

前言
本文主要讲述pymysql操作数据库的基本流程,以及DBUtils模块如何创建连接池的那些事。
pymsql操作数据库的流程
import pymysql
# 创建连接
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='', db='py_test', charset='utf8')
# 创建游标
cursor = conn.cursor()
# 执行SQL,并返回收影响行数
effect_row = cursor.execute("select * from table1")
# 提交,不然无法保存新建或者修改的数据
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
如上,每一次数据库操作都需要执行commit和关闭游标、关闭连接的操作,所以一般会做一层封装,如下:
# base_model.py
mysql_config = mysql.mysql_config()
mysql_pool = PooledDB(
creator=pymysql,
maxconnections=10,
host=mysql_config['host'],
port=mysql_config['port'],
user=mysql_config['user'],
password=mysql_config['password'],
database=mysql_config['db'],
charset='utf8mb4'
)
# test_model.py
class TestModel:
# 使用依赖注入
def __init__(self, db_pool):
self.db_conn = db_pool.connection()
# 游标设置为字典类型,即返回的数据类型为dict,而不是tuple
self.cursor = self.db_conn.cursor(cursor=pymysql.cursors.DictCursor)
def __exit__(self, exc_type, exc_val, exc_tb):
self.cursor.close()
self.db_conn.close()
对增删改做一层封装
# sql通过拼接有注入风险
def _base_selector(self, sql):
self.cursor.execute(sql)
rows = self.cursor.fetchall()
data = list(rows)
return data
# sql与参数分开,内部有做检查,无注入风险
def _base_selector(self, sql, params: tuple):
self.cursor.execute(sql, params)
rows = self.cursor.fetchall()
data = list(rows)
return data
注:如果不习惯类的封装方式,也可尝试使用上下文管理器进行封装
增删查改
数据库连接池
从某种层面看,数据库可看做服务端,而我们程序员(调用者)可看做客户端,而数据库连接就相当于HTTP连接,且实际上数据库连接的确包含 HTTP连接 和 Socket连接 两种方式。
另外,pymysql并不是线程安全的,所以当有多个线程同时使用pymysql操作数据库时,就会出现问题。
所以从线程安全和支持更高的并发的角度,我们一般会使用数据库连接池来解决,一般自己实现一个比较麻烦,通常是使用第三方库,如 DBUtils。
DBUtils有两种变体,通用的DB-API 2变体以及经典的PyGreSQL变体,下面只分析 通用的DB-API 2变体 的 PooledDB 和 PersistentDB(内容主要来自官方文档)。
PersistentDB
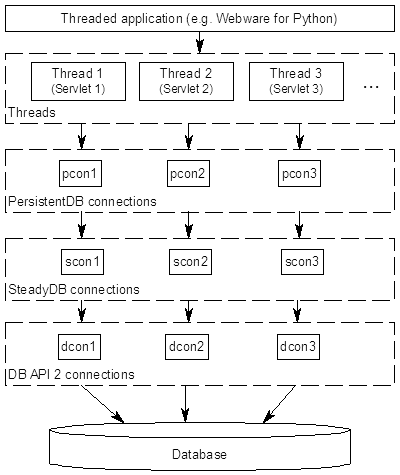
对于PersistentDB,每当线程首次打开数据库连接时,都会打开一个新的数据库连接,此连接将从现在开始用于该特定线程。当线程关闭数据库连接时,它仍将保持打开状态,以便下次同一线程请求连接时,可以使用该已打开的连接。线程死亡后,连接将自动关闭。
简而言之:PersistentDB会尝试回收数据库连接以提高数据库访问性能,且它能确保连接永远不会在线程之间共享(即使你的基础数据库驱动,比如pymysql不是线程安全的,也能确保不共享)。
注:每次有新线程,就会有新数据库连接,所以注意避免短时间内创建很多连接。
class PersistBaseModel:
def __init__(self):
mysql_pool = PersistentDB(
