在最近的工作中经常会遇到一些sql的慢查询,这个时候我们就会接触到一些mysql的优化,而在mysql的优化中,mysql的索引也是重要的一环,今天我们就简单的聊一下mysql的索引。
一. mysql索引的介绍
首先,在认识一个新的知识点的时候,还是老办法:是什么;为什么;怎么样三部曲。索引是什么呢?通俗的说,如果把mysql比如成书的话,那他就是这本书的目录。同时索引就是帮助mysql高效获取数据的排好序的数据结构。所以,索引其实就是数据结构。
二.mysql索引的数据结构
接下来就是聊一下为什么了,为什么要是用索引呢?通常我们在使用select语句的时候,如果没有添加索引,mysql会根据你select的条件,表的上面往下面来查找,直到查找到目标。当你的表里数据很多的时候,你查找的时间就会变的很长。这个问题是不是也在业务中遇到过,如果在业务中,我们使用二分查找就会变的很快。前面说到索引是一种数据结构,那能实现二分查找的数据结构是不是就是二叉树。如下图所示:
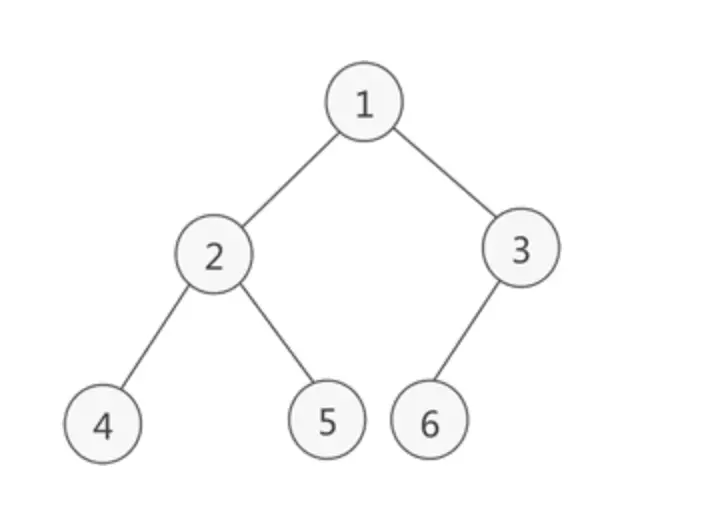
如果使用二叉树是不是就解决了我们很多问题。在这里说一句,索引的数据结构不是二叉树,但为什么在这里说二叉树呢,是为了更好的推导,回到之前的三部曲中的第二个,为什么,为什么索引的数据结构是B+Tree。前面说到二叉树能解决大量的时间,但是这个时候有问题就出来了,因为二叉树遵循右边比左边大,如果我们的索引是递增的,那二叉树就变成了一个链表,如下图所示:
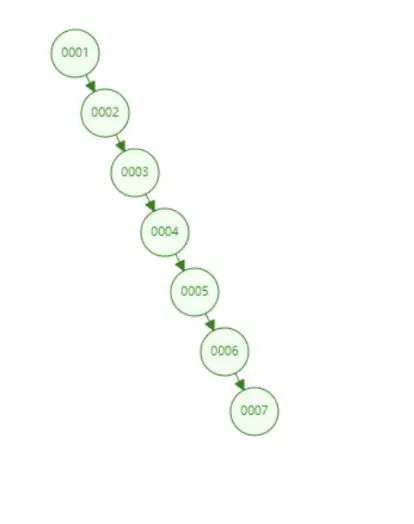
