

Dubbo+zookeeper实现微服务架构方案
1、微服务架构两种方案的比较
-
Spring Boot + Spring Cloud 组件多,功能完备, Http通讯,俗称SpringCloud全家桶 ->微服务架构解决方案一
-
Spring Boot+Dubbo+Zookeeper 组件少,功能非完备 Alibaba Dubbo ->RPC通讯框架 ->微服务架构解决方案二
微服务架构是一种思想,实现方案是分布式系统,分布式系统最大的问题 -> 网络是不可靠的。
2、微服务架构要解决的四大问题 高可用 (一直可以用)->高并发->高性能
1、客户端如何访问这么多服务?
API网关
2、服务与服务之间如何通讯?
同步通信
HTTP (Apache Http Client)
异步通讯
消息队列 kafka RabbitMQ RocketMQ
3、这么多服务,如何进行管理?
服务治理
服务注册与发现
基于客户端的服务注册与发现
Apache Zookeeper
基于服务端的服务注册与发现
Netflix Eureka
4、服务挂了,怎么办
重试机制
服务熔断
服务降级
服务限流
3、什么是分布式锁
Zookeeper 分布式协调服务: 解决分布式系统当中多个进程之间的同步控制,让他们有序的访问某种临界资源,防止造成脏数据的后果。
为了防止分布式系统中的多个进程之间相互干扰,用分布式协调技术对这种进程进行调度,而分布式协调技术的核心就是分布式锁
**分布式锁:**在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行。
分布式系统中多个进程之间如何有序的访问资源,分布式锁
Redis实现分布式锁流程
Redis怎么实现加锁:
Redis实现分布式锁需要自己编写代码实现,而Zookeeper通过自身的顺序临时节点来实现分布式锁和等待队列。
Redis实现分布式锁的三大致命问题
4、什么是Zookeeper
简单来说zookeeper=文件系统的数据模型结构+监听通知机制(Watch)
Zookeeper的数据模型结构很像数据结构当中的树,也很像文件系统中的目录。
树是由所有节点组成,Zookeeper的数据存储也同样是基于节点,这种节点叫做Znode
但是,不同于树的节点,Znode的引用方式是路径引用,类似于文件系统,通过路径进行访问数据,而redis是根据key值来访问数据
/服务A/A1
/服务B/B1
每一个Znode节点有唯一的路径
Znode 包含哪些元素
-
data: Znode存储的数据信息
-
ACL:记录Znode的访问权限,那些人或者哪些IP可以访问本节点
-
start: 包含Znode的各种元数据,比如事务ID、版本号、时间戳、大小等
-
child: 当前节点的子节点
Zookeeper适用于读多写少的场景,Znode并不是用来存储大规模数据,而是用于存储少量的状态和配置信息,每个节点的数据量不能超过1Mb
Zookeeper的基本操作
创建节点
create
删除节点
delete
判断节点是否存在
esists
获得一个节点的数据
getData
设置一个节点的数据
setData
获取节点下的所有节点
getChildren
exists,getData,getChildren属于读操作,Zookeeper客户端在请求读操作的时候,可以喧杂是否设置Watch
Zookeeper的事件通知
我们可以把Watch理解成是注册在特定Znode的触发器,当这个Znode发生改变,也就是调用了create、delete、setData写操作方法时,将会触发Znode上注册的对应事件,请求Watch的客户端会接收到异步通知。
Zookeeper事件通知机制实现服务与注册功能,实现了分布式系统的高可用问题
Zookeeper要实现分布式系统的高可用,就必须满足Zookeeper的一致性。
Zookeeper身为分布式协调服务,如果自身挂掉怎么处理?为了防止单击挂掉的情况,Zookeeper维护了一个集群,如下图:
Zookeeper集群的ZAB协议解决了两个问题:
- 1、Zookeeper集群崩溃恢复
- 2、Zookeeper集群实现数据一致性、主从同步数据
Zookeeper集群采用ZAB协议解决崩溃恢复三阶段
ZAB协议一阶段:选举阶段,当主节点的zookeeper服务挂了,再所有从节点中选举出准主节点,怎么选举?
ZAB协议二阶段:发现阶段,由于网络等原因选举出两个准主节点,就会出现写写冲突,怎么处理?
