

上篇“缺陷分析“链接:
前言
之前我讲解了Bug记录平台以及如何对Bug进行分析。基本是在单个Bug详细内容的维度单点进行分析和改进,为我们的项目、产品进行质量提升。
其实我们需要更高一层的思考问题,如何利用现有的数据评估我们的项目质量呢,这就涉及到关于质量度量的问题。
质量度量简单来说就是一个项目或一个产品经过一段时间产品、开发、测试的迭代周期后,如何评估这个产品质量是否能够满足预期。可能会包含很多方面,例如短期来看的软件运转的是否良好,是否存在一些潜在的风险或遗留问题,是否能够直接发布上线。长期来看就是整个流程是否存在优化的空间,开发人员在日常工作中是否疲于修改Bug,而不是做新功能或架构优化,是否一个功能反反复复修改才能满足业务需要等。这些很多的问题抛出来,如果没有一个直观、客观、可量化的质量度量的话,我相信再牛的测试人员也不可能给出这些问题的答案。
质量度量的起源
提到质量度量的概念,不得不说他的起源,
,他是美国航空航天局(NASA)的一个部门,该机构成立于1992年,作为其在戈达德航天飞行中心的系统可靠性和安全办公室的一部分。它的宗旨是“成为软件保证方面的卓越中心,致力于在GSFC为NASA开发的软件的质量和可靠性方面作出可衡量的改进”。该中心一直是关于软件度量、保证和风险管理的研究论文的来源。很多和测试相关的依据也都是依从该中心发表的论文。

该机构给出了Bug率和源码复杂度的一些关系,然后在这之上提出了关于质量的度量模型。由于它是基于C语言进行分析的,虽然可能具体的指标不一定适用于目前互联网大部分在用的Java、Go的后端语言。但是还是值得参考的,例如当时给出了的一些结论,每个函数代码行需要小于100行,圈复杂度需要小于10。据我所知,在华为等传统领域的IT公司还是作为一个强代码检查规范落地的。在SATC之后,也有很多国内外的组织提出来质量度量的一些维度和指标,例如SEI(软件工程研究所)、DARPA(美国国防部国际研究项目部)、IBM、HP等。例如以下维度的指标:
- 进度度量
- 需求度量
- 代码行度量
- 缺陷度量
- 测试覆盖率度量
基于一个20年前的收集数据可以看到,测试质量度量已经在行业内覆盖率很广了。
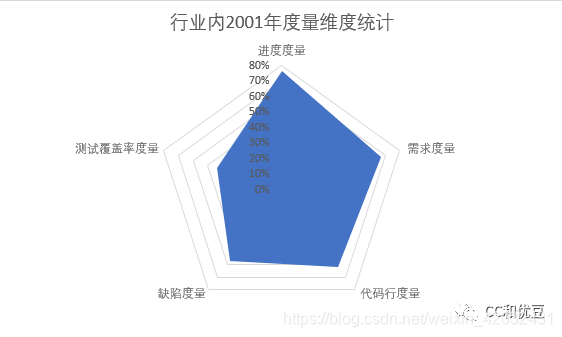
数据来源:根据KLCI 公司(面向全球高科技行业提供咨询服务)2001 年 4季度进行的 关于世界范围内软件度量实践活动的调查结果显示。
注:即使数据比较老旧,但是还是比较权威的,相信现在测试行业发展了这么多年,度量覆盖情况只可能更加全面。
这些维度每个都可以延伸出一个很大的话题,那么这次我们还是聚焦于缺陷度量的一些指标,以及缺陷度量能带来我们什么样的收益。
缺陷的质量度量指标
统计缺陷相关的度量指标,无外乎几个目的,想知道我们目前的项目或产品的质量怎么样。
可能对关心项目和产品的大佬来说,只是单纯主观的描述质量好或者不好肯定是不能被接纳的,因此需要量化一些指标。
细化来说大概分为上线前的过程指标以及上线后的结果指标。
