一个需求是统计某一个组织每个月的工作汇报数量。有两张表结构如下:
diary日志表
CREATE TABLE `diary` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`content` text CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '日志内容',
`space_id` bigint(10) NOT NULL COMMENT '空间ID,冗余字段',
`user_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '创建者ID,(已包含多空间概念)',
`member_id` bigint(20) DEFAULT '0',
`user_name` varchar(50) NOT NULL DEFAULT '' COMMENT '用户名称',
`visible_range` int(1) NOT NULL COMMENT '可见范围:0:所有可见,1:部分可见,2:仅自己可见',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`record_status` int(1) NOT NULL DEFAULT '0' COMMENT '是否删除标识,1 删除,0正常 ',
`data_status` int(1) NOT NULL DEFAULT '1' COMMENT '是否删除标识,1 正常,0 草稿 ',
`source` int(1) NOT NULL COMMENT '回复来源 1android 2ios 3web 4微信',
`data_type` int(1) unsigned NOT NULL DEFAULT '1' COMMENT '1:日报,2:周报,3:月报,4:其他',
`version` bigint(20) DEFAULT NULL COMMENT '版本',
`gather` int(1) NOT NULL DEFAULT '0' COMMENT '是否是汇总日志 0:否 1:是',
`type_id` int(20) DEFAULT NULL COMMENT '模板表ID',
`type_name` varchar(50) DEFAULT NULL COMMENT '模板名字',
`old_diary_id` bigint(20) DEFAULT '0' COMMENT '旧版日志ID',
`read_count` bigint(20) DEFAULT '0',
`update_time` timestamp NULL DEFAULT NULL,
`diary_time` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `space_member_index` (`space_id`,`member_id`),
KEY `idx_space_id_create_time` (`space_id`,`create_time`),
KEY `idx_space_id_diary_time` (`space_id`,`diary_time`),
KEY `idx_template_id_space_id` (`template_id`,`space_id`),
KEY `idx_space_id_visible_range_create_time` (`space_id`,`visible_range`,`create_time`)
) ENGINE=InnoDB AUTO_INCREMENT=414221 DEFAULT CHARSET=utf8 COMMENT='日志表'
|
diary_visiable_range部门表
CREATE TABLE `diary_visible_range` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`diary_id` bigint(20) NOT NULL COMMENT '日志ID',
`user_id` bigint(20) DEFAULT '0' COMMENT 'memberId对应userId',
`user_name` varchar(50) DEFAULT '' COMMENT '用户名称',
`member_id` bigint(10) DEFAULT '0' COMMENT '开放平台memberId,供native选人用',
`space_id` bigint(10) DEFAULT '0' COMMENT '空间ID,冗余字段',
`team_id` bigint(10) DEFAULT '0' COMMENT '部门/团队/群组ID',
`team_name` varchar(200) DEFAULT NULL COMMENT '部门/团队/群组名称',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`data_type` int(1) NOT NULL COMMENT '1:部门,2:群组,3 团队,4:个人',
`group_id` bigint(20) DEFAULT '0',
`visible_type` int(1) DEFAULT NULL COMMENT '可见范围类型:0:上次选择包含,1:上次选择不包含',
PRIMARY KEY (`id`),
KEY `team_index` (`team_id`),
KEY `diary_user_data_type_index` (`diary_id`,`data_type`) USING BTREE,
KEY `idx_team_id_create_time` (`team_id`,`create_time`),
KEY `index_space_id_member_id` (`space_id`,`member_id`)
) ENGINE=InnoDB AUTO_INCREMENT=59897 DEFAULT CHARSET=utf8 COMMENT='日志可见范围表'
|
两张表的关系是:diary记录工作日志,diary_visiable_range 记录部门和工作日志的可见范围,即某一条工作日志可以给哪些部门或者团队可见。
下面看一下原始需求的sql查询:
SELECT team_id as teamId, DATE_FORMAT(d.diary_time, '%c') AS MONTH, count(*) AS num
FROM
diary d
JOIN
diary_visible_range v
ON d.id = v.diary_id AND v.data_type = 1
AND v.team_id in (143289) WHERE
d.space_id = 104242
and d.diary_time BETWEEN '2020-01-01' and '2021-01-01' AND d.data_status = 1
AND d.record_status = 0
GROUP BY
DATE_FORMAT(d.diary_time, '%Y-%m'),v.team_id
|
可以看到两张表是通过 diary.id关联,筛选条件是diary_visiable_range 表目标为team_id,在一年中的按月统计记录。
然后我们看下这个sql执行的时间是怎么样的?