-
1、所有的从节点向两个准主节点发送epoch值,准主节点从中选出最大的epoch值,基于此值+1,生成新的epoch分发给各个从节点。
-
2、各个从节点接收到epoch值后,返回ACK给准主节点,带上各自最大的ZXID值和历史事务日志,准主节点从中选出最大的ZXID值,并更新自身历史日志
-
ZAB协议三阶段:同步阶段(就是把自己当选为主节点的消息说给其他人听,大多数人同意后自己就真正成为主节点了)
把准主节点刚才得到的最新历史事务日志,同步给集群中所有的从几点,只要半数以上的从节点同步成功,这个准主节点才能成为主节点。
Zookeeper集群实现数据一致性、主从同步数据
ZAB的数据写入:Broadcast广播阶段、就是Zookeeper常规情况下要更新数据的时候,由Leader主节点广播到所有的Follower从节点
过程如下:
-
客户端发出写入数据请求给任意Follower从节点
-
Follower把写入数据请求转发给Leader主节点(因为从节点只能读操作、主节点可以写操作、实现读写分离)
-
Leader主节点采用二阶段提交方式,先发送Propose广播给所有的Follower从节点(准备写数据,开启事务,开启一阶段提交)
-
Follower从节点接收到Propose消息,写入日志成功后(执行将数据写入日志中,但是没有提交),返回ACK消息给Loader主节点(说明准备就绪)
-
leader主节点接收到半数以上的ACK消息后,返回成功给客户端,并且广播提交请求给所有从节点,最后所有节点统一提交数据,完成数据的一致性
-
最后总结:Zookeeper的应用场景
1、分布式锁
利用Zookeeper的临时顺序节点,可以轻松实现分布式锁
2、分布式服务的注册和发现
利用Znode和Watcher可以实现分布式服务的注册和发现,应用在阿里的分布式RPC框架Dubbo
Kafka、Hbase、Hadoop也是依靠同步节点信息,实现高可用
一致性:强一致性、弱一致性、顺序一致性(Zookeeper默认采用)
Zookeeper是如何实现分布式锁的呢?
1、分布式锁的核心
#### 三个核心要素
加锁
解锁
锁超时
#### Redis实现分布式锁存在三个问题
1、要保证原子性操作,加锁和锁超时的操作要一次性执行
2、防止误删锁(在设置锁超时的时间内,一个进程还没有操作完,另一个进程开始操作数据,然后第一个进程操作完成,执行显示删除del命令,此时删除的是另一个进程的锁
3、在误删的基础上,多加一个守护线程,为锁续命,保证每次一个进程必须操作完数据,如果超过锁超时时间没有操作完成,则守护线程会加时,让一个进程操作完数据,下一个进程再执行。
什么是临时顺序节点?
我们先来看看zookeeper的数据模型结构
zookeeper的数据存储就像一颗二叉树,这棵树由节点组成,这种节点叫做Znode
Znode分为四种类型
- 持久节点
默认的节点类型,创建节点的客户端断开连接后,该节点依旧存在
-
持久顺序节点
顺序节点:在创建节点时,Zookeeper根据创建时间顺序会给该节点名称进行编号
- 临时节点
当创建节点的客户端与Zookeeper断开连接之后,临时节点会删除
- 临时顺序节点
在创建节点时,Zookeeper根据创建时间顺序会给该节点名称进行编号,当创建节点的客户端与Zookeeper断开连接之后,临时节点会删除。
zookeeper是通过临时顺序节点特性来实现分布式锁加锁解锁操作,用Watch观察事件机制来解决锁超时问题
Zookeeper和Redis实现分布式锁的比较
zookeeper部署的三种方式
- **单击部署 **:在一个机子上部署一个zookeeper
- 集群部署 :在多个机子上部署多个zookeeper
- 伪集群部署:在一个机子上部署多个zookeeper
注意:集群为大于等于3个基数,如3、5、7不宜太多,集群机器多了选举和数据同步耗时长,不稳定
关于Zookeeper安装部署的教程如下:blog.csdn.net/lihao21/art…
Dubbo介绍
Dubbo简介
Apache Dubbo是一款高性能、轻量级的开源java RPC分布式服务框架,它提供了三大核心功能,面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现(Dubbo通过调用Zookeeper做服务注册和发现),它最大的特点是按照分层的方式架构,使用这种方式可以使各个层之间解耦合(或者最大限度的松耦合),从服务模型的角度来看,Dubbo采用的是非常简单的模型,要么是提供方提供服务,要么是消费方消费服务,所以基于这一点可以抽象出服务提供方和服务消费方两个角色。
远程过程方法调用
平常我们在本地调用接口是这么做的
@Autorid
UserService userService;
userService.login();
现在通过远程调用接口(换个接口)
@Reference
UserService userService;
userService.login();
服务提供方和服务消费方
服务提供方(定义、编写接口的一方)
UserService
服务消费方(调用接口的一方)
UserService userService
userService.login()
具体参考Dubbo官方网站 dubbo.apache.org/zh-cn/docs/…
阿里内部并没有采用 Zookeeper 做为注册中心,而是使用自己实现的基于数据库的注册中心,即:Zookeeper 注册中心并没有在阿里内部长时间运行的可靠性保障,此 Zookeeper 桥接实现只为开源版本提供,其可靠性依赖于 Zookeeper 本身的可靠性.
