一、方法介绍
- 关联规则(Association Rules):反映一个事务与其他事务之间的相互依存性和关联性。关联规则是无监督的机器学习方法,用于知识发现而非预测,关联规则的学习器无需事先对训练数据进行打标签,缺点是很难对关联规则学习器进行模型评估,一般都可以通过业务经验观测结果是否合理。
- 应用:关联规则主要用来发现Pattern,典型的关联规则发现问题是对超市中的购物篮数据(Market Basket)进行分析,通过发现顾客放入购物篮中的不同商品之间的关系来分析顾客的购买习惯。当然其他类似于购物篮交易数据的案例也可以应用关联规则进行模式发现,如电影推荐、约会网站或者药物间的相互副作用。关联分析的结果可以用于市场规划、广告策划和分类设计等。
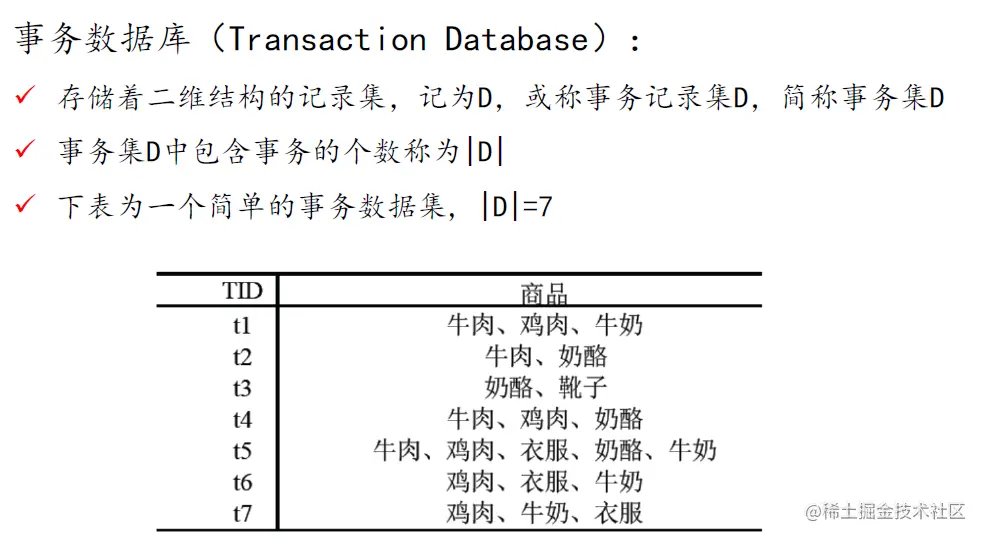
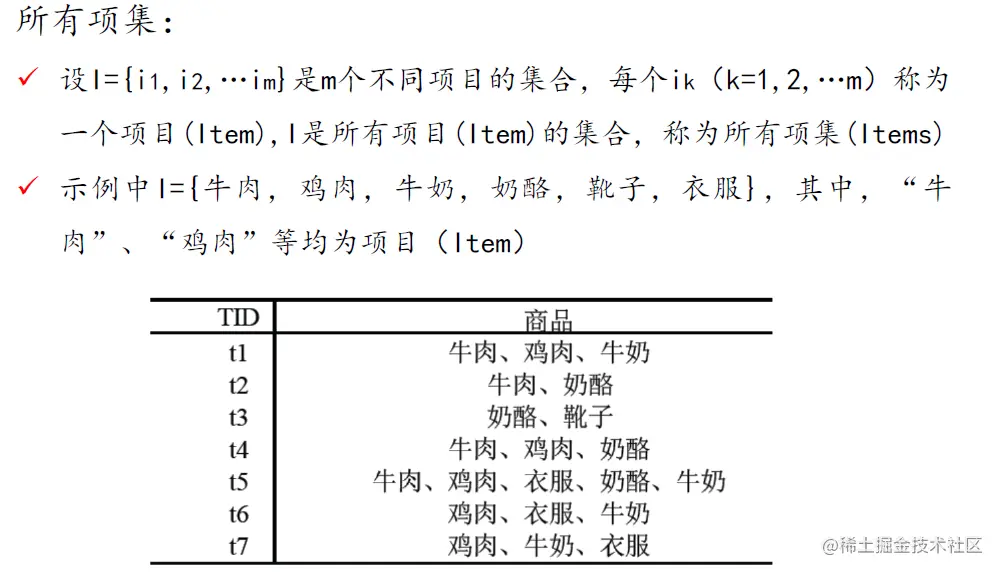











二、算法流程

三、Python代码实现
import mlxtend
import pandas as pd
import matplotlib.pyplot as plt
from mlxtend.frequent_patterns import apriori, association_rules
import warnings
warnings.filterwarnings("ignore")
dataset = [['Milk', 'Onion', 'Nutmeg', 'Kidney Beans', 'Eggs', 'Yogurt'],
['Dill', 'Onion', 'Nutmeg', 'Kidney Beans', 'Eggs', 'Yogurt'],
['Milk', 'Apple', 'Kidney Beans', 'Eggs'],