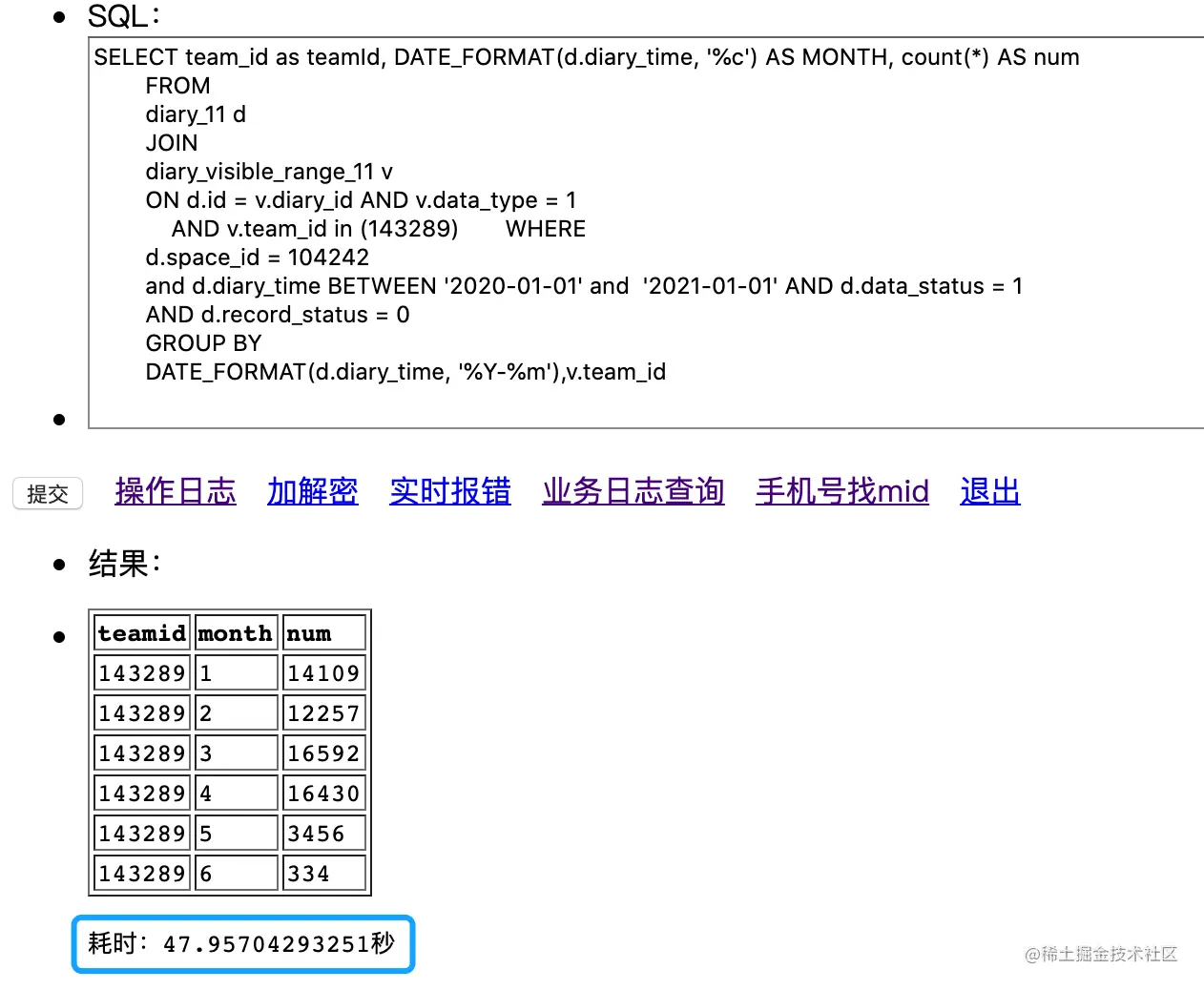
需要47秒,这么长的时间,http请求早已断开了链接。然后我们执行下explain,看下sql的执行情况:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|
| 1 | SIMPLE | d | ref | PRIMARY,idx_space_id_create_time,space_member_index,idx_space_id_diary_time,idx_space_id_visible_range_create_time | idx_space_id_create_time | 8 | const | 339992 |
Using where;
Using temporary;
Using filesort
|
| 1 | SIMPLE | v | ref | team_index,diary_user_data_type_index,diary_user_index,idx_team_id_create_time | diary_user_data_type_index | 12 | db_logger.d.id,const | 1 | Using where |
我们再回顾下explain每个字段的含义:
1,id:SQL查询中的序列号。
id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行。
2,select_type:查询的类型,可以是下表的任何一种类型:
| select_type | 类型说明 |
|---|
| SIMPLE | 简单SELECT(不使用UNION或子查询) |
| PRIMARY | 最外层的SELECT |
| UNION | UNION中第二个或之后的SELECT语句 |
| DEPENDENT UNION | UNION中第二个或之后的SELECT语句取决于外面的查询 |
| UNION RESULT | UNION的结果 |
| SUBQUERY | 子查询中的第一个SELECT |
| DEPENDENT SUBQUERY | 子查询中的第一个SELECT, 取决于外面的查询 |
| DERIVED | 衍生表(FROM子句中的子查询) |
| MATERIALIZED | 物化子查询 |
| UNCACHEABLE SUBQUERY | 结果集无法缓存的子查询,必须重新评估外部查询的每一行 |
| UNCACHEABLE UNION | UNION中第二个或之后的SELECT,属于无法缓存的子查询 |
3,table:查询的表名。不一定是实际存在的表名。可以为如下的值:
<unionM,N>: 引用id为M和N UNION后的结果。
: 引用id为N的结果派生出的表。派生表可以是一个结果集,例如派生自FROM中子查询的结果。
: 引用id为N的子查询结果物化得到的表。即生成一个临时表保存子查询的结果。
4,type:这是最重要的字段之一,显示查询使用了何种类型。从最好到最差的连接类型依次为:
system,const,eq_ref,ref,fulltext,ref_or_null,index_merge,unique_subquery,index_subquery,range,index,ALL
除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引。
表中只有一行数据或者是空表,这是const类型的一个特例。且只能用于myisam和memory表。如果是Innodb引擎表,type列在这个情况通常都是all或者index。
最多只有一行记录匹配。当联合主键或唯一索引的所有字段跟常量值比较时,join类型为const。其他数据库也叫做唯一索引扫描
多表join时,对于来自前面表的每一行,在当前表中只能找到一行。这可能是除了system和const之外最好的类型。当主键或唯一非NULL索引的所有字段都被用作join联接时会使用此类型。eq_ref可用于使用'='操作符作比较的索引列。比较的值可以是常量,也可以是使用在此表之前读取的表的列的表达式。
对于来自前面表的每一行,在此表的索引中可以匹配到多行。若联接只用到索引的最左前缀或索引不是主键或唯一索引时,使用ref类型(也就是说,此联接能够匹配多行记录)。