Dubbo的服务治理
特性 描述
透明远程调用 就像调用本地方法一样调用远程方法,只需简单配置,没有任何API侵入(解决了服务与服务 如何通信?)
负载均衡机制 Client端LB,可在内网替代F5等硬件负载均衡(F5是专门做负载均衡的硬件设备服务器, nginx是安装在电脑上的软件)
容错重试机制 服务Mock数据,重试次数,超时机制等(解决了服务挂了怎么办问题?)
自动注册发现 注册中心基于接口名查询服务提供者的IP地址,并且能够平滑添加或删除服务提供者(解决了服务与服务之间如何管理的问题?)
性能日志监控 统计服务的 调用次数和调用时间的监控中心
服务治理中心 路由规则(解决了客户端如何访问这么多服务的问题?)动态配置、服务降级、访问控制、权重调整,负载均衡、等手动配置
自动注册中心 无,比如:熔断限流机制(解决了服务挂了怎么办问题?)、自动权重调整等
-
Remotion: 远程通讯,提供对多种NIO的框架抽象封装,包括“同步转异步”和“请求、响应”模式的信息交流方式
-
Cluster:服务框架,提供基于接口方法的透明远程过程调用,包括多协议支持,以及负载均衡,失败容错,地址路由,动态配置等集群支持
-
Registry: 服务注册中心,服务自动发现,基于注册中心目录服务,使服务消费方能动态的查找服务提供方,使地址透明,使服务提供方可以平滑的增加或减少机器
Socket的三种通信模型
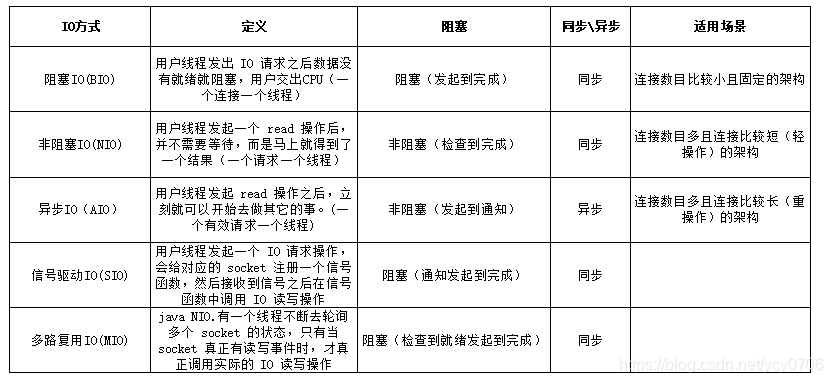
三者比较
BIO:同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,可以经过线程池改进,
适合于连接数目小且固定。
NIO:同步非阻塞,一个请求一个线程,客户端的连接请求都会注册到多路复用器上,多路复用器轮询到连接有IO请求时才启动一个线程进行处理;(用的是Netty框架:Netty框架用于游戏服务器、物联网服务器等高并发场景)
适合连接数目多,连接比较短的架构,比聊天服务器,并发局限于应用中,编程比较复杂;
AIO:连接数目多且连接比较长的架构,比如相册服务器,充分调用OS参与并发操作,JDK1.7开始支持
三种通信模型原文链接:blog.csdn.net/ycy0706/art…
Dubbo的五大组件
组件角色 说明
Provider 暴露服务的服务提供方
Consume 调用远程服务的服务消费方
Registry 服务注册与发现的注册中心
Monitor 统计服务的调用次数和调用事件的监控中心
Container 服务运行容器
调用关系说明
-
服务容器
Container负责启动、加载、运行服务提供者 -
服务提供者
Provider在启动时,向注册中心注册自己提供的服务 -
服务消费者
Consume在启动时,向注册中心订阅自己所需要的服务 -
注册中心
Registry返回服务提供者地址列表给消费者,如果有变更,如果有变更,注册中心将基于长连接推送变更数据到消费者 -
服务消费者
consume,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选用另一台调用 -
服务消费者
consume和服务提供者provider,在内存中累计使用次数和调用事件,定时每分钟发送一次统计数据到监控中心MonitorDubbo架构图
Dubbo开发文档源码: github.com/apache/dubb…
服务与服务之间的通讯分为两种
同步:RPC、Http
异步:消息队列
服务消费方调用服务提供方是RPC远程调用同步操作,其他调用为异步操作
Dubbo实现简单流程
1、定义接口
创建maven项目hello-dubbo-service-user-api,定义接口UserService
package com.baoji.hello.dubbo.service.user.api;
/**
* 定义用户接口
*/
public interface UserService {
String sayHi();
}
2、服务提供方
通过springboot初始化器创建springboot项目hello-dubbo-service-user-provider,去官方文档学习需要的pom文件和相应的配置。
-
2.1导入Pom文件(dubbo与springboot的整合)
因为之前那个接口项目和此项目不在一个项目下,将上个接口以jar包的形式使用
maven上传到本地仓库,供提供方使用<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <!--添加dubbo依赖springboot的jar包--> <!-- https://mvnrepository.com/artifact/org.apache.dubbo/dubbo-spring-boot-starter --> <dependency> <groupId>org.apache.dubbo</groupId> <artifactId>dubbo-spring-boot-starter</artifactId> <version>2.7.1</version> </dependency> <!--添加要实现的接口--> <dependency> <groupId>com.baoji</groupId> <artifactId>hello-dubbo-service-user-api</artifactId> </dependency> </dependencies>-