这个时候查找的效率又变回去了,如何解决二叉树单边过长的问题呢?这个时候一个新的数据结构-红黑树就能解决这个问题,如下图:
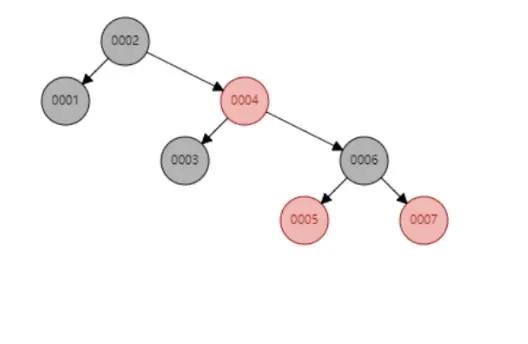
红黑树其实也就是二叉平衡树,他使二叉树以中心为节点尽量的左右平衡。那为什么最终索引不是使用红黑树作为数据结构呢?我们想象一下如果我们的索引越来越多的时候,成千上万的时候,这个时候我们红黑树的深度是不是就变得特别的深,如果我们查找的索引在红黑树很深的深度的时候,那我们耗费的时间是不是就会变的很长。比如双十一的时候,即使我们使用前端页面静态化,给其他的服务降级,部署多台服务器,一个请求也会耗费很长的时间,同时也会让用户的体验变得很差。那怎么解决这个问题呢?有没有一个数据结构遵循红黑树的同时,他的深度也不是很深。答案肯定是有的,那就是B-Tree。如下图所示:
同时也被别人称为多节点平衡树。二叉树一个节点的下面只有两个节点,而B-Tree每个节点下面有多个节点,所以他能很好的解决这个问题。但为什么索引最终没有使用B-Tree而是使用B+Tree呢?B+Tree如下图:
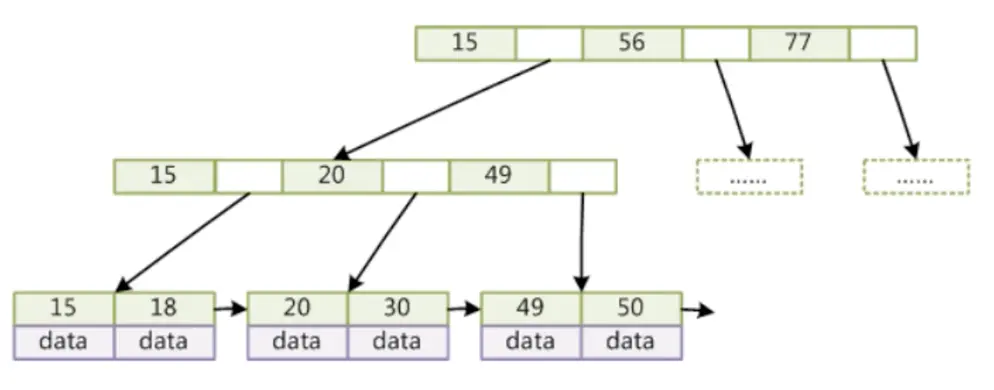
我们可以想象一下如果使用B-Tree,他每个节点上面都存储了索引指针和其所在行的data数据,这个时候当我们的内存去加载这些层级的时候,服务器是不是就会特别的占用内存。在java中有抽取的思想,那我们可不可以把除最底层之外的层级里的data数据抽取出来,放到最后一层,让最后一层以全量的数据呈现呢?这样是不是变得更加的便捷。顺着这个思路,如果我们除最底层以外的层级是不是索引指针越多越好呢?