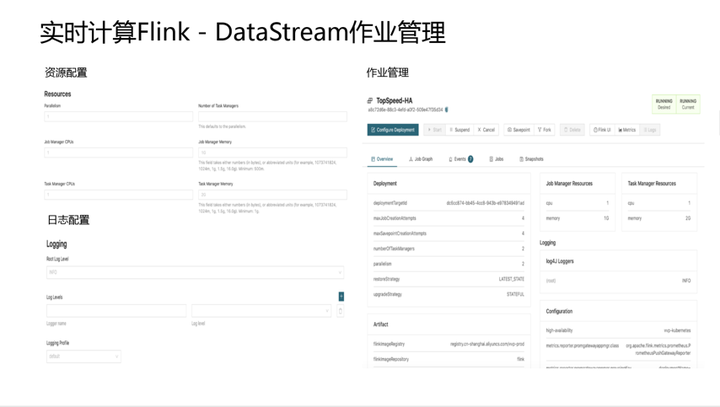
这部分主要是参数配置:资源配置和日志配置,还有作业管理。
3.自动调优Auto-Pilot
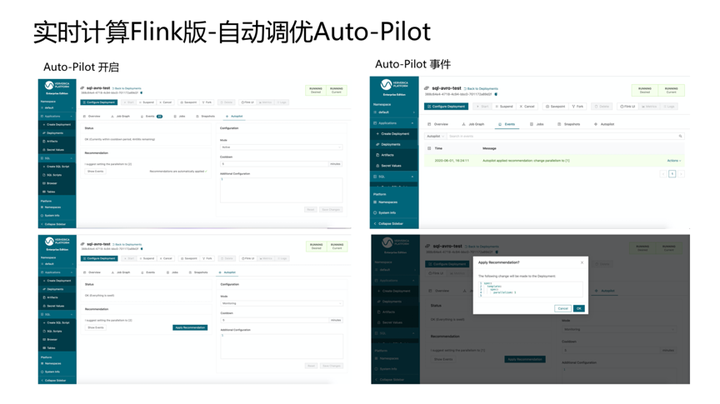
Auto-Pilot可以针对SQL、DataStream的作业,自动打开Auto-Pilot功能,可以在系统中自动帮客户调整并发度、CPU使用量、内存使用量等。
4. UDF管理
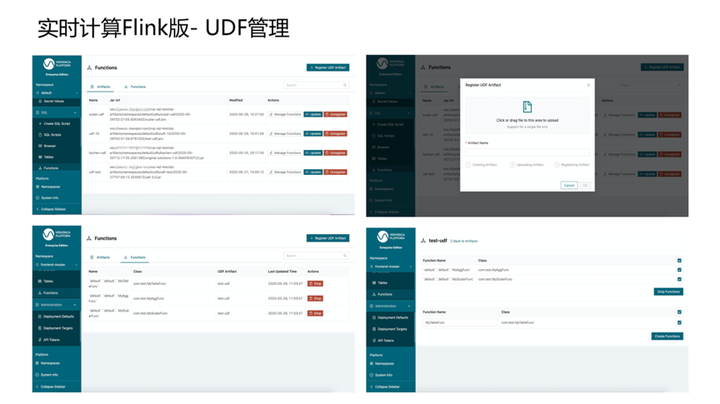
通常情况下UDF配合SQL可以实现客户80%的场景。当然客户可能还有其他比较复杂的场景(例如:自定义窗口,自定义connector等),需要通过基于DataStream API的代码开发作为补充。
5. Metrics监控
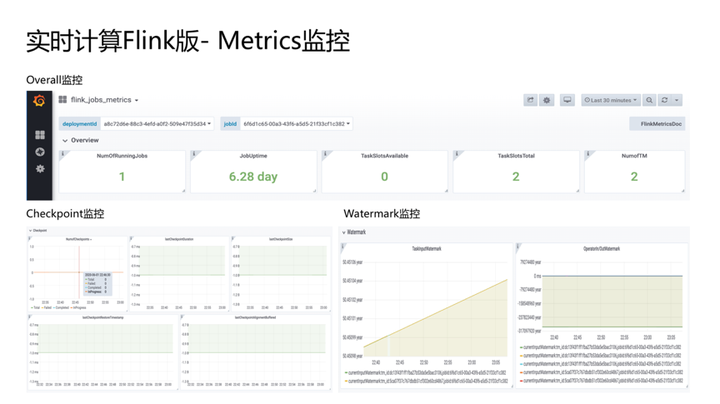
Metrics监控是很多客户关注的部分,尤其在生产环境中。在线业务越敏感,对指标的监控要求更高。Ververica Platform 的监控提供了非常丰富的维度,包括Overall监控、Checkpoint监控、Watermark监控、网络监控、CPU监控、JVM监控、IO监控等。
6.丰富的上下游支持
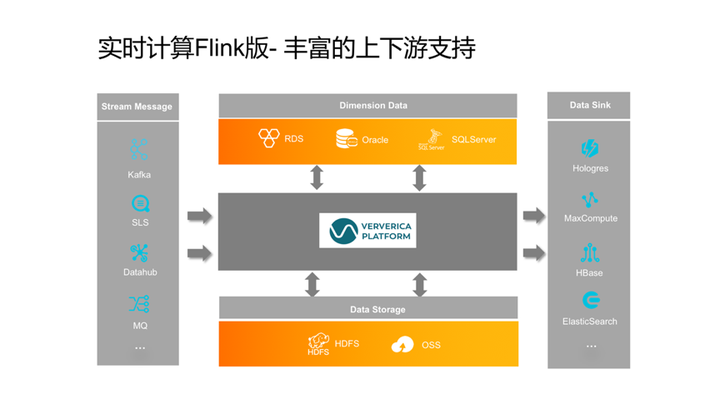
实时计算Flink版支持丰富的上下游,包括Stream Message、Dimension Data、Data Storage、Data Sink。阿里云实时计算Flink版是中间的计算环节。目前,实时计算 Flink 版对云上的 Data Source、Data Sink以及开源的 Data Source、Data Sink都支持的比较好,使用起来都很方便。
