

1、数据库中锁的作用
数据库系统使用锁是为了支持对【共享资源】进行【并发访问】,提供【数据】的【完整性】和【一致性】;
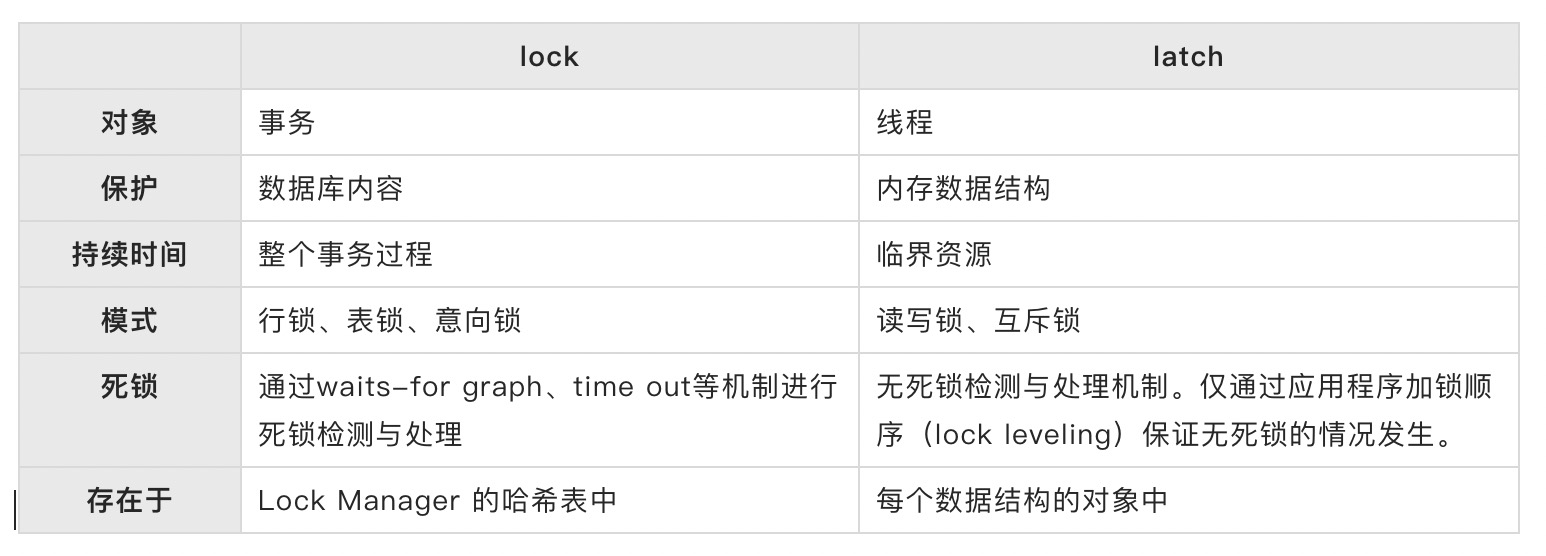
2、Lock与Latch
3、InnoDB存储引擎中的锁
3-1、锁的类型
InnoDB存储引擎实现了两种标准的行级锁:
-
共享锁(S Lock),允许事务读一行数据;
-
排他锁(X Lock),允许事务删除或更新一行数据;
不同的锁之间兼容性不相同:
锁兼容(Lock Compatible):一个事务获得一行数据【共享锁】,另一个事务也可以获得同一行的【共享锁】;
锁不兼容:一个事务获得行的排他锁,必须等待其他事务释放共享锁或排他锁;
S和X锁都是行锁,兼容是指对【同一记录】(row)锁的兼容性情况;
3-2、一致性【非锁定读】
一致性非锁定读(consistent nonlocking read) 是指 InnoDB存储引擎通过行多版本控制(multi versioning) 的方式来读取当前执行时间数据库中行的数据。
如果读取的行正在执行DELETE或UPDATE操作,这时读取操作不会因此等待行上锁的释放,而是去读取行的一个【快照数据】。
之所以称其为【非锁定读】,因为不需要等待访问行上X锁的释放。
优点:
-
【快照数据】是指该行之前版本的数据,该实现通过undo段来完成,而undo用来在事务中回滚数据,因此【快照数据本身没有额外开销】;
-
读取【快照数据】不需要上锁,因为没有事务需要对历史数据进行修改操作;
-
【非锁定读】提高了数据库的并发性;
-
这是InnoDB引擎默认读取方式,但不是每个事务隔离级别都采用非锁定的一致性读;在事务隔离级别 READ COMMITTED 和 REPEATABLE READ(InnoDB 存储引擎的默认事务隔离级别),InnoDB存储引擎使用非锁定的一致性读;对于快照数据,READ COMMITTED下读取最新一份快照数据,REPEATABLE READ读取【事务开始】时的行数据版本;
3-2-1、多版本并发控制(Multi Version Concurrency Control, MVCC)
快照数据其实就是当前行数据之前的历史版本,每行记录可能有多个版本;一个行记录可能不止一个快照数据,一般称这种技术为行多版本技术;
关于多版本并发控制,
多版本控制: 指的是一种提高并发的技术。最早的数据库系统,只有读读之间可以并发,读写,写读,写写都要阻塞。引入多版本之后,只有写写之间相互阻塞,其他三种操作都可以并行,这样大幅度提高了InnoDB的并发度。在内部实现中,与Postgres在数据行上实现多版本不同,InnoDB是在undolog中实现的,通过undolog可以找回数据的历史版本。找回的数据历史版本可以提供给用户读(按照隔离级别的定义,有些读请求只能看到比较老的数据版本),也可以在回滚的时候覆盖数据页上的数据。在InnoDB内部中,会记录一个全局的活跃读写事务数组,其主要用来判断事务的可见性。
