

❝「写在前面」:我是「云祁」,一枚热爱技术、会写诗的大数据开发猿。昵称来源于王安石诗中一句
❞[ 云之祁祁,或雨于渊 ],甚是喜欢。
写博客一方面是对自己学习的一点点总结及记录,另一方面则是希望能够帮助更多对大数据感兴趣的朋友。如果你也对数据中台、数据建模、数据分析以及Flink/Spark/Hadoop/数仓开发感兴趣,可以关注我 ,让我们一起挖掘数据的价值~
一、前言
之前写了篇面经 「《一个月面试近20家大中小厂,在互联网寒冬突破重围,成功上岸!》」,有不少小伙伴留言和私信我关于大数据学习路线,以及咨询我一些关于有工作经验想转行大数据的问题,只言片语也讲不清,我花了一个月整理了一份我当初学习的大数据学习路线,从最基础的大数据集群搭建开始,希望能帮助到大家。
不过在开始之前,我还是希望大家能想清楚,如果自己很迷茫,为了什么原因想往大数据方向发展,还有就是我就想问一下,你的专业是什么,对于计算机/软件,你的兴趣是什么?
是计算机专业,对操作系统、硬件、网络、服务器感兴趣? 是软件专业,对软件开发、编程、写代码感兴趣? 还是数学、统计学专业,对数据和数字特别感兴趣?
「欢迎大家在评论区留言讨论 ( •̀ ω •́ )✧」
这其实也就关系到大数据的三个发展方向:
- 平台搭建/优化/运维/监控
- 大数据开发/设计/架构
- 数据分析/挖掘
现如今,正式为了应对大数据的这几个特点,开源的大数据框架越来越多,越来越强,先列举一些常见的:
文件存储:Hadoop HDFS、Tachyon、KFS
离线计算:Hadoop MapReduce、Spark
流式、实时计算:Storm、Spark Streaming、Flink
K-V、NOSQL数据库:HBase、Redis、MongoDB
资源管理:YARN、Mesos
日志收集:Flume、Scribe、Logstash、Kibana
消息系统:Kafka、StormMQ、ZeroMQ、RabbitMQ
查询分析:Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Flink、Kylin、Druid
分布式协调服务:Zookeeper
集群管理与监控:Ambari、Ganglia、Nagios、Cloudera Manager
数据挖掘、机器学习:Mahout、Spark MLLib
数据同步:Sqoop
任务调度:Oozie
……
眼花了吧,上面的有30多种吧,别说精通了,全部都会使用的,估计也没几个。