四.实时计算 Flink 版 – 半托管及全托管服务介绍
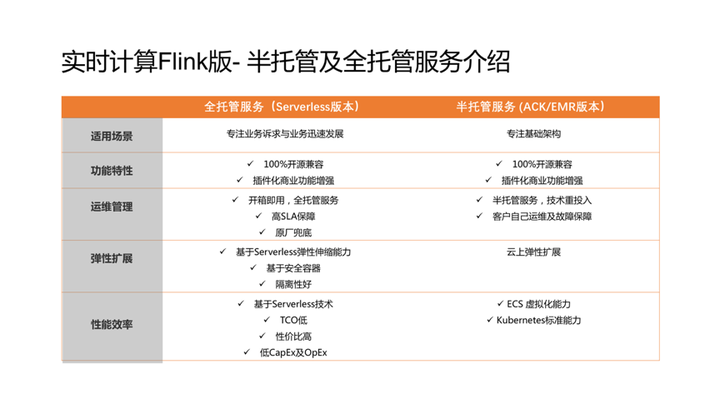
全托管服务、半托管服务其实顾名思义指是否有端到端的产品服务。包含产品服务的为全托管服务,不包含全部售后服务或技术支持服务的被称为半托管服务。现在两种产品形态阿里云实时计算 Flink 版都提供。
Flink的全托管服务和半托管服务的区别可以从五个维度对比,分别是适用场景、功能特性、运维管理、弹性扩展及性能效率。整体来看全托管服务TCO更低,性价比更高,同时还可以享受到原厂的高SLA服务。
五.实时计算 Flink 版 – 通用业务场景
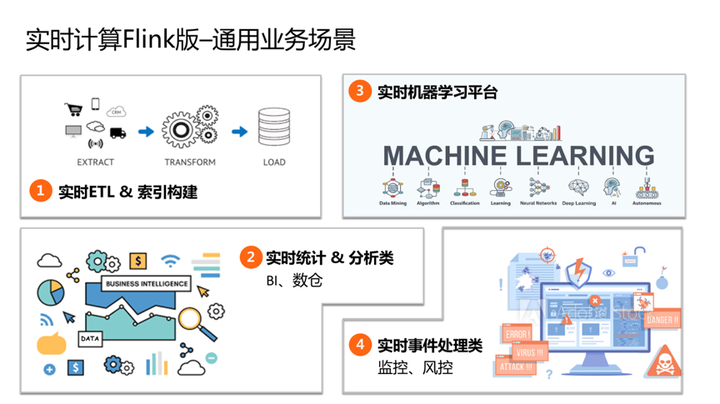
阿里云实时计算主打的通用业务场景主要有四个:
-
实时ETL & 索引构建, 主要通过实时计算完成数据的实时抽取、数据的实时聚合、清洗。比如:实时监控平台或实时大屏场景。
-
实时的统计和分析,比如:实时数仓场景。
-
实时机器学习。随着用户红利结束,传统T+1离线推荐引擎转化率效果越来越差,推荐引擎也在向实时化演进,通过实时样本拼接及实时增量模型提升转化率。
-
实时事件处理,主要是实时监控、风控场景。比如说在金融领域在线信贷实时金融风控场景;安全领域基于态势感知的大数据实时安全风控场景。
以下为目前阿里云实时计算 Flink 版一些比较典型的客户及行业分布。
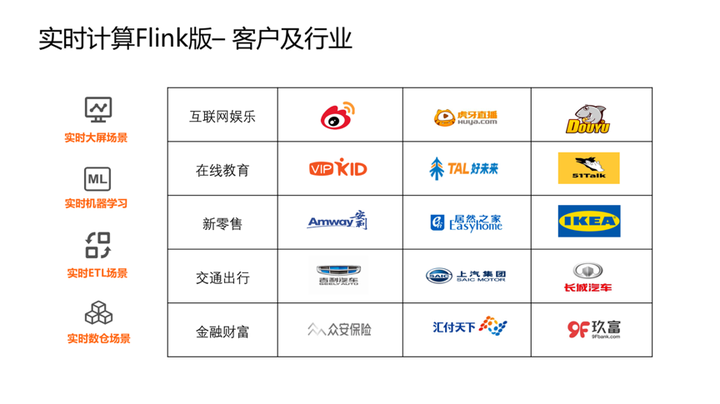
以下将介绍一些典型的实时计算应用场景及案例。
1. 实时计算 Flink 版 – 实时大屏场景