2.2编写实现接口
记得添加
@Service注解,此注解是Dubbo提供的,而不是spring提供的package com.baoji.hellodubboserviceuserprovider.service; import org.springframework.stereotype.Service; @Service(version="${user.service.version}") public class UserServiceImpl implements UserService { public String sayHi(){ return "Hello Dubbo!"; } }-
2.3 在主启动类上添加
Main.main(args)在容器之上添加一个服务提供者
package com.baoji.hellodubboserviceuserprovider; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class HelloDubboServiceUserProviderApplication { public static void main(String[] args) { SpringApplication.run(HelloDubboServiceUserProviderApplication.class, args); Main.main(args); } }- 2.4编写配置
application.yml
- 2.4编写配置
-
spring: application: name: hello-dubbo-service-user-provider #配置版本 user: service: verison: 1.0.0 #配置需要扫描dubbo 的包 dubbo: scan: basePackages: com.baoji.hello.dubbo.service.user.provider.service application: id: hello-dubbo-service-user-provider # 配置dubbo的id和名字 name: hello-dubbo-service-user-provider qos-port: 22222 qos-enable: true # 设置状态检查和端口 protocol: id: dubbo name: dubbo # 设置采用dubbo协议做远程通信,采用12345端口访问数据,状态为服务端 port: 12345 status: server registry: id: zookeeper # 设置zookeeper注册中心的集群地址,多个集群通过backup设置 address: zookeeper://192.168.0.103:2181?backup=192.168.0.103:2182,192.168.0.103:2183 ``` -
-
2.5、测试(打开Dubbon Admin客户端工具可以发现服务以及注册进zookeeper中)
3、服务消费者
通过springboot初始化器创建springboot项目hello-dubbo-service-user-consume
-
1、编写pom
比服务提供方多个web依赖
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--添加dubbo依赖springboot的jar包--> <!-- https://mvnrepository.com/artifact/org.apache.dubbo/dubbo-spring-boot-starter --> <dependency> <groupId>org.apache.dubbo</groupId> <artifactId>dubbo-spring-boot-starter</artifactId> <version>2.7.1</version> </dependency> <!--添加要实现的接口--> <dependency> <groupId>com.baoji</groupId> <artifactId>hello-dubbo-service-user-api</artifactId> </dependency> </dependencies>-
2、编写Controller