「就我个人而言,主要目前是在第二个方向(开发/设计/架构),那我就从大数据的发展史讲起。由于自己经验有限,本文内容参考了圈内不少老师的观点,供大家参考和互相学习。」
二、大数据的发展史
关于大数据的发展史,我觉得「骆俊武老师」在《AI 时代,还不了解大数据?》一文中讲的非常清楚。大数据在它近三十年的发展史中,共经历了5个阶段。
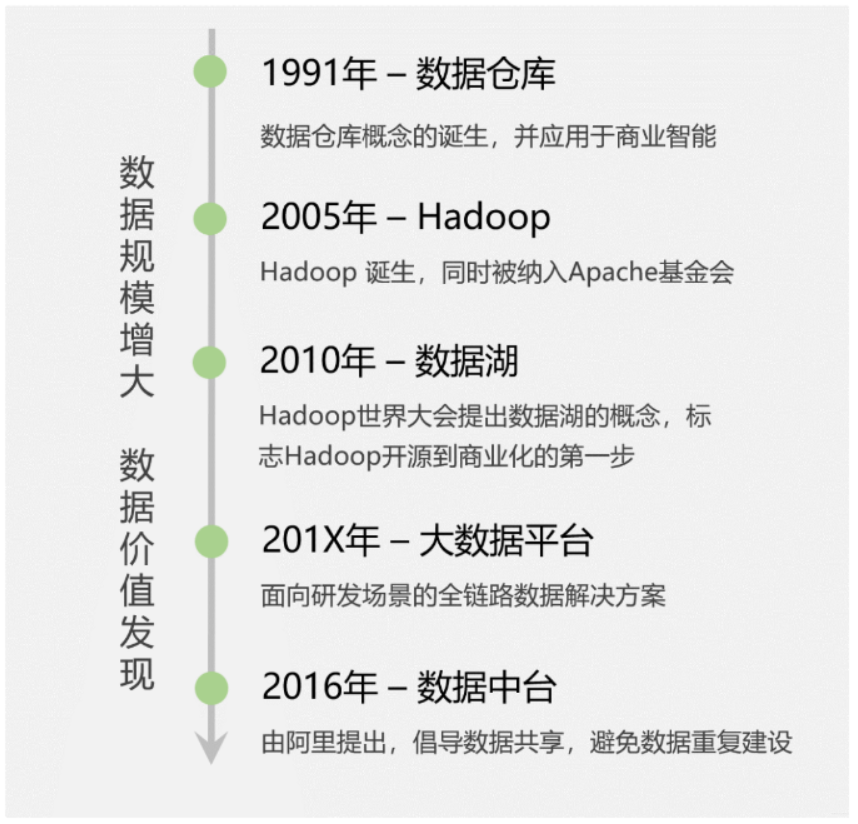
2.1 启蒙阶段:数据仓库的出现
20世纪90年代,商业智能(也就是我们熟悉的BI系统)诞生,它将企业已有的业务数据转化成为知识,帮助老板们进行经营决策。比如零售场景中:需要分析商品的销售数据和库存信息,以便制定合理的采购计划。
显然,商业智能离不开数据分析,它需要聚合多个业务系统的数据(比如交易系统、仓储系统),再进行大数据量的范围查询。而传统数据库都是面向单一业务的增删改查,无法满足此需求,这样就促使了数据仓库概念的出现。
传统的数据仓库,第一次明确了数据分析的应用场景,并采用单独的解决方案去实现,不依赖业务数据库。
2.2 技术变革:Hadoop诞生
 2000年左右,PC互联网时代来临,同时带来了海量信息,很典型的两个特征:
2000年左右,PC互联网时代来临,同时带来了海量信息,很典型的两个特征:
- 数据规模变大:Google、雅虎等互联网巨头一天可以产生上亿条行为数据。
- 数据类型多样化:除了结构化的业务数据,还有海量的用户行为数据,以图像、视频为代表的多媒体数据。
很显然,传统数据仓库无法支撑起互联网时代的商业智能。2003年,Google公布了3篇鼻祖型论文(「俗称「谷歌三驾马车」」),包括:分布式处理技术MapReduce,列式存储BigTable,分布式文件系统GFS。这3篇论文奠定了现代大数据技术的理论基础。
苦于Google并没有开源这3个产品的源代码,而只是发布了详细设计论文。2005年,Yahoo资助Hadoop按照这3篇论文进行了开源实现,这一技术变革正式拉开了大数据时代的序幕。
Hadoop相对于传统数据仓库,有以下优势:
- 完全分布式,可以采用廉价机器搭建集群,完全可以满足海量数据的存储需求。
- 弱化数据格式,数据模型和数据存储分离,可以满足对异构数据的分析需求。
随着Hadoop技术的成熟,2010年的Hadoop世界大会上,提出了「「数据湖」」的概念。
关于数据湖的理论,大家可以看我的这篇博客。
初探数据湖(Data Lake),到底有什么用?让我们来一窥究竟...
