什么是flashtext算法
Flashtext算法是一个高效的字符搜索和替换算法。
该算法的时间复杂度不依赖于搜索或替换的字符的数量。
比如,对于一个文档有 N 个字符,和一个有 M 个词的关键词库,那么时间复杂度就是O(N),与M没有关系。
这个算法比正则匹配法快很多,因为正则匹配的时间复杂度是 O(M * N)。
Flashtext算法被设计为只匹配完整的单词,而不匹配单词内的子字符串。
这个算法也被设计为首先匹配最长字符串。
比如,我们输入一个单词Apple,那么flashtext算法就不会去匹配“I like Pineapple”中的apple。
再举个例子,比如我们有这样一个数据集 {Machine, Learning,Machine Learning},
一个文档“I like Machine Learning”,那么我们的算法只会去匹配 “Machine Learning”,因为这是最长匹配。
1/介绍
在信息检索领域,字符搜索和替代都是很常见的问题。
我们经常想要在一个特定的文本中搜索特定的关键词,或者在文本中替代一个特定的关键词。
1.例如:
<1>字符搜索的应用场景
假设我们有一份软件工程师的简历,
我们拥有一个20k的编程技巧词库:
corpus = {Java, python, javascript, machien learning, …}。
我们想知道词库corpus中的哪些词出现在了简历中
<2>字符替换的应用场景
当我们有一个同义词的语料库(不同的拼写表示的是同一个单词),
比如 corpus = {javascript: [‘javascript’,‘javascripting’,‘java script’], …} ,
在简历中我们需要使用标准化的词,所有我们需要用一个标准化的词来替换不同简历中的同义词。
2.为了去解决上述这些问题,正则表达式是最常用的一个技术。
虽然正则表达式可以很好的解决这个问题,但是当我们的数据量增大时,这个速度就会非常慢了。
如果我们的文档达到百万级别时,那么这个运行时间将达到几天的量级。
3.随着我们需要处理的字符越来越多,正则表达式的处理速度几乎都是线性增加的。