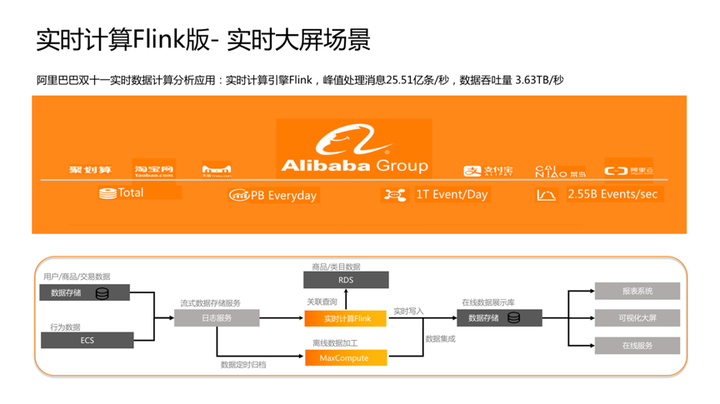
实时大屏是阿里云实时计算 Flink 版的典型场景,也是阿里巴巴集团内部从16年到至今一直在去跑的,2019年双11,实时计算 Flink 版巅峰处理的消息到达了每秒25亿条,数据吞吐量是2.63TB每秒。实时大屏数据链路主要分为两部分,一部分是用户的交易数据,一般都会存在传统关系数据库;另一部分是行为数据或行为日志(例如:用户浏览或点击日志),一般会存在ECS的日志系统里。通过Kafka及类CDC的数据抽取工具,将数据实时推送到Flink做实时的数据处理、聚合及清洗,然后实时存储结果数据做实时数据可视化展示。
实时大屏场景的应用非常广泛,比如 VIPKID的在线教育大屏,中央电视台春晚的大屏、去年国庆节的云上阅兵实时展示,包括58到家的生活大屏,以及建设银行、民生银行使用弗林克斯在做的中控平台的整个交易电路的的监控大屏等。
2. 实时计算 Flink 版 – 实时ETL数据处理场景介绍
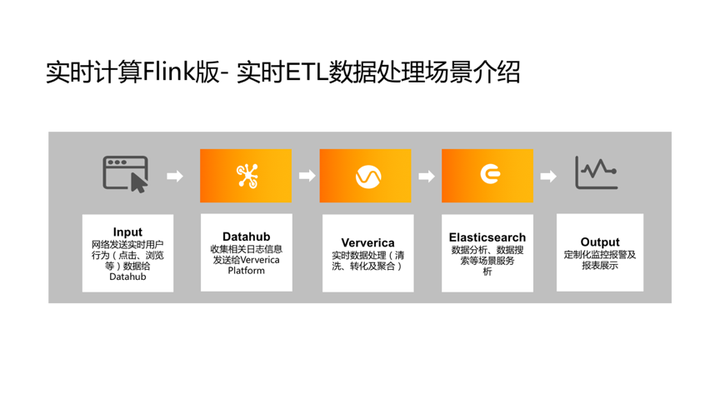
第二个是实时的ETL场景。例如:在线教育场景,在线教室1对1或1对多课堂中的学生行为,甚至家长在网站上的浏览购物行为,这些日志通过DataHub或Kafka传给Flink做实时的清洗、聚合。然后存储到诸如Elasticsearch的搜索平台里,客户、营销人员做一些搜索,或者由系统运维人员对整个链路做监控和报警。

VIPKID主打在线一对一视频课程,巅峰时可能每小时开课数量答3万多节,去年开始使用了实时计算Flink版,做到了将不同部门的日志通过MQ队列都抽取到实时计算Flink中,然后由统一部门进行计算、数据清洗,并将最终结果存储到不同的业务部门供其消费。
