

Spring
Spring设计模式
-
工厂设计模式 : Spring使用工厂模式通过 BeanFactory、ApplicationContext创建 bean 对象。
-
代理设计模式 : Spring AOP 功能的实现。
-
单例设计模式 : Spring 中的 Bean 默认都是单例的。
-
模板方法模式 : Spring 中 jdbcTemplate、hibernateTemplate等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。
-
包装器设计模式 : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
-
观察者模式: Spring 事件驱动模型就是观察者模式很经典的一个应用。
-
适配器模式 :Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配Controller。
FactoryBean和BeanFactory区别
BeanFactory:ApplicationContext父类,负责生产和管理Bean对象
FactoryBean:通过实现该接口定制实例化Bean的逻辑,代理一个Bean对象,对方法前后做一些操作
spring解决循环依赖的原理
三级缓存,能够提前拿到未完成初始化的对象的引用
无法解决
1、构造器循环依赖
2、setter循环依赖--非单例
可以解决
1、setter循环依赖
Spring Bean 生命周期
-
初始化bean信息
-
如果Bean实现了xxxAware接口,获得beanFactory或者applicationContext等一些配置
-
如果有Bean实现了BeanPostProcessor接口,则会回调该接口的postProcessBeforeInitialzation()和postProcessAfterInitialization方法,
-
如果Bean配置了init-method方法,则会执行init-method配置的方法,
-
容器关闭后,如果Bean实现了DisposableBean接口,则会回调该接口的destroy()方法,
-
如果Bean配置了destroy-method方法,则会执行destroy-method配置的方法,至此,整个Bean的生命周期结束
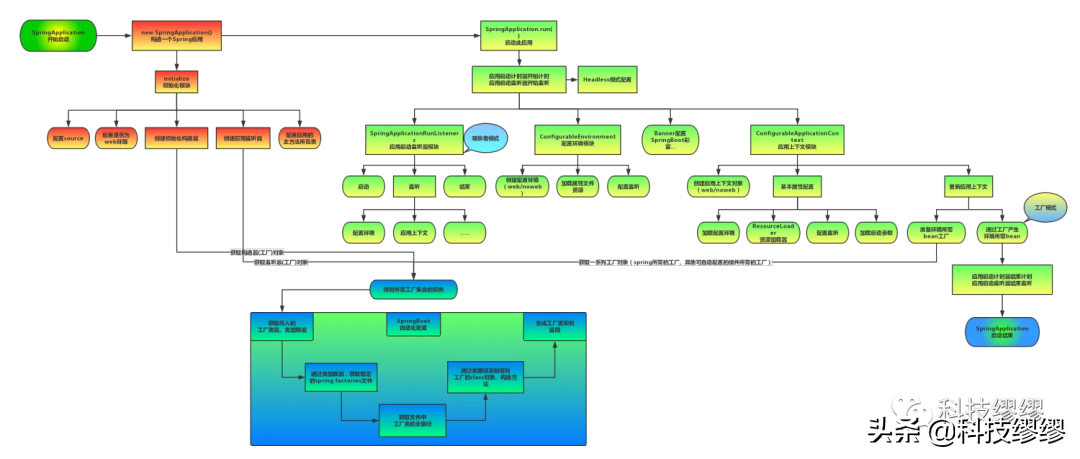
SpringBoot启动流程
IOC AOP区别以及原理
反射创建类,通过声明管理,依赖注入来实现代码层面的解耦
IOC DI
声明管理:@Component @Service @Repository @Controller
声明注入:@Autowire @Resource @Qualifier
AOP(日志记录、异常处理、事务处理)
实现方式:动态代理 jdk-proxy cglib aspectj
注解
@Aspect 当前类作为一个切面容器
@Pointcut advice的触发条件 (execution(* cn.oyo.trade.starter.provider...(..)))