然而,Flashtext几乎是一个常量。
2/Flashtext
Flashtext是一种基于 Trie 字典数据结构和 Aho Corasick 的算法。
它的工作方式是,首先它将所有相关的关键字作为输入。使用这些关键字建立一个 trie 字典,如下图所示:
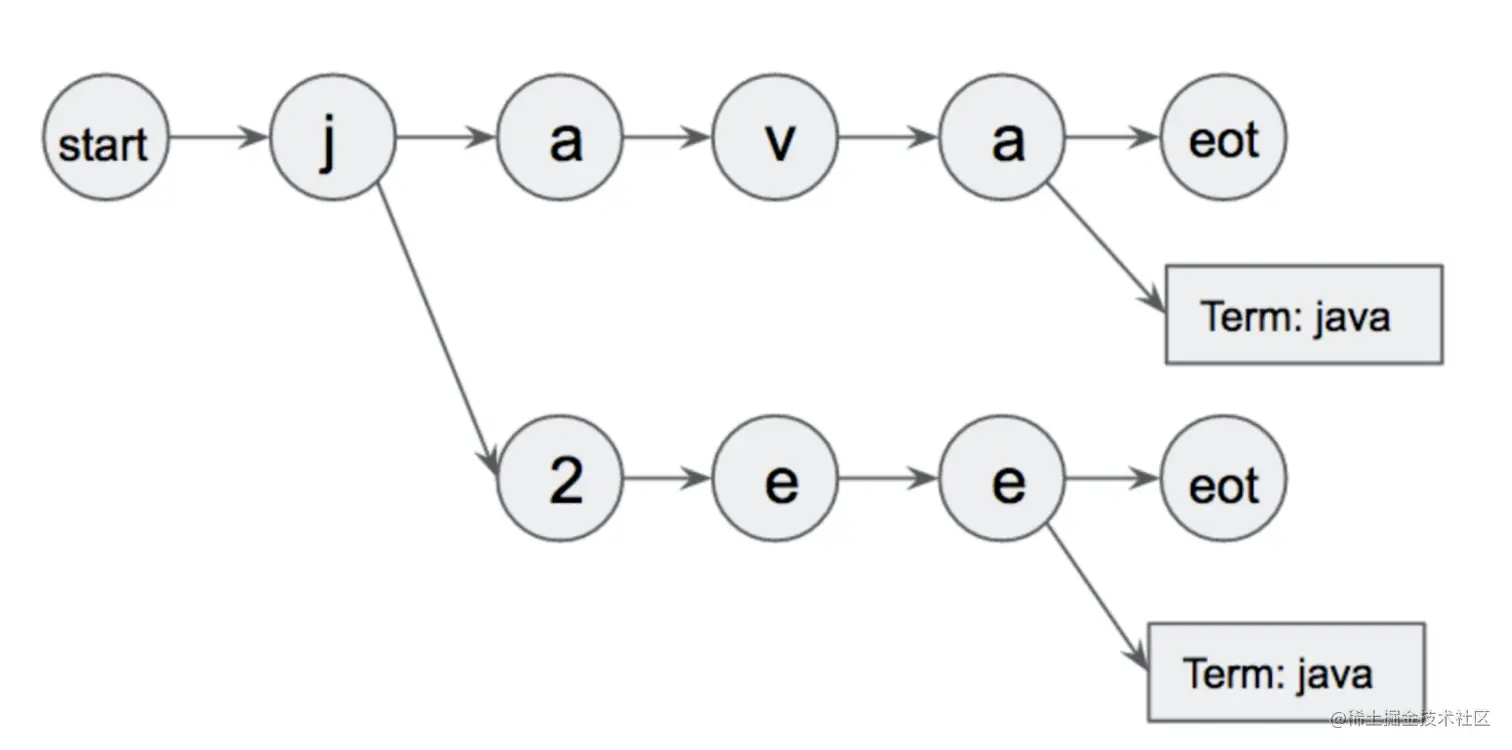
start和eot是两个特殊的字符,用来定义词的边界,这和我们上面提到的正则表达式是一样的。
这个 trie 字典就是我们后面要用来搜索和替换的数据结构。
<1>利用Flashtext进行搜索
对于输入字符串(文档),我们对字符进行逐个遍历。
当我们在文档中的字符序列 <\b>word<\b> 匹配到字典中的word时(start和eot分别是字符序列的开始标签和结束标签),
我们认为这是一个完整匹配了。
我们将匹配到的字符序列所对应的标准关键字进行输出,具体如下:
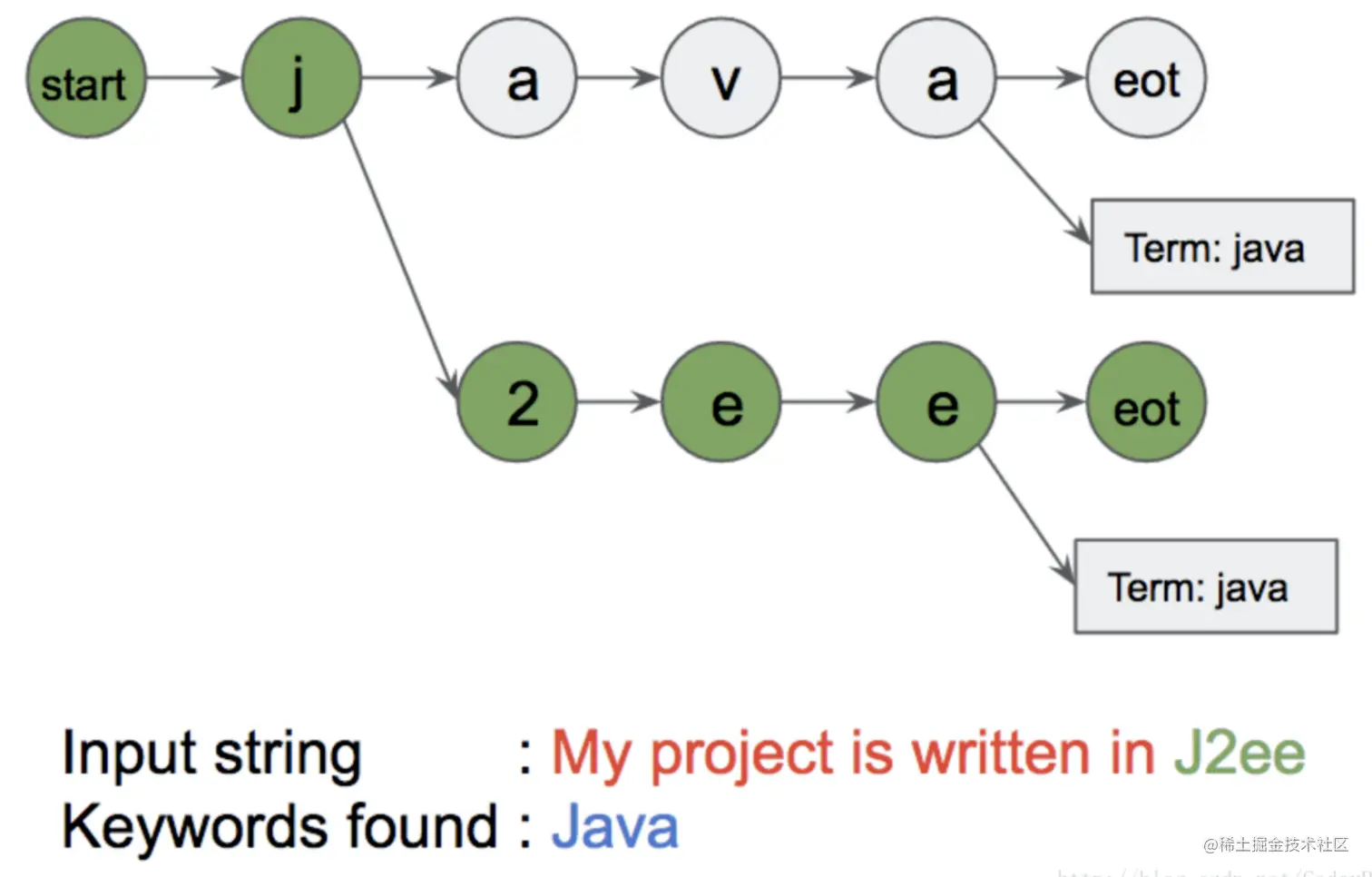
<2>利用Flashtext进行替换
对于输入字符串(文档),我们对字符串进行逐个遍历。
我们先创建一个空的字符串,当我们字符序列中的 <\b>word<\b> 无法在Trie字典中找到匹配时,
那么我们就简单的原始字符复制到返回字符串中。
但是,当我们可以从Trie字典中找到匹配时,那么我们将将匹配到的字符的标准字符复制到返回字符串中。
因此,返回字符串是输入字符串的一个副本,唯一的不同是替换了匹配到的字符序列,
具体如下:
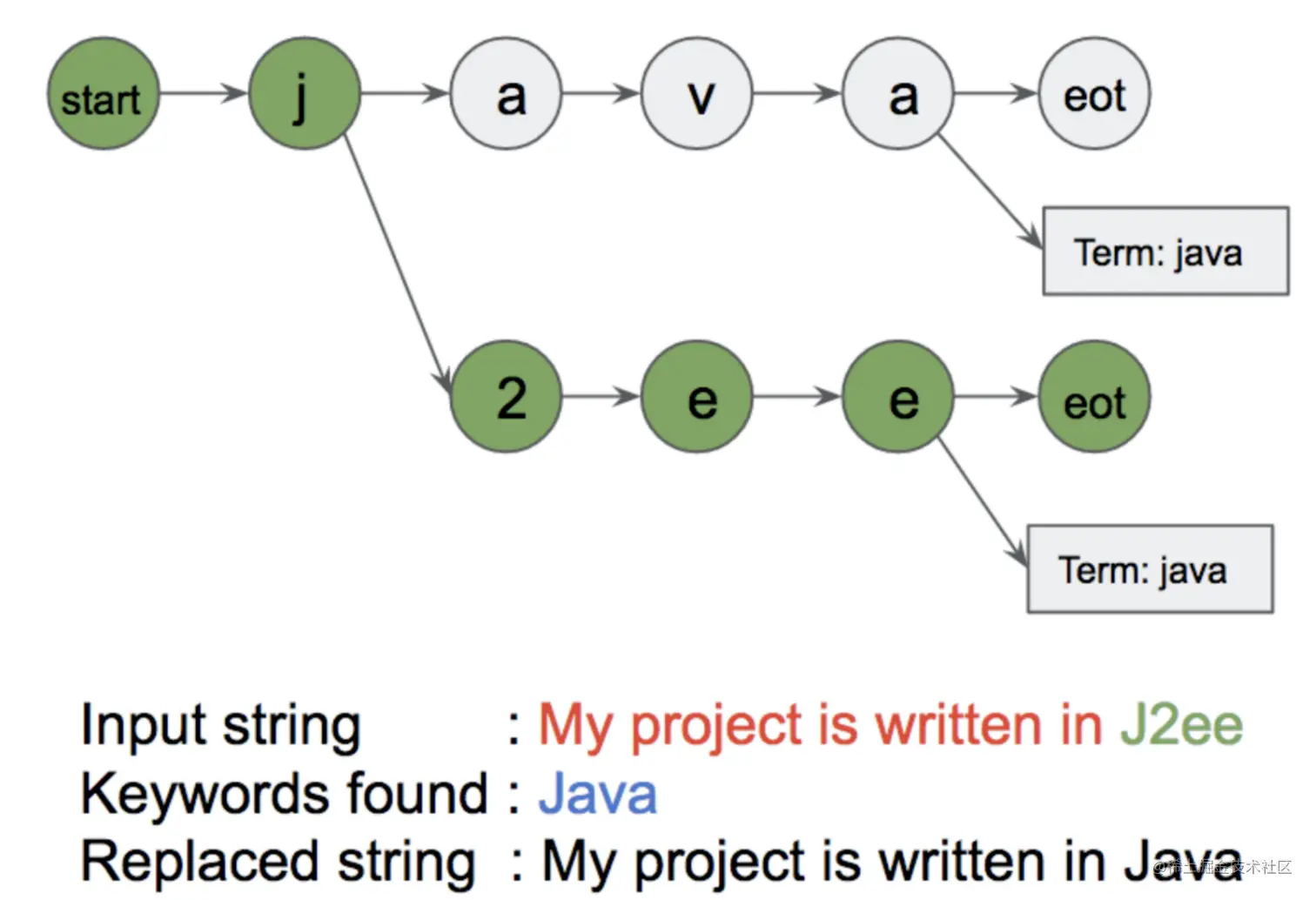
如何使用flashtext
<1>提取关键字
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
str = 'I love Big Apple and Bay Area.'
keywords_found = keyword_processor.extract_keywords(str)
print( keywords_found )
<2>关键字替换
keyword_processor.add_keyword('New Delhi', 'NCR region')