3-3、一致性【锁定读】
对数据库读取操作进行加锁以保证数据逻辑的一致性;
InnoDB存储引擎对于 SELECT语句支持两种一致性的锁定读(locking read):
-
SELECT ... FOR UPDATE:读取行记录加一个X锁;其他事务不能对已锁定的行加任何锁;
-
SELECT ... LOCK IN SHARE MODE:对读取的行记录加一个S锁,其他事务可以对行加S锁,但如果加X锁,则会被阻塞;
对于一致性【非锁定读】,即使读取的行已被执行 SELECT ... FOR UPDATE,也可以进行读取;
4、锁的算法
4-1、行锁的3种算法
InnoDB存储引擎有3种行锁算法,分别是:
-
Record Lock:单个行记录上的锁;
-
Gap Lock:间隙锁,锁定一个范围,但不包含记录本身;
-
Next-Key Lock:Gap Lock + Record Lock,锁定一个范围,并且锁定记录本身;
如果索引有 10,11,13,20这四个值,在Next-Key Locking下索引的区间为:
(-∞,10],即 -∞ < Lock <= 10,因为要锁定记录本身;
(10, 11],
(11, 13],
(13, 20],
(20, +∞)
关于Next-Key Lock:
-
Next-Key Lock设计目的是为了解决 幻读(Phantom Problem);
-
Next-Key Lock如果降级为 Record Lock 仅在查询的列是【唯一索引】的情况下;对于【唯一键值】的锁定,Next-Key Lock降级为【Record Lock】仅存在于查询【所有的】唯一索引列;查询其中一个还是用 Next-Key Lock;
4-2、解决 Phantom Problem
幻读(Phantom Problem)是指在【同一事务下】,连续执行两次【同样的SQL语句】可能导致不同的结果,第二次的SQL语句可能会返回之前不存在的行;
当表中存在 1,2,5 数据,
-
事务T1 第一次 执行 select * from table where id >= 1,返回 1,2,5三条数据,
-
此时事务T2执行 insert into table (id) value (1) 或 INSERT INTO table SELECT 4 后,
-