['Milk', 'Unicorn', 'Corn', 'Kidney Beans', 'Yogurt'],
['Corn', 'Onion', 'Onion', 'Kidney Beans', 'Ice cream', 'Eggs']]
from mlxtend.preprocessing import TransactionEncoder
te = TransactionEncoder()
te_ary = te.fit_transform(dataset)
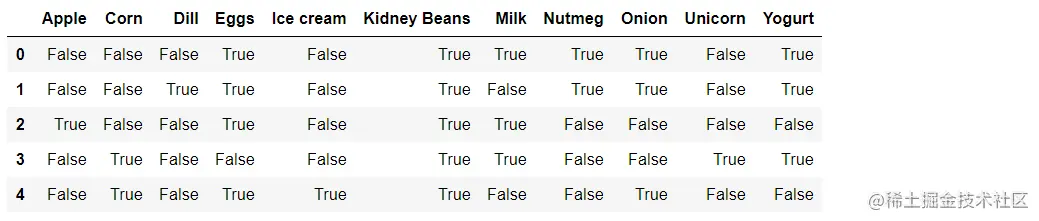
df = pd.DataFrame(te_ary, columns=te.columns_)
df
apriori(df, min_support=0.6)

apriori(df, min_support=0.6, use_colnames=True)
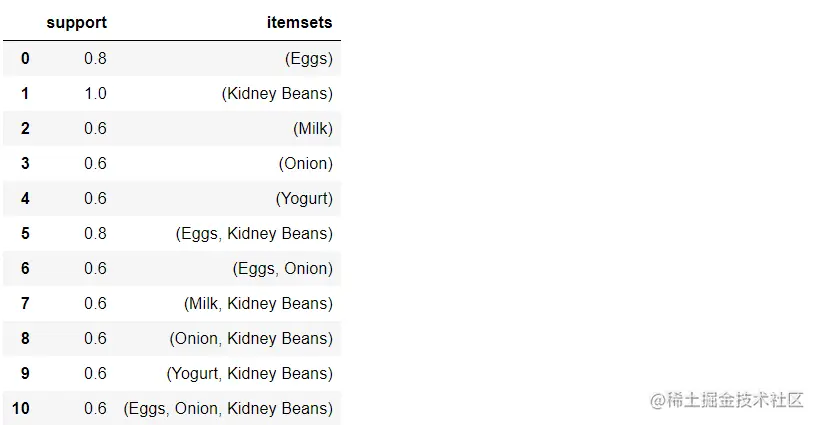
frequent_itemsets = apriori(df, min_support=0.6, use_colnames=True)
frequent_itemsets['length'] = frequent_itemsets['itemsets'].apply(lambda x: len(x))
frequent_itemsets
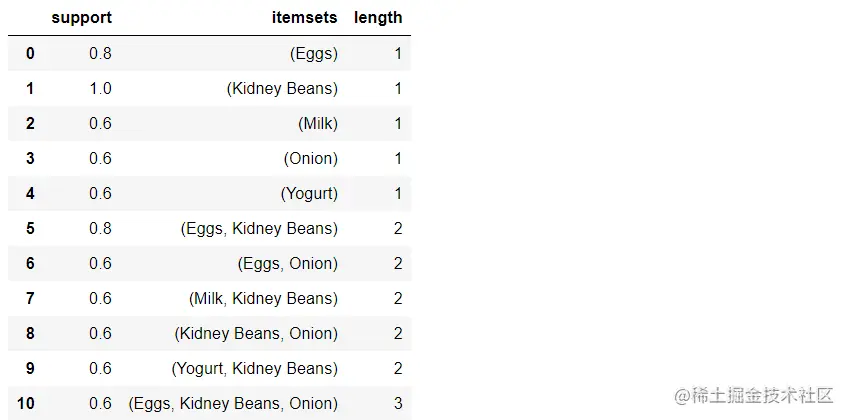
frequent_itemsets[(frequent_itemsets['length'] == 2) & (frequent_itemsets['support'] >= 0.8) ]#选择项集长度为2,支持度大于0.8的
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