企业可以基于Hadoop构建数据湖,将数据作为企业的核心资产。由此,数据湖拉开了Hadoop商业化的大幕。
2.3 数据工厂时代:大数据平台兴起
商用Hadoop包含上十种技术,整个数据研发流程非常复杂。为了完成一个数据需求开发,涉及到数据抽取、数据存储、数据处理、构建数据仓库、多维分析、数据可视化等一整套流程。这种高技术门槛显然会制约大数据技术的普及。
此时,大数据平台(平台即服务的思想,PaaS)应运而生,它是面向研发场景的全链路解决方案,能够大大提高数据的研发效率,让数据像在流水线上一样快速完成加工,原始数据变成指标,出现在各个报表或者数据产品中。
2.4 数据价值时代:阿里提出数据中台
2016年左右,已经属于移动互联网时代了,随着大数据平台的普及,也催生了很多大数据的应用场景。
此时开始暴露出一些新问题:为了快速实现业务需求,烟囱式开发模式导致了不同业务线的数据是完全割裂的,这样造成了大量数据指标的重复开发,不仅研发效率低、同时还浪费了存储和计算资源,使得大数据的应用成本越来越高。
极富远见的马云爸爸此时喊出了「「数据中台」」的概念,「One Data,One Service」的口号开始响彻大数据界。「数据中台的核心思想是:避免数据的重复计算,通过数据服务化,提高数据的共享能力,赋能业务。」
关于阿里数据中台,可以参考这篇转载自「谭虎、陈晓勇老师」的:
三、大数据方面核心技术有哪些?
大数据的概念比较抽象,而大数据技术栈的庞大程度将让你叹为观止。
大数据技术的体系庞大且复杂,基础的技术包含数据的采集、数据预处理、分布式存储、NoSQL数据库、数据仓库、机器学习、并行计算、可视化等各种技术范畴和不同的技术层面。首先给出一个通用化的大数据处理框架,主要分为下面几个方面:「数据采集与预处理、数据存储、数据清洗、数据查询分析和数据可视化。」

- 「数据采集」:这是大数据处理的第一步,数据来源主要是两类,第一类是各个业务系统的关系数据库,通过Sqoop或者Cannal等工具进行定时抽取或者实时同步;第二类是各种埋点日志,通过Flume进行实时收集。
- 「数据存储」:收集到数据后,下一步便是将这些数据存储在HDFS中,实时日志流情况下则通过Kafka输出给后面的流式计算引擎。
- 「数据分析」:这一步是数据处理最核心的环节,包括离线处理和流处理两种方式,对应的计算引擎包括MapReduce、Spark、Flink等,处理完的结果会保存到已经提前设计好的数据仓库中,或者HBase、Redis、RDBMS等各种存储系统上。
- 「数据应用」:包括数据的可视化展现、业务决策、或者AI等各种数据应用场景。
四、大数据下的数仓体系架构
数据仓库是从业务角度出发的一种数据组织形式,它是大数据应用和数据中台的基础。数仓系统一般采用下图所示的分层结构。
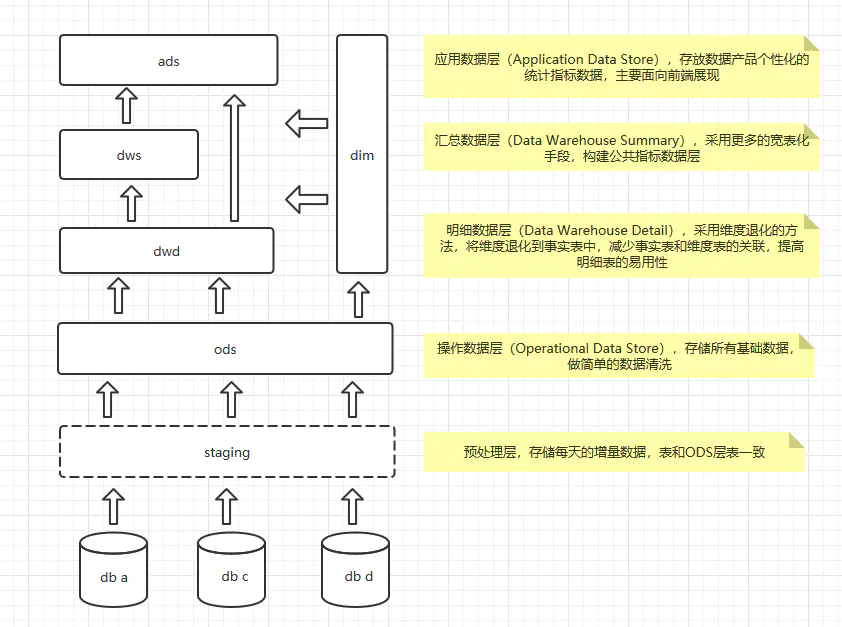
按照这种分层方式,我们的开发重心就在dwd层,就是明细数据层,这里主要是一些宽表,存储的还是明细数据;到了dws层,我们就会针对不同的维度,对数据进行聚合了,按道理说,dws层算是集市层,这里一般按照主题进行划分,属于维度建模的范畴;ads就是偏应用层,各种报表的输出了。
五、学习指南
首页,收下一本看书学习指南
「-------> 大数据开发工程师的成长之道 (整理自知乎)」
其次,阿里云大数据 ACA 和 ACP (两个是阿里云的大数据认证,值得一考!)