事务T1 再次执行 select * from table where id >= 1,返回 1,2,4,5;
4-2-1、采用 Next-Key Locking 算法避免 幻读(Phantom Problem)
InnoDB引擎采用 Next-Key Locking 算法避免幻读,当执行 SELECT * FROM table WHERE id >= 1 FOR UPDATE 时,是对 [1, +∞) 这个范围加了X锁,因此对这个范围的插入都是不被允许的,从而避免幻读;
事务不同隔离级别,采取的加锁算法不同:
-
可重复读(REPEATABLE READ),采用 Next-Key Locking 方式加锁;
-
读已提交(READ COMMITTED),采用 Record Lock;
5、锁问题
5-1、脏读
脏读:事务对缓冲池中行记录的修改,并且还没有被提交;也就是,在不同事务下,当前事务可以读到另外事务未提交的数据;
脏读是指【未提交的】数据,如果读到脏数据,即一个事务可以读到【另一个事务】【未提交的】数据,违反了数据库的隔离性;
脏读出现在【事务隔离级别】设置为【读未提交(READ UNCOMMITTED)】;
5-2、不可重复读
不可重复读,是指在【一个事务内】【多次读取同一数据集合】,事务未结束时,另一事务访问该数据集合并做了DML操作并提交,在第一个事务中两次读数据之间,由于第二个事务修改,第一个事务中每次读到的数据可能不同;
不可重复读,违反了数据库【事务一致性】的要求;
不可重复读和脏读的区别:脏读是读到【未提交】的数据,不可重复读读到【已提交】的数据;
不可重复读 出现在【事务隔离级别】设置为【读已提交(READ COMMITTED)】;
InnoDB存储引擎中,通过使用 Next-Key Lock 算法 避免 【不可重复读】,MySQL官方将【不可重复读】定义为 Phantom Problem,即幻像问题;
在【 Next-Key Lock】算法下,对于索引扫描,不仅锁住扫描的索引,还锁住索引覆盖的范围(GAP),因此在这个范围内的插入都是不允许的,从而避免不可重复读问题;
5-3、丢失更新
丢失更新,一个事务的更新操作会被另一个事务的更新操作覆盖,从而导致数据不一致;
例如:
1)事务T1将 行记录R 更新为 V1,但事务T1 并未提交;
-
同时,事务T2 将 行记录R 更新为 V2,事务T2 未提交;
-
事务T1提交;
-
事务T2提交;
还有一种情况:
1)事务T1 查询一行数据,并返回界面给User1;
-
事务T2 查询同一行数据,并返回用户界面给User2展示;
-
User1修改这行记录,更新数据库并提交;
-
User2修改这行记录,更新数据库并提交;
User1修改的数据【丢失】了;