dataset = [['Milk', 'Onion', 'Nutmeg', 'Kidney Beans', 'Eggs', 'Yogurt'],
['Dill', 'Onion', 'Nutmeg', 'Kidney Beans', 'Eggs', 'Yogurt'],
['Milk', 'Apple', 'Kidney Beans', 'Eggs'],
['Milk', 'Unicorn', 'Corn', 'Kidney Beans', 'Yogurt'],
['Corn', 'Onion', 'Onion', 'Kidney Beans', 'Ice cream', 'Eggs']]
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
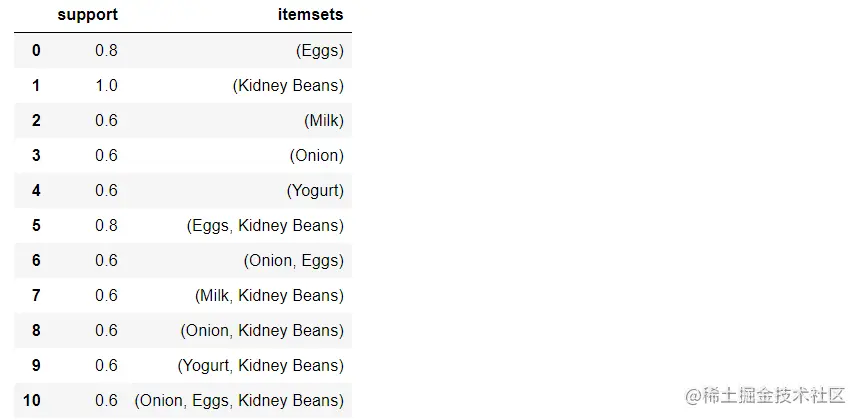
frequent_itemsets = apriori(df, min_support=0.6, use_colnames=True)
frequent_itemsets
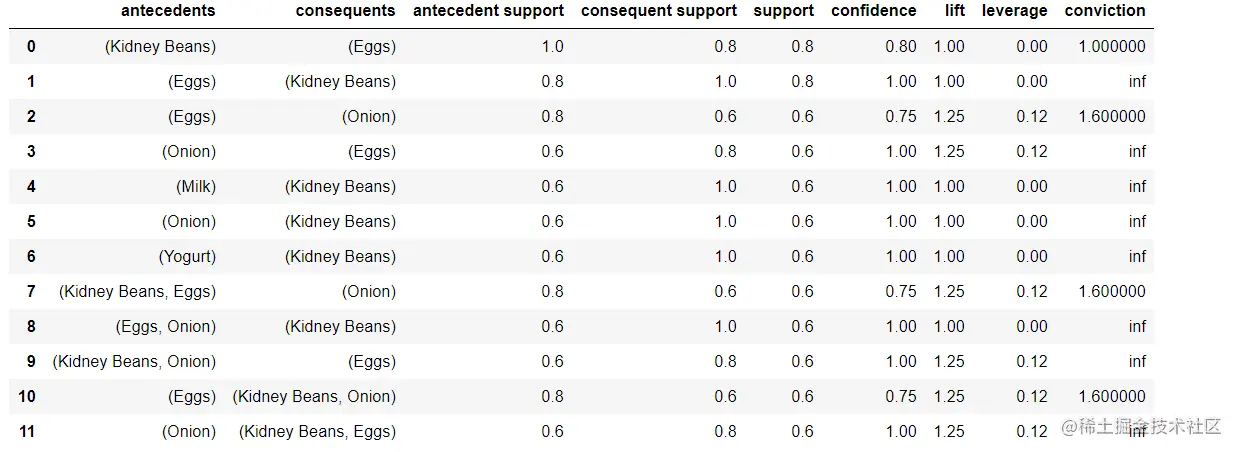
from mlxtend.frequent_patterns import association_rules
association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)
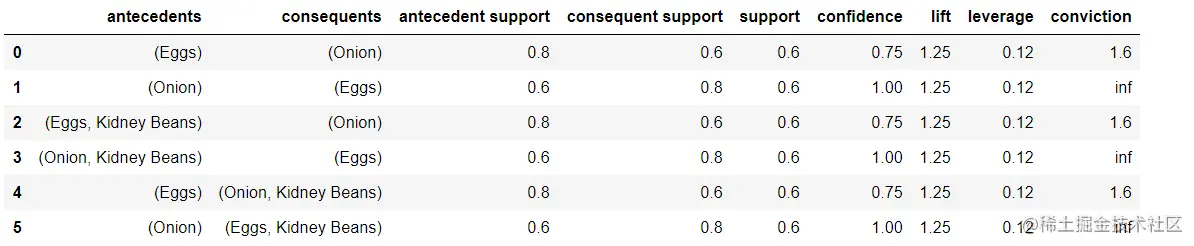
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1.2)
rules
rules[(rules['antecedent_len'] >= 2)&(rules['confidence'] > 0.75)&(rules['lift'] > 1.2)]