「-------> 阿里云大数据开发实践 系列专题 (又名我在阿里云的大数据开发之路 ) 」
下面,是我用阿里云的大数据开发组件设计的一套系统架构图和数仓分层模型图(具体的设计思路,有机会我会和大家再细说) 。
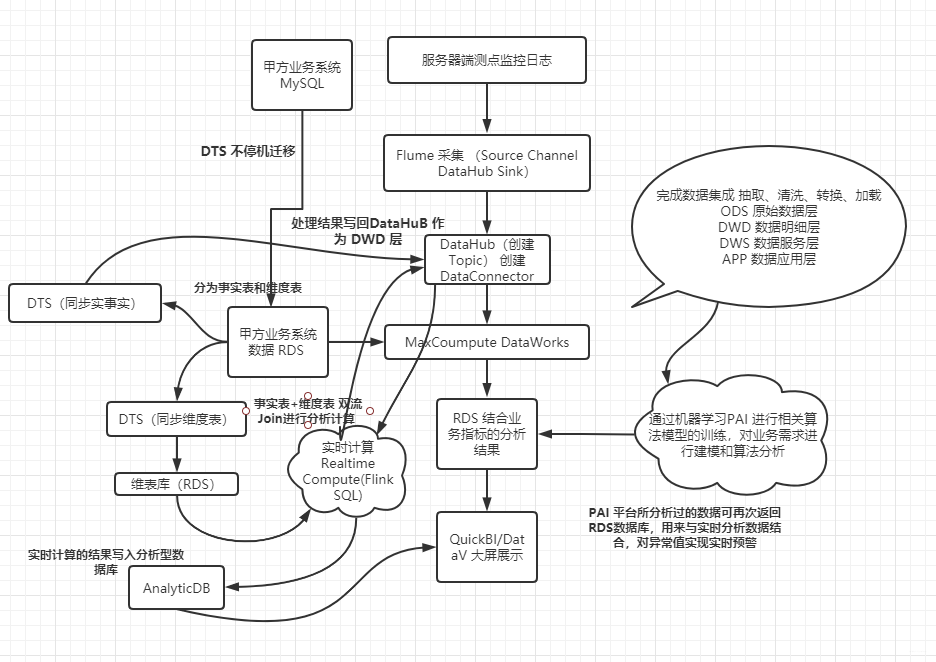

到这里,得强烈推荐阿里的这本书,「《大数据之路:阿里巴巴大数据实践》」 !精华大作啊!!