- 上线后的指标简单粗暴,即产品上线以后有没有出事故或者线上Bug,对用户的直接影响是什么。那么事故和线上Bug也会定级、定严重程度,以方便衡量具体的质量影响,例如10个微小型的用户体验类Bug,对比一个影响SLA的线上事故。肯定是后者影响更大。
- 上线前的过程指标可能会比较多,例如测试人员本身发现的一些问题的个数和严重等级,这里体现出来测试过程是否充分以及代码本身还会不会有一些潜在的坑或者问题。以及问题个数跟开发工作量或者代码行数的占比。一般来说一个需求或功能代码量越大,工作人日占用越多,也代表他越复杂,因此可能引入的Bug也相对来说会多一些。当然这个也不是完全可靠,例如一个刚毕业的新开发人员跟资深开发架构师相比,个人的Bug率(Bug个数/工作人日)肯定不是同一个数量级的。因此很多人会互相调侃,你不是在开发功能,而是在开发Bug。
上述两个方面大概可以用以下几个指标来涵盖:
线上指标:
- 事故个数及等级:一般来说等级根据影响情况分为P0、P1、P2等。具体细节定义可根据项目、产品最核心价值来定,例如服务不可用时间、例如影响线上请求的数量等来定级。
- 线上Bug率:核心就是看线上发现的Bug等级和个数对应于某段时间开发出来的软件代码的占比关系。建议的算法,在某个时间周期内(半年或者三个月)线上Bug个数乘以对应的Bug重要等级对应的分值(例如Critical
10分、Major8分、Normal2分、minor1分)然后除以开发工作人日。 - 线上漏测率:分析一段时间内发现的所有线上Bug,如果跟测试过程强相关的,例如没有用例覆盖、或者有用例覆盖但是未执行,这种属于漏测问题,将漏测问题除以总的线上问题数,就可以得出线上漏测率。如果跟用例没有强相关,可能是设计层面或需求层面的问题、或者是运维或配置引入的不可测试出来的问题则认为非漏测。也有可能有另外一种定义,就是拿线上Bug除以线下Bug,以代表即使测出来这么多线上Bug,仍然有未评估到遗漏到线上的问题比例。这个指标最终是为了改进我们的测试过程质量,将测试用例设计弥补的更加完善,在不影响上线效率的情况下尽最大可能挖掘软件质量方面的Bug。
线下指标:
- 线下Bug率-服务维度:跟线上Bug率算法差不多,在某个时间周期内(半年或者三个月)线下Bug个数乘以对应的Bug重要等级对应的分值然后除以开发工作人日。如果不想算的那么繁琐,也可以单纯统计某个时间周期内服务或项目维度线下Bug的个数。如果线下Bug比较多,那么一定程度也代表了代码质量不佳,也很可能造成部分遗漏问题到线上。这个指标经过基线对比或观察一段时间的波动能反映出一个项目或产品的质量变化。
- 线下Bug率-个人维度:可以按个人的线下Bug个数乘以对应的Bug重要等级对应的分值除以工作人日统计,也可以统计某个时间周期内个人维度线下Bug的个数。可以小范围项目维度统计,用于横向对比,发布数据时需要考虑到开发者个人的情绪,也可以只面向项目的管理者发送该数据。
- 线下Bug跟测试类型或阶段的关系:根据线下Bug的发现阶段或标签可以分类统计个数,例如发现阶段可能包含功能测试、专项测试、演练验收、交付验收等。一个比较健康的项目测试活动应该是Bug逐步收敛,如果演练验收、交付验收发现的Bug反而比功能测试和专项测试还多,那么就要重点关注并改进。