@RestController public class UserController{ @Reference(version="${user.service.version}")//远程过程调用接口注解,添加版本号 private UserService userService; @RequestMapping(value="hi",method=RequestMethod.GET) public String sayHi(){ return userService.sayHi(); } }-
3.3、编写application.yml
spring: application: name: hello-dubbo-service-user-consume #配置版本 user: service: verison: 1.0.0 #配置需要扫描dubbo 的包 dubbo: scan: basePackages: com.baoji.hello.dubbo.service.user.consume.service application: id: hello-dubbo-service-user-provider # 配置dubbo的id和名字 name: hello-dubbo-service-user-provider qos-enable: true # 设置状态检查 protocol: id: dubbo name: dubbo # 设置采用dubbo协议做远程通信,采用12345端口访问数据,状态为服务端 port: 12345 registry: id: zookeeper # 设置zookeeper注册中心的集群地址,多个集群通过backup设置 address: zookeeper://192.168.0.103:2181?backup=192.168.0.103:2182,192.168.0.103:2183- 3.4、浏览器输入
localhost:8080/hi调用接口
- 3.4、浏览器输入
-
-
其实远程调用接口和本地调用接口一样,只不过远程调用接口是@Reference注解,本地调用接口是@Autowired注解
Dubbo是对内部服务调用使用RPC通信,对外部服务调用使用Rest ful通信微服务架构要实现高并发、高性能、高可用,高性能由Zookeeper实现,接下来是对内部调用使用负载均衡实现高并发,
Dubbo的优点:可以对服务或者一个方法进行实现负载均衡
Dubbo动态代理策略:
默认采用javassist动态字节码生成,创建代理类,但是也可以通过SPI扩展机制配置自己的动态代理策略。
实现负载均衡就是开启多个服务提供者,让服务消费者根据负载均衡算法访问服务提供者,DUbbo有四种负载均衡算法,默认的轮询算法是随机算法
-
在pom文件中添加loadbalance
dubbo: provider: loadbalance: roundrobin-
修改实现类,让知道调用的是哪个端口
package com.baoji.hellodubboserviceuserprovider.service; import org.springframework.stereotype.Service; @Service(version="${user.service.version}") public class UserServiceImpl implements UserService { @Value("${dubbo.protocol.port}") private String port; public String sayHi(){ return "Hello Dubbo! I am from "+port; } }- 修改端口,开启多个服务提供者实例
- 测试
-
Dubbo的SPI扩展机制
Dubbo中使用高效的java序列化(KRYO和FST)
dubbo RPC是dubbo体系中最核心的一种高性能、高吞吐量的远程调用方式,我喜欢称之为多路复用的TCP长连接调用,简单的说:
-
长连接:避免了每次调用新建TCP连接,提高了调用的响应速度
-
多路复用:单个TCP连接可交替传输多个请求和响应的消息,降低了连接的等待闲置时间,从而减少了同样并发数下的网络连接数,提高了系统吞吐量。
dubbo RPC主要用于两个dubbo系统之间作远程调用,特别适合高并发、小数据的互联网场景。
而序列化对于远程调用的响应速度、吞吐量、网络带宽消耗等同样也起着至关重要的作用,是我们提升分布式系统性能的最关键因素之一。
在dubbo RPC中,同时支持多种序列化方式,例如:
- dubbo序列化:阿里尚未开发成熟的高效java序列化实现,阿里不建议在生产环境使用它
- hessian2序列化:hessian是一种跨语言的高效二进制序列化方式。但这里实际不是原生的hessian2序列化,而是阿里修改过的hessian lite,它是dubbo RPC默认启用的序列化方式