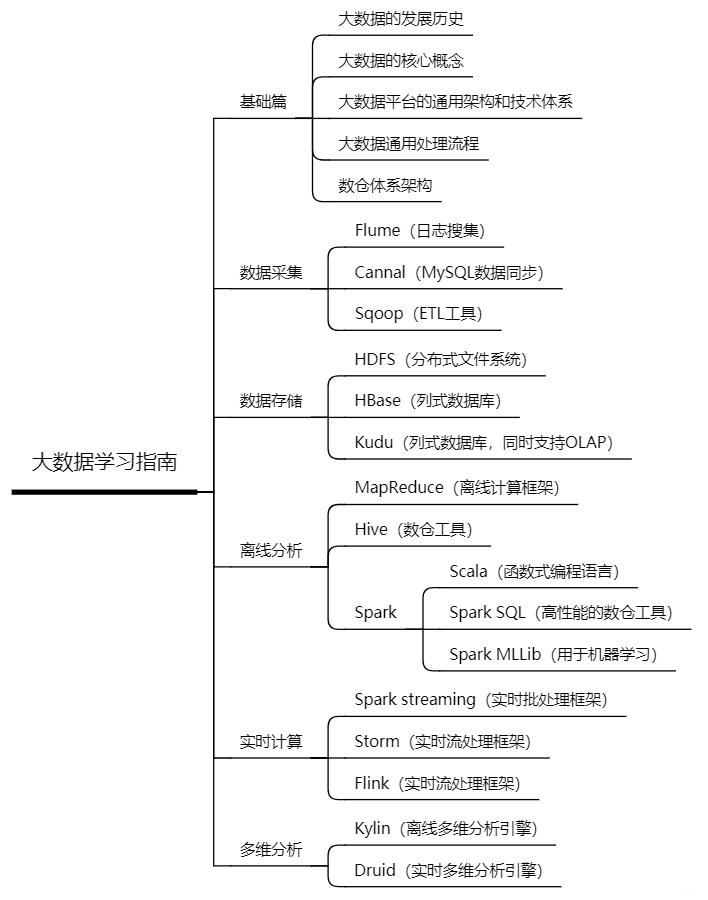
「然后,看下前辈整理的大数据开源框架学习指南(很详细,我偷懒不想画了つ﹏⊂)」
 写在最后,毕竟博主入行也就两年时间。然后对于一些小伙伴的问题,我尽量,针对不同的人给一些不同的建议。
写在最后,毕竟博主入行也就两年时间。然后对于一些小伙伴的问题,我尽量,针对不同的人给一些不同的建议。
「对应届生」
个人觉得应届生应该打好基础,大学本科一般都会开设数据结构,算法基础,操作系统,编译原理,计算机网络等课程。这些课程一定要好好学,基础扎实了学其他东西问题都不大,而且好多大公司面试都会问这些东西。如果你准备从事IT行业,这些东西对你会很有帮助。
至于学什么语言,我觉得对大数据行业来说,Java还是比较多。有时间有兴趣的话可以学学Scala,这个语言写Spark比较棒。
集群环境一定要搭起来。有条件的话可以搭一个小的分布式集群,没条件的可以在自己电脑上装个虚拟机然后搭一个伪分布式的集群。一来能帮助你充分认识Hadoop,而来可以在上面做点实际的东西。你所有踩得坑都是你宝贵的财富。
然后就可以试着写一些数据计算中常见的去重,排序,表关联等操作。
然后我有个小伙伴,今年某211大数据专业毕业,刚来杭州实习两周就上线了两个数仓的任务了,我奉他为( ﹁ ﹁ ) ~→最强实习生(他和我得瑟,比他早来的实习生还在打杂...),哈哈哈。
「对有工作经验想转行的」
主要考察三个方面,一是基础,二是学习能力,三是解决问题的能力。
基础很好考察,给几道笔试题做完基本上就知道什么水平了。
学习能力还是非常重要的,毕竟写Javaweb和写Mapreduce还是不一样的。大数据处理技术目前都有好多种,而且企业用的时候也不单单使用一种,再一个行业发展比较快,要时刻学习新的东西并用到实践中。
解决问题的能力在什么时候都比较重要,数据开发中尤为重要,我们同常会遇到很多数据问题,比如说最后产生的BI数据对不上,一般来说一份最终的数据往往来源于很多原始数据,中间又经过了N多处理。要求你对数据敏感,并能把握问题的本质,追根溯源,在尽可能短的时间里解决问题。
基础知识好加强,换工作前两周复习一下就行。学习能力和解决问题的能力就要在平时的工作中多锻炼。社招的最低要求就上面三点,如果你平日还自学了一些大数据方面的东西,都是很好的加分项。
以上是个人的一些经历和见解,希望能帮到你 「(๑•̀ㅂ•́)و✧」。
❝我是「云祁」,一枚热爱技术、会写诗的大数据开发猿,欢迎关注我的公众号 [云祁QI],Love&Peace!
❞