3.实时计算 Flink 版 – 在线机器学习场景介绍
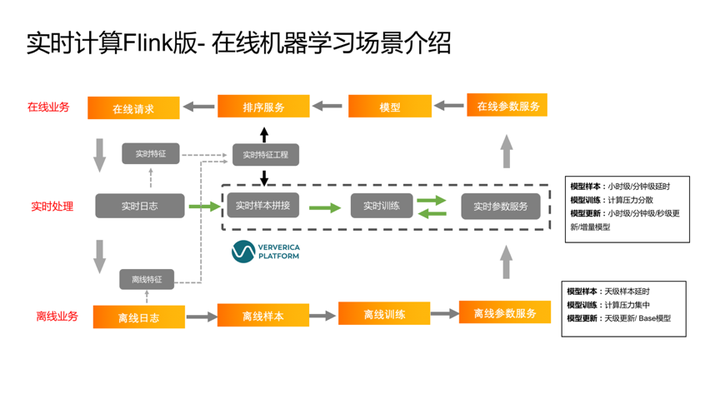
实时计算的在线机器学习应用场景,图中底部所示是传统的离线机器学习的处理链路:通过离线日志,做离线的样本生成,然后离线训练,然后再提供离线推荐服务。这是传统机器学习链路。随着业务的发展,用户(月活或者日活)到达一定数量级后,推荐的转化率就很难提高,就需要从时间维度去挖掘模型的价值。比如希望更快速的给客户推荐一些符合需求的结果,因此需要增加实时的在线机器学习处理链路。

以某社交媒体头部客户为例,目前为止该平台在线机器学习应用在多个业务场景,每天处理30亿到100亿条数据,计算的场景也比较复杂,如多流join,甚至有多媒体的计算。可以看到在整个在线机器学习中,使用实时计算 Flink版作为计算引擎后转化率效果提升明显,在线的模型效果比离线的模型效果提升了8%左右。
4. 实时计算 Flink 版 – 实时数仓场景介绍
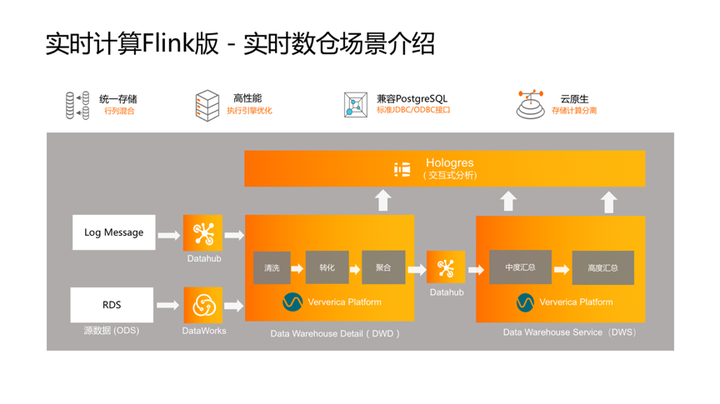
随着离线数据及实时数据不断的积累,实时数仓是当前的热点场景。很多互联网公司,包括很多的传统企业(例如:银行、保险公司)都有实时数仓的诉求。客户不仅想看到离线的数据的报表和结果,同时需要查看到实时写入数据的报表结果。如何解决数仓大并发实时写入,实现流批一体、行列混合存储及存储计算分离架构,如何基于联邦查询提供one service的企业级统一出口是近期行业内技术演进的焦点。
六.实时计算 Flink 版 – 实时数据处理链路 Demo