- json序列化:目前有两种实现,一种是采用的阿里的fastjson库,另一种是采用dubbo中自己实现的简单json库,但其实现都不是特别成熟,而且json这种文本序列化性能一般不如上面两种二进制序列化。
- java序列化:主要是采用JDK自带的Java序列化实现,性能很不理想。
在通常情况下,这四种主要序列化方式的性能从上到下依次递减。对于dubbo RPC这种追求高性能的远程调用方式来说,实际上只有1、2两种高效序列化方式比较般配,而第1个dubbo序列化由于还不成熟,所以实际只剩下2可用,所以dubbo RPC默认采用hessian2序列化。
但hessian是一个比较老的序列化实现了,而且它是跨语言的,所以不是单独针对java进行优化的。而dubbo RPC实际上完全是一种Java to Java的远程调用,其实没有必要采用跨语言的序列化方式(当然肯定也不排斥跨语言的序列化)。
最近几年,各种新的高效序列化方式层出不穷,不断刷新序列化性能的上限,最典型的包括:
- 专门针对Java语言的:Kryo,FST等等
- 跨语言的:Protostuff,ProtoBuf,Thrift,Avro,MsgPack等等
这些序列化方式的性能多数都显著优于hessian2(甚至包括尚未成熟的dubbo序列化)。
有鉴于此,我们为dubbo引入Kryo和FST这两种高效Java序列化实现,来逐步取代hessian2。
其中,Kryo是一种非常成熟的序列化实现,已经在Twitter、Groupon、Yahoo以及多个著名开源项目(如Hive、Storm)中广泛的使用。而FST是一种较新的序列化实现,目前还缺乏足够多的成熟使用案例,但我认为它还是非常有前途的。
在面向生产环境的应用中,我建议目前更优先选择
Kryo。
Kryo怎么使用呢?(服务提供方和消费方使用方式一样,使用yml方式配置)
-
1、添加依赖
<!-- https://mvnrepository.com/artifact/de.javakaffee/kryo-serializers --> <!-- 添加Kryo高速序列化的依赖--> <dependency> <groupId>de.javakaffee</groupId> <artifactId>kryo-serializers</artifactId> <version>0.42</version> </dependency>-
2、在配置文件application.yml中添加kryo
dubbo: protrocol: serialization: kryo注册被序列化类(可有可无)
要让Kryo和FST完全发挥出高性能,最好将那些需要被序列化的类注册到dubbo系统中,例如,我们可以实现如下回调接口:
public class SerializationOptimizerImpl implements SerializationOptimizer { public Collection<Class> getSerializableClasses() { List<Class> classes = new LinkedList<Class>(); classes.add(BidRequest.class); classes.add(BidResponse.class); classes.add(Device.class); classes.add(Geo.class); classes.add(Impression.class); classes.add(SeatBid.class); return classes; } }然后在yml中配置中添加:
dubbo: protrocol: optimizer: com.alibaba.dubbo.demo.SerializationOptimizerImpl在注册这些类后,序列化的性能可能被大大提升,特别针对小数量的嵌套对象的时候。
当然,在对一个类做序列化的时候,可能还级联引用到很多类,比如Java集合类。针对这种情况,我们已经自动将JDK中的常用类进行了注册,所以你不需要重复注册它们(当然你重复注册了也没有任何影响),包括:
GregorianCalendar InvocationHandler BigDecimal BigInteger Pattern BitSet URI UUID HashMap ArrayList LinkedList HashSet TreeSet Hashtable Date Calendar ConcurrentHashMap SimpleDateFormat Vector BitSet StringBuffer StringBuilder Object Object[] String[] byte[] char[] int[] float[] double[]由于注册被序列化的类仅仅是出于性能优化的目的,所以即使你忘记注册某些类也没有关系。事实上,即使不注册任何类,Kryo和FST的性能依然普遍优于hessian和dubbo序列化。
为什么一定要手动注册这些类实现告诉序列化接口?