ref可用于使用'='或'<=>'操作符作比较的索引列
使用全文索引的时候是这个类型。要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引
跟ref类型类似,只是增加了null值的比较。实际用的不多。
表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取多个索引,性能可能大部分时间都不如range。
用于where中的in形式子查询,子查询返回不重复值唯一值,可以完全替换子查询,效率更高。该类型替换了下面形式的IN子查询的ref:
`value IN (SELECT primary_key FROM single_table WHERE some_expr)`
该联接类型类似于unique_subquery。适用于非唯一索引,可以返回重复值。
索引范围查询,常见于使用 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN()或者like等运算符的查询中。
SELECT * FROM tbl_name
WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name
WHERE key_column IN (10,20,30);
|
索引全表扫描,把索引从头到尾扫一遍。这里包含两种情况:
一种是查询使用了覆盖索引,那么它只需要扫描索引就可以获得数据,这个效率要比全表扫描要快,因为索引通常比数据表小,而且还能避免二次查询。在extra中显示Using index,反之,如果在索引上进行全表扫描,没有Using index的提示。
# 此表建有一个name列索引。
# 因为查询的列name上建有索引,所以如果这样type走的是index
mysql> explain select name from testa;
+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+
| 1 | SIMPLE | testa | index | NULL | idx_name | 33 | NULL | 2 | Using index |
+
1 row in set
# 因为查询的列cusno没有建索引,或者查询的列包含没有索引的列,这样查询就会走ALL扫描,如下:
mysql> explain select cusno from testa;
+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+
| 1 | SIMPLE | testa | ALL | NULL | NULL | NULL | NULL | 2 | NULL |
+
1 row in set
# 包含有未见索引的列
mysql> explain select * from testa;
+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+
| 1 | SIMPLE | testa | ALL | NULL | NULL | NULL | NULL | 2 | NULL |
+
1 row in set
|
5,**possible_keys**
查询可能使用到的索引都会在这里列出来
6,key
查询真正使用到的索引。select_type为index_merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个。
7,key_len
查询用到的索引长度(字节数)。
如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,用多少算多少。留意下这个列的值,算一下你的多列索引总长度就知道有没有使用到所有的列了。
key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
8,**ref**
如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
9,**rows**
rows 也是一个重要的字段。 这是mysql估算的需要扫描的行数(不是精确值)。这个值非常直观显示 SQL 的效率好坏, 原则上 rows 越少越好.