例如银行转账,账户A里有1万元,此时User1向另一个账户B转账9000,由于网络问题,需要等待;而User2向账户C转账1000,结果可能导致 账户余额是 9000,User1转账更新账户A的结果被User2的转账操作覆盖了;
要避免这种情况,最好将操作变成【串行化】;
6、阻塞
7、死锁
7-1、死锁的概念
死锁是指两个或两个以上的事务在执行过程中,因【争夺锁资源】而造成的一种【相互等待】的现象;
7-1-1、解决死锁问题的方法
1、不要有等待
将任何等待都回滚,并且事务重新开始;
优点:简单
缺点:
-
导致并发能力下降,甚至任何事务不能进行;
-
导致资源浪费;
2、超时
当两个事务互相等待时,当一个等待时间超过设置的阈值时,其中一个事务进行回滚,另一个事务就能继续执行;
在InnoDB引擎中,参数【innodb_lock_wait_timeout】用来设置超时时间;
缺点:
超时的事务权重比较大,事务更新行数多,占用较多的undo log,回滚该事务所占用时间可能会很多;
3、等待图(wait-for graph)
【等待图】比起【超时】的解决方案,是一种更为【主动的】死锁检测方式。
等待图要求数据库保存两个信息:
-
锁的信息链表
-
事务等待链表
通过上述链表可以构造出一张图,图中若存在【回路】,就代表存在死锁,因此资源间相互发生等待;
等待图中【边】的定义:
-
一个事务T1等待另一个事务T2所占用的资源;
-
一个事务T1【最终等待】另一个事务T2所占用的资源,也就是事务之间在等待【相同的资源】,而事务T1发生在事务T2后面;
总结:
-
【等待图】的【节点】由事务组成;
-
【等待图】的【边】:由事务等待被另一事务占用的相同资源,事务到另一事务存在一个边;
举例:
由上图看出,
-
当前存在4个事务,因此在【等待图】中有4个节点;
-
事务T2对Row1占X锁,事务T1对Row1占S锁,事务T1在T2之后,且需要等待T2释放资源,因此存在事务T1指向事务T2的边;
-
事务T2等待事务T1、T4占用的Row2,因此存在T2到T1、T4的边;
-
同样,T3也有到 T1、T2、T4 的边;
因此当前事务【等待图】如下:
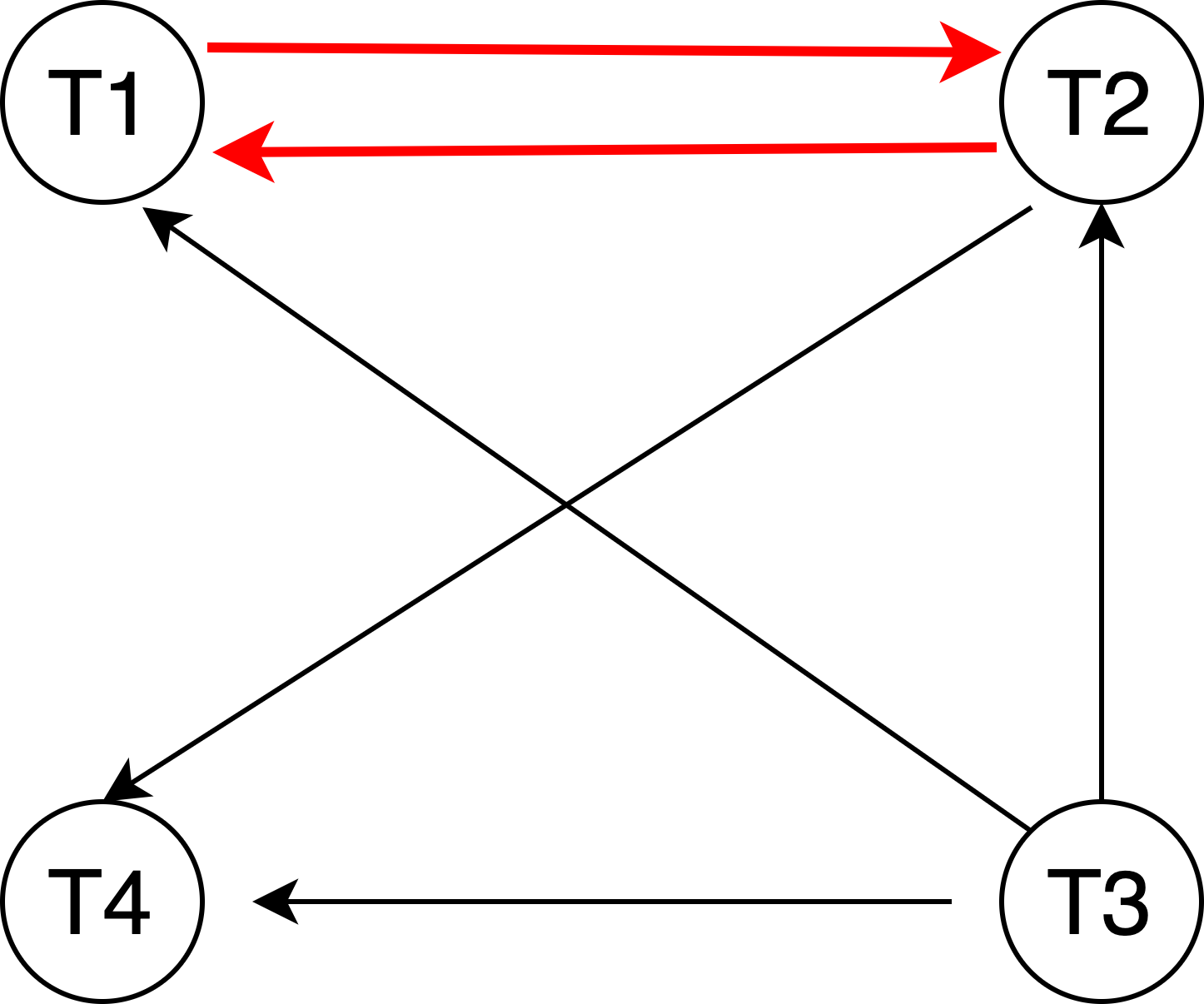
事务请求锁等待都会判断是否存在【回路】,若存在则有死锁;存储引擎选择回滚 undo 量最小的事务;
死锁检测采用【深度优先算法】实现;
7-1-2、死锁发生的概率
死锁发生的因素有:
-
系统中事务的数量,数量越多发生死锁的概率越大;
-
每个事务操作的数量,每个事务操作的数量越多,发生死锁的概率越大;
-
操作数据的集合,越小则发生死锁的概率越大;