-
1、有人可能会问为什么不用配置文件来注册这些类?这是因为要注册的类往往数量较多,导致配置文件冗长;而且在没有好的IDE支持的情况下,配置文件的编写和重构都比java类麻烦得多;最后,这些注册的类一般是不需要在项目编译打包后还需要做动态修改的。
-
2、有人也会觉得手工注册被序列化的类是一种相对繁琐的工作,是不是可以用
annotation注解来标注,然后系统来自动发现并注册。但这里annotation的局限是,它只能用来标注你可以修改的类,而很多序列化中引用的类很可能是你没法做修改的(比如第三方库或者JDK系统类或者其他项目的类)。另外,添加annotation毕竟稍微的“污染”了一下代码,使应用代码对框架增加了一点点的依赖性。
除了annotation,我们还可以考虑用其它方式来自动注册被序列化的类,例如扫描类路径,自动发现实现Serializable接口(甚至包括Externalizable)的类并将它们注册。当然,我们知道类路径上能找到Serializable类可能是非常多的,所以也可以考虑用package前缀之类来一定程度限定扫描范围。
当然,在自动注册机制中,特别需要考虑如何保证服务提供端和消费端都以同样的顺序(或者ID)来注册类,避免错位,毕竟两端可被发现然后注册的类的数量可能都是不一样的。
-
无参构造函数和Serializable接口
如果被序列化的类中
不包含无参的构造函数,则在Kryo的序列化中,性能将会大打折扣,因为此时我们在底层将用Java的序列化来透明的取代Kryo序列化。所以,尽可能为每一个被序列化的类添加无参构造函数是一种最佳实践(当然一个java类如果不自定义构造函数,默认就有无参构造函数)。这里我们可以用Lomback插件另外,Kryo和FST本来都不需要被序列化的类实现Serializable接口,但我们还是
建议每个被序列化类都去实现它,因为这样可以保持和Java序列化以及dubbo序列化的兼容性,另外也使我们未来采用上述某些自动注册机制带来可能. -
Hystrix解决服务雪崩问题
当服务调用链中底层服务出现故障,导致整个服务调用链瘫痪,这种叫做雪崩效应。服务熔断可以解决这个问题,Dubbo集成Springcloud整合Netfix公司开源的Hystrix组件可以实现(和SpringCloud用法一样),Hystrix会经过5秒20次来判断服务是否可用,不可用则自动开启服务熔断机制,服务熔断开启后,服务消费者会使用fallbackMethod返回错误信息
怎么使用Hystrix
-
1、导入Hystrix依赖
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-netflix-hystrix --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> <version>2.0.1.RELEASE</version> </dependency>-
2、在主启动类添加开启熔断的注解
@EnableHystrix -
3、在服务提供方实现接口的方法上添加
@HystrixCommand注解,默认为5秒20次调用,没拿到服务就开启熔断机制。也可以自己在注解内设置时间 -
4、在实现类内手动抛出个异常,模拟熔断机制的发生
-
5、配置服务消费方,服务消费方和服务提供方的前两步一样
-
6、服务消费方的控制器类上添加注解
@HystrixCommand(fallbackMethod="hiError"),调用服务出现错误时,熔断机制开启时返回的错误信息,hiError为定义错误信息返回的方法名 -
7、测试(服务消费方通过接口调用服务提供方,因为提供方主动抛异常,导致熔断机制开启,返回错误信息)
-
熔断器仪表盘监控熔断发生情况
-
1、添加
dashboard依赖<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-netflix-hystrix-dashboard --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId> <version>2.0.1.RELEASE</version> </dependency> -
2、主启动类添加开启熔断机制监控注解
@EnableHystrixDashboard -
3、在servlet中使用java编写配置文件,类似于之前的xml配置servlet
- 4、测试
消费者发送访问提供者请求,触发熔断机制,开始监控
Dubbo解决服务挂了也是集成Netflix中的Hystrix,所以Hystrix具体实现访问本人Springcloud的博客:juejin.cn/post/684490…
Zookeeper和Eureka做注册中心的区别
-
相同点:都可以实现分布式服务注册中心
-
不同点:
Zookeeper采用CP保证数据的一致性问题,原理采用ZAB原子广播协议,当我们的zk领导者leader因为某种原因宕机的情况下,会自动触发重新选一个新的领导角色,整个选举的过程为了保证数据的一致性问题,在选举的过程中整个zk环境是不可以使用,可以短暂可能无法使用zk,意味着微服务采用该模式的情况下,可能无法实现通讯。(本地有缓存除外)注意: 可运行的节点必须满足过半机制,整个zk才可以使用
Eureka采用AP的设计理念架构注册中心,完全去中心化思想,也就是没有主从之分,每个节点都是均等,采用相互注册原理,相互复制数据,你中有我我中有你,只要最后有一个eureka节点存在就可以保证整个微服务可以实现通讯。我们在使用注册中心,可用性优先级最高,可以读取的数据短暂暂时不一致性,但是至少要能够保证注册中心可用性。
好了,今天的内容就分享到这了,要想了解springcloud全家桶解决微服务架构方案可以关注作者查看其他博客内容哦!!!来一波双击666点赞👍+关注👉哦。。。