# 使用的mysql驱动
creator=pymysql,
host='127.0.0.1',
port='root',
user='root',
password='root',
database='py_test',
charset='utf8mb4',
# 一个连接最多被重复使用的次数,None表示无限制
maxusage=None,
)
self.db_conn = mysql_pool.connection()
# 设置返回的数据类型为dict,而不是tuple
self.cursor = self.db_conn.cursor(cursor=pymysql.cursors.DictCursor)
def __exit__(self, exc_type, exc_val, exc_tb):
self.cursor.close()
self.db_conn.close()
PoolDB
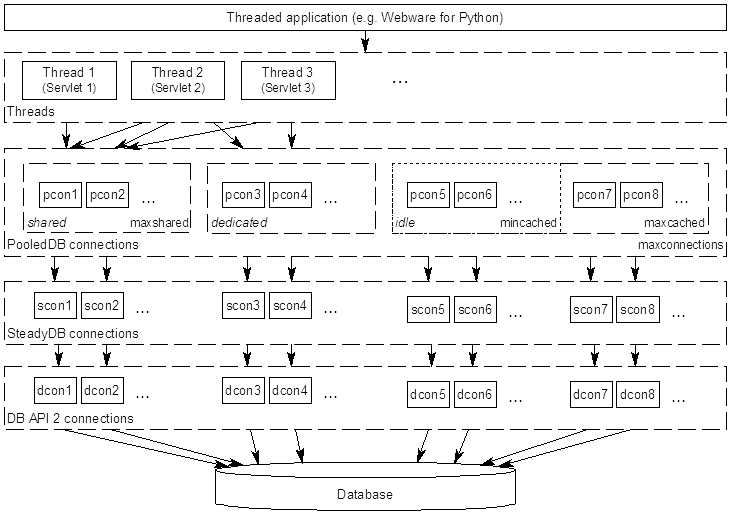
如图,对于PoolDB来说,它与PersistentDB最大的区别在于: PersistentDB是每个线程就创建一个连接,所以存在连接暴涨的风险;而 PoolDB 可以控制连接的总数量,所以不会存在该问题。
另外,PoolDB还有一个比较有趣的特性,就是连接共享,即不同线程之间可以共享打开的数据库连接,比如上图的Thread1和Thread3就共享了 pcon1 和 pcon2 连接。
但是,连接共享必须建立在线程安全的基础上,不然就会导致数据错乱。比如有两个线程共享一个连接,A线程修改了数据,但是发现有问题,需要回滚,而B线程不巧插了一脚,在回滚前执行了commit操作,就会导致数据错乱,这也是为什么连接共享必须建立在线程安全的基础上。
对于PoolDB,连接共享对应两种情况:
1.你的数据库驱动(基础DB-API)是在连接级别上是线程安全的,且设置了 maxshared 参数,则会产生连接共享的情况。
2.你的数据库驱动(基础DB-API)不是线程安全的,如pymysql,则 PoolDB 会通过线程锁来保证线程安全,且不会产生连接共享的情况(因为 maxshared 参数被置为0,所以设置这个参数是无效的)
class PoolDB:
# pymysql 的 threadsafety=1
if threadsafety > 1 and maxshared:
self._maxshared = maxshared
self._shared_cache = [] # the cache for shared connections
else:
self._maxshared = 0
注:网上部分文章提到,当 maxshared 参数为0或者None时,表示连接全部共享,这其实是一个错误的说法,当参数为0或者None时,表示的是连接不共享,即每个连接都是专用的,从源码从可以看到:
maxshared: maximum number of shared connections
(0 or None means all connections are dedicated)
When this maximum number is reached, connections are
shared if they have been requested as shareable.
示例代码:
class BaseModel:
def __init__(self):
mysql_pool = PooledDB(
# 使用的mysql驱动
creator=pymysql,
host='127.0.0.1',
port='root',
user='root',
password='root',
database='py_test',
charset='utf8mb4',
# 连接池允许的最大连接数
maxconnections=10,
# 初始化时,连接池中至少创建的空闲的链接
mincached=2,
# 连接池中最多共享的连接数量
maxshared=3,
# 一个连接最多被重复使用的次数,None表示无限制
maxusage=None,
)
self.db_conn = mysql_pool.connection()
# 设置返回的数据类型为dict,而不是tuple
self.cursor = self.db_conn.cursor(cursor=pymysql.cursors.DictCursor)
def __exit__(self, exc_type, exc_val, exc_tb):
self.cursor.close()
self.db_conn.close()