str = 'I love Big Apple and new delhi.'
new_str = keyword_processor.replace_keywords(str)
print( new_str )
<3>区分大小写字母
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor(case_sensitive=True)
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
str = 'I love big Apple and Bay Area.'
keywords_found = keyword_processor.extract_keywords(str)
print( keywords_found )
<4>关键字不清晰
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple')
keyword_processor.add_keyword('Bay Area')
str = 'I love big Apple and Bay Area.'
keywords_found = keyword_processor.extract_keywords(str)
print( keywords_found )
<5>同时添加多个关键词
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_dict = {
"java": ["java_2e", "java programing"],
"product management": ["PM", "product manager"]
}
keyword_processor.add_keywords_from_dict(keyword_dict)
keyword_processor.add_keywords_from_list(["java", "python"])
keyword_processor.extract_keywords('I am a product manager for a java_2e platform')
<6>删除关键字
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_dict = {
"java": ["java_2e", "java programing"],
"product management": ["PM", "product manager"]
}
keyword_processor.add_keywords_from_dict(keyword_dict)
print(keyword_processor.extract_keywords('I am a product manager for a java_2e platform'))
keyword_processor.remove_keyword('java_2e')
keyword_processor.remove_keywords_from_dict({"product management": ["PM"]})
keyword_processor.remove_keywords_from_list(["java programing"])
keyword_processor.extract_keywords('I am a product manager for a java_2e platform')
<7>有时候我们会将一些特殊符号作为字符边界,比如 空格,\ 等等。
为了重新设定字边界,我们需要添加一些符号告诉算法,这是单词字符的一部分。
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple')
print(keyword_processor.extract_keywords('I love Big Apple/Bay Area.'))
keyword_processor.add_non_word_boundary('/')
print(keyword_processor.extract_keywords('I love Big Apple/Bay Area.'))