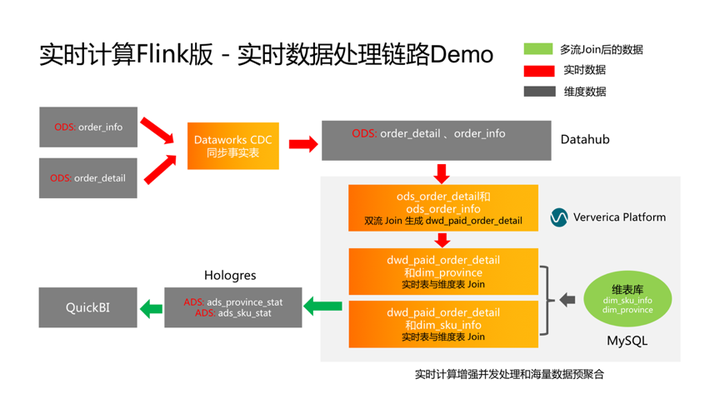
互联网公司的数据天生具有“实时化”的属性,本能的会将数据、日志通过类Kafka的消息引擎做收集然后通过实时计算Flink版做处理。但传统企业(例如:车企、制造商、零售企业),早期的数据资产都存储在关系型数据库中,数字化转型,业务在线化或实时化的过程中,如何激活这部分海量数据,把这部分所谓的静态数据实时化,充分挖掘企业海量数据资产的价值,就成了关键。
今年可以看到很多传统企业通过数据中台项目做数据源的改造(本质是为了实时化做准备)。本Demo主要展示了从数据源到数据抽取(激活静态数据)再到数据的实时处理(双流Join及流表Join)然后再到实时数仓的落地和交互分析查询及实时数据可视化展示,端到端的链路来演示全链路的实时数据处理的流程和场景。
七.Serverless 全托管 Flink – 免费测试
目前基于全托管Flink正在做免费测试,大家都可以去公测地址免费申请。一般客户使用云上服务有几个顾虑。
-
第一、觉得半托管没有服务、没有兜底、没有保障,全托管服务其实都可以解决。
-
第二、觉得虽然全托管服务解决了售后的问题,但是可能价格有时候偏贵。
利用serverless最新技术,按量计费和弹性扩展模式,既可以保证客户对性价比的要求,也可以保证客户对兜底的诉求。希望有更多的客户,更多感兴趣的开发者可以去长期试用。大家可以体验一下,发现问题也可以及时反馈,我们会不断的改进和优化。
作者:高旸(吾与),阿里巴巴高级产品专家
[原文链接](https://developer.aliyun.com/article/769715?utm_content=g_1000172111)
本文为阿里云原创内容,未经允许不得转载。