质量度量如何落地
说了这么多缺陷方面的指标,也说了统计的一些规则,建议的公式等,那么如何降低质量度量的人工成本呢。统计周期和工具/平台都非常重要。
极端考虑,如果统计周期为一天,那么每天就会疲于收集和统计数据,对比效果也不好,因为很难说今天比昨天的度量数据变好了就说明软件质量就变好了,因为很有可能今天就没有在做测试执行的活动,或者今天运气比较差,一下子来了好几个线上Bug,也不能说明今天的软件质量就比昨天的差。建议线下的指标统计周期跟上线周期相关,例如有些服务一个月一个版本,有些一个月两个版本,或者一周一个版本,都比较合适作为度量数据拉取的一个时间周期。而线上的指标可以更加长一些,可以考虑跟绩效评估周期强相关,例如三个月或者半年为一个度量周期,可以更加有参考性,也可以将部分指标作为项目整体打分或者个人绩效的一些参考指标。
工具/平台,如果所有的统计工作都人肉完成,那么有两方面的弊端,一个是统计成本高,另外一个就是数据不完全可靠,有可能存在偏差。建议使用平台或者工具来完成统计。一方面需要源数据填写准确,基于Jira平台或者其他缺陷管理平台的字段要准确。另一方面平台和工具需要支持可以定时拉取数据以及人工触发拉取数据并且自动计划预设好的各种指标。
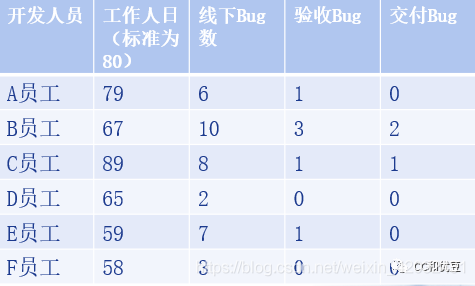
下面为一个使用工具定期拉取的线下指标数据的质量情况:

个人维度的质量情况
线上指标数据的质量情况(人肉统计):
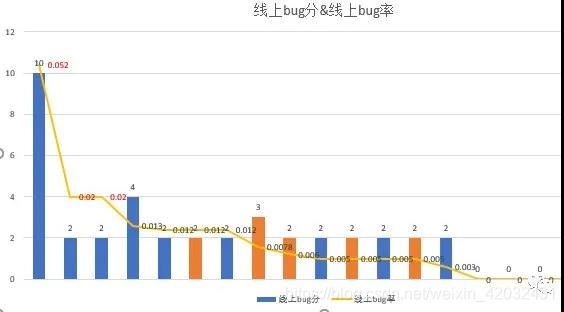
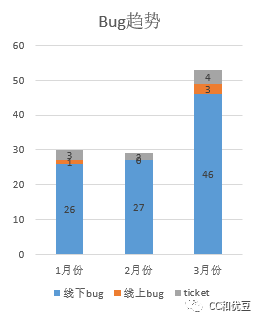
可以看到线上指标的意义在于横向项目对比,或者几个时间周期项目内的指标对比。
横向项目对比的意义在于样本数比较多的情况下,可以综合对比出哪个项目或产品在同样的周期内质量比较好。
项目内几个时间周期的对比在于经过一些测试活动的改进,质量是否有明显的提升或改变或波动。
由于线上指标收集频率比线下指标长一些,短期内可以接受人肉统计,长远来看尽量也是依赖工具和平台完成。
工具思路:脚本调用jira平台接口统计,然后根据Jira收集出来的源数据进行一些公式计算并按维度展示出来。
平台思路:例如我们公司的质量数仓架构如下所示,基于原始数据Jira以及其他元数据平台经过采集汇总,通过数据汇总、数据模型、维度数据等计算,提供给展示层快速筛选需要的关心的数据指标。
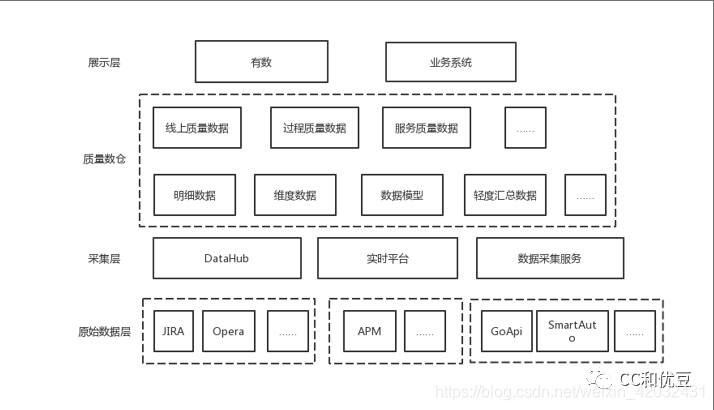
小结
本文介绍了质量度量的起源,在质量度量5类庞大的维度中间选择缺陷相关的指标进行详细拆解和分析,提供给需要参考的小伙伴们线上线下共计6个核心指标,并且根据质量度量落地方式来给出具体的例子。
看到这里的小伙伴,如果你喜欢这篇文章的话,别忘了转发、收藏、留言互动!
如果对文章有任何问题,欢迎在留言区和我交流~
最近我新整理了一些Java资料,包含面经分享、模拟试题、和视频干货,如果你需要的话,欢迎私信我!
最重要的是:
关注我!
关注我!
关注我!
(卑微求粉丝)