@Before @After @Around @AfterReturning
jdk动态代理和cglib代理区别
JDK动态代理:类实现了某个接口的,spring aop会使用jdk动态代理,生成一个实现同样接口的一个代理类,构造实例对象
cglib:某个类没有实现接口,spring aop会改用cglib生成动态代理,生成一个子类,动态生成字节码,覆盖一些方法,在方法里加入增强的代码
Spring事务实现原理,事务传播机制
-
PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置。
-
PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。‘
-
PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
-
PROPAGATION_REQUIRES_NEW:创建新事务,无论当前存不存在事务,都创建新事务。
-
PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
-
PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
-
PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则按REQUIRED属性执行。
几种限流算法,优缺点
计数器:简单计数,无需多说
令牌桶:恒定的速度生成令牌,控制最大请求速率,桶里有令牌则可以请求
漏斗:固定桶,请求速率不恒定,最后请求服务器的速率是恒定的
滑动窗口:细分的计数器,分为多个时间段,每个时间段的请求数量不能超限,划分越细,结果越精确
Sentinel和Hystrix选型
熔断降级:都基于失败比率 异常比率熔断降级,超过比例自动熔断
限流:都基于滑动窗口
隔离:
1、Hystrix 线程池隔离(造成线程数过多)+信号量隔离(限制资源并发数,轻量,无法自动降级,只能等待客户端超时)
2、Sentinel 并发线程数流量提供信号隔离(可以在响应时间高时候自动降级)
Sentinel:
1、轻量,不到200K
2、系统负载保护
3、实时监控、控制面板
4、生态 配置简单dubbo、springboot
Dubbo
Dubbo分层
-
接口层 服务提供者和消费者来实现
-
配置层 dubbo各种配置
-
服务代理层 provider consumer生成代理对象,代理之间进行网络通信
-
服务注册层 provider注册,服务注册与发现
-
集群层 封装多个provider路由以及负载均衡
-
监控层 rpc调用次数和时间等的监控
-
远程调用层 封装rpc调用
-
信息交换层 封装请求响应模式,同步转异步
-
网络传输层 抽象mina和netty为统一接口
-
数据序列化层
工作原理
-
provider 向注册中心去注册
-
consumer 从注册中心订阅服务,注册中心会通知 consumer 注册好的服务
-
consumer 调用 provider
-
consumer 和 provider 都异步通知监控中心
通信协议
-
dubbo协议 长连接
-
rmi协议 短连接
-
hessian 短连接
负载均衡策略
-
随机负载 默认,设置权重,权重越大,分配流量越高
-
roundrobin 均匀流量
-
leastactive 自动感知,机器性能越差,接收请求越少
-
一致性hash
相同参数的请求一定分发到一个 provider 上去,provider 挂掉的时候,会基于虚拟节点均匀分配剩余的流量,抖动不会太大
服务治理、降级、重试
服务治理
1、调用链路跟踪
2、Cat调用时长、次数、接口调用成功率
降级
1、Mock
zookeeper
Leader选举
1、每个 server 发出一个投票:投票的最基本元素是(SID-服务器id,ZXID-事物id)
2、接受来自各个服务器的投票
3、处理投票:优先检查 ZXID(数据越新ZXID越大),ZXID比较大的作为leader,ZXID一样的情况下比较SID
4、统计投票:这里有个过半的概念,大于集群机器数量的一半,即大于或等于(n/2+1),我们这里的三台,大于等于2即为达到“过半”的要求。
5、改变服务器状态:一旦确定了 leader,服务器就会更改自己的状态,且一般不会再发生变化,比如新机器加入集群、非 leader 挂掉一台
消息广播过程
zab协议 Zookeeper Atomic Broadcast 原子性广播协议
所有的客户端请求都会转发至Leader服务器,Leader服务器顺序执行
-
Leader 服务器将客户端的请求转化为事务 Proposal 提案,同时为每个 Proposal 分配一个全局的ID,即zxid。
-
Leader 服务器为每个 Follower 服务器分配一个单独的队列,然后将需要广播的 Proposal 依次放到队列中去,并且根据 FIFO 策略进行消息发送。
-
Follower 接收到 Proposal 后,会首先将其以事务日志的方式写入本地磁盘中,写入成功后向 Leader 反馈一个 Ack 响应消息。
-
Leader 接收到超过半数以上 Follower 的 Ack 响应消息后,即认为消息发送成功,可以发送 commit 消息。
-
Leader 向所有 Follower 广播 commit 消息,同时自身也会完成事务提交。Follower 接收到 commit 消息后,会将上一条事务提交。
崩溃恢复
1、选举:选举准Leader
2、发现:在这个阶段,Followers 和上一轮选举出的准 Leader 进行通信,同步 Followers 最近接收的事务 Proposal
3、同步阶段:同步阶段主要是利用 Leader 前一阶段获得的最新 Proposal 历史,同步集群中所有的副本。只有当 quorum(超过半数的节点) 都同步完成,准 Leader 才会成为真正的 Leader
4、广播阶段:即上述消息广播
Zookeeper 和 Eureka 区别
Zookeeper保证CP,Eureka保证AP:
-
C:数据一致性;
-
A:服务可用性;
-
P:服务对网络分区故障的容错性,这三个特性在任何分布式系统中不能同时满足,最多同时满足两个。
zookeeper只能保证C的原因
1、不能保证每次服务请求的可用性
2、极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果
3、进行leader选举时集群都是不可用,在使用ZooKeeper获取服务列表时,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的。