10,**extra**
EXplain 中的很多额外的信息会在 Extra 字段显示, 常见的有以下几种内容:
distinct:在select部分使用了distinc关键字
**Using filesort**:当 Extra 中有 Using filesort 时, 表示 MySQL 需额外的排序操作, 不能通过索引顺序达到排序效果. 一般有 Using filesort, 都建议优化去掉, 因为这样的查询 CPU 资源消耗大.
Using index:"覆盖索引扫描", 表示查询在索引树中就可查找所需数据, 不用扫描表数据文件, 往往说明性能不错。
Using temporary:查询有使用临时表, 一般出现于排序, 分组和多表 join 的情况, 查询效率不高, 建议优化.
从上面的解释,我们可以看到,这个sql关联查询,分两个简单select进行。第一条sql查询作用于d diary表,并且命中联合索引 idx_space_id_create_time(`space_id`,`create_time`),但是通过索引扫描到的行数大约有34w行。通过extra字段可以发现,使用到了**Using filesort,Using temporary,也就是说,使用到了临时表和额外文件来实现排序操作。这个可以作为一个优化点,我们需要想办法把这两个优化掉。**
第二条简单select查询,作用于v diary_visible_range 表,命中联合索引diary_user_data_type_index(`diary_id`,`data_type`), 通过索引扫描到的行数只有1行,说明这个基本没有可以优化的空间。
综上,可以看出,我们需要优化的点主要在diary表,具体是:索引扫描到的行数过多,由于数量过多所以两个表join时需要临时内存,而且排序时由于空间不足需要申请额外的文件来排序。
通过这个分析,我们就想办法减少扫描行数。上面是扫描一年来做group by查询,我们试一下只查一个月的,效果怎么样?
时间只需要200ms,效率大大提升,我们explain看下这个查询的执行计划:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|
| 1 | SIMPLE | d | range | PRIMARY,idx_space_id_create_time,space_member_index,idx_space_id_diary_time,idx_space_id_visible_range_create_time | idx_space_id_diary_time | 13 | NULL | 59374 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | v | ref | team_index,diary_user_data_type_index,diary_user_index,idx_team_id_create_time | diary_user_data_type_index | 12 | db_logger.d.id,const | 1 | Using where |
可以看出扫描行数已经降到6w行,但是还是使用了临时表,和临时文件内存。其实这个时候我们要是按照单月查询的逻辑的话,就可以不需要GROUP BY DATE_FORMAT(d.diary_time, '%Y-%m')这个查询条件了,因为这个本来就是时间范围为一年查询时,按每个月去聚合数据的。我们去掉这个条件,再看一下执行计划:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|
| 1 | SIMPLE | d | range | PRIMARY,idx_space_id_create_time,space_member_index,idx_space_id_diary_time,idx_space_id_visible_range_create_time | idx_space_id_diary_time | 13 | NULL | 59374 | Using where |
| 1 | SIMPLE | v | ref | team_index,diary_user_data_type_index,diary_user_index,idx_team_id_create_time | diary_user_data_type_index | 12 | db_logger.d.id,const | 1 | Using where |
这个时候可以看到extra字段只用到了using where ,说明没有再使用临时内存和临时表去做join 和排序了。
我们去掉group by DATE_FORMAT(d.diary_time, '%Y-%m') 再看下查询效率:
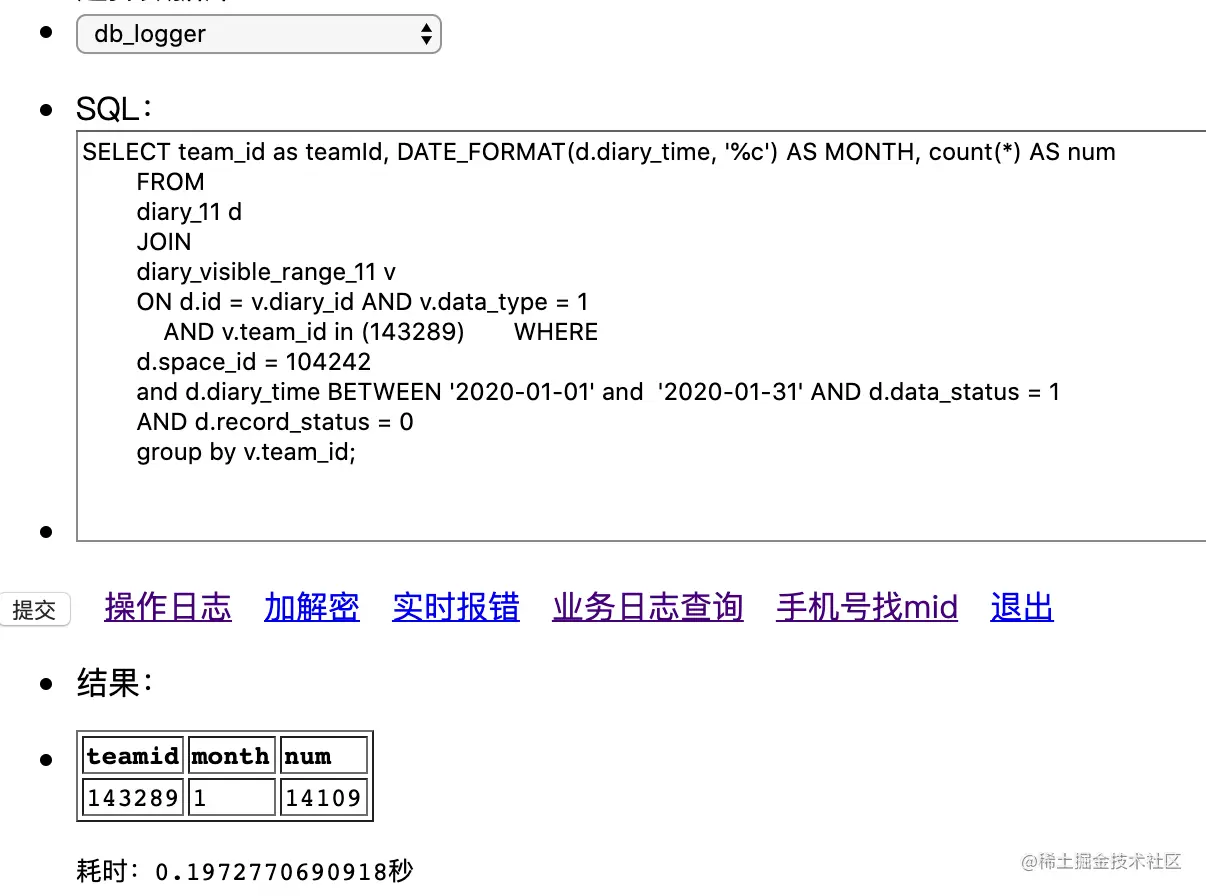
时间不到200ms,效率又提升了一些。这样我们就通过查时间范围跨度为一年,然后按月聚合的查询变为 直接按照每月去查询,就大大提升了查询效率,由于是select查询,我们可以分12个线程并发查询,这样,原来的47s的查询我们基本能控制在0.4s以内。
总结一下:由于扫描到的行数过多,我们对这么多行进行了排序聚合操作,mysql内存不够用的话就需要申请额外的文件来做排序,这样会导致耗时较久。所以在做查询时,尽量将mysql扫描行数降低,尽量减少在mysql内存中排序。
以上。