答案显然不是的,而索引对其也有约束,对于除最后一个层级之外的层级,索引对大小规定为16KB,而在java的数据库中每个索引最小占几个字节呢?通过对数据库的操作,发现是8个字节。除了索引占用的字节外,还有对下个层级的指针占6个字节,加在一起相当于一个索引占用14个字节,把16KB除以14个B之后就是每个的层级的索引的个数数量-1170个。如果是三层的B+Tree的话,那就能支持千万的数据。
三.搜索引擎-myisam(非聚集)
前面我们介绍到索引的数据结构,在平时的工作中,会有多个索引联合查询,而这个时候就需要用到mysql索引的搜索引擎,这个时候我们就疑问搜索引擎是什么呢?在探究这个问题之前,我们首先要了解mysql的存储过程,然后明白这个搜索引擎在其中担任的角色。我们先搞清楚一个问题,搜索引擎是作用在库还是在表上面,我们可以先使用navicat创建一个test库,然后再在这个库里面创建几张表,在新建表的时候,我们就会有如下的一些选项:
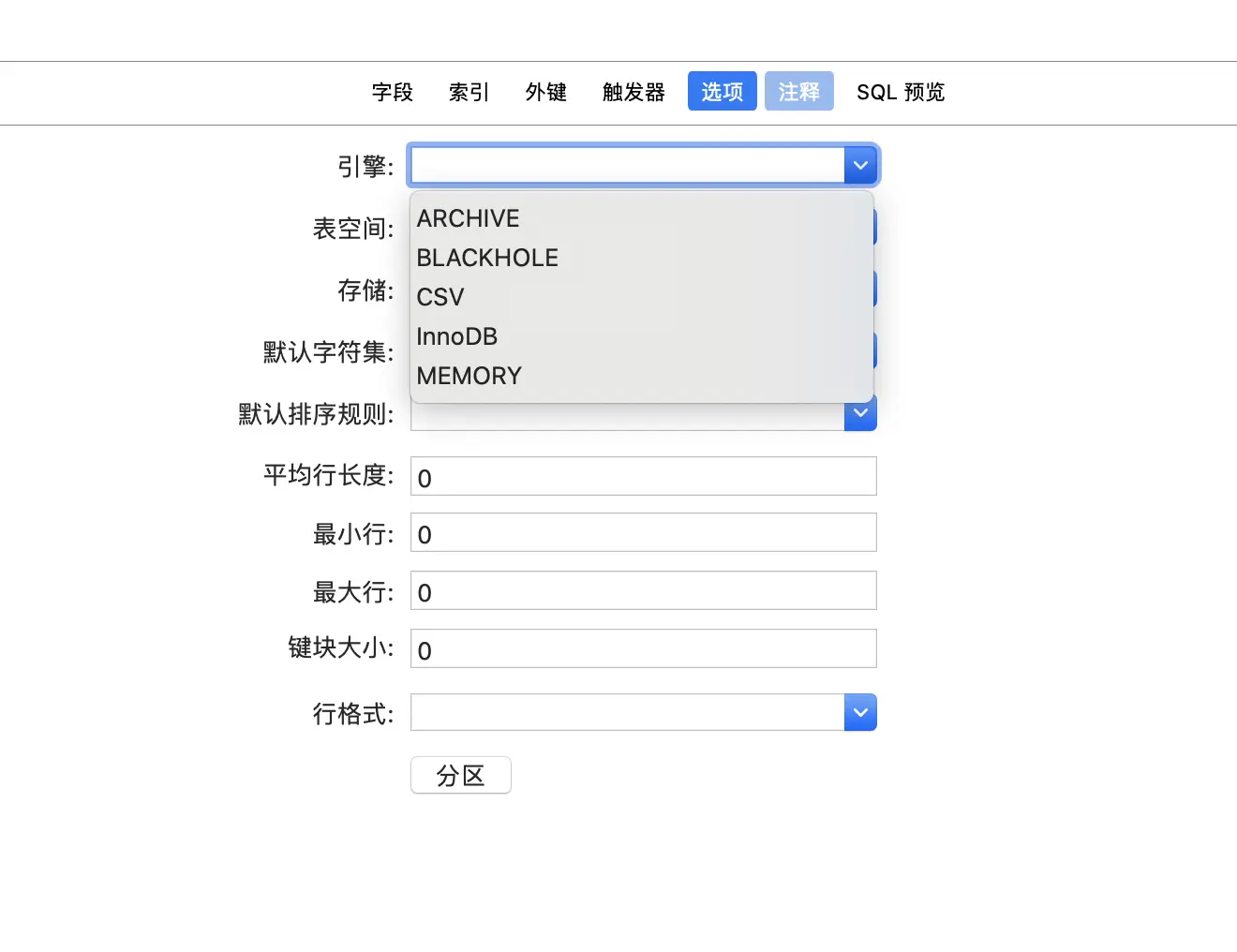
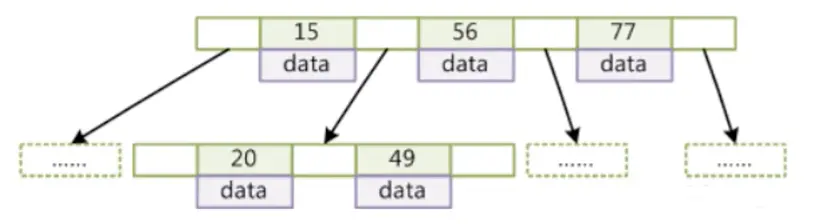
从选项中就能看出引擎是直接作用在表上面的,创建完不同的搜索引擎后,我们再打开mysql存储的文件去查看他们之间的差异,打开mysql下的data下的test库的文件夹就能看到表的存储文件了,使用myisam创建的表,你会发现有三个文件,一个是frm结尾、一个是MYD结尾,另一个是MYI结尾。大部分的mysql里以frm结尾的都是这张表的表结构,MYD也就是myisam-data的缩写,里面存储的就是data数据,而MYI毫无疑问就是myisam-index存储的索引的数据,如下图所示:
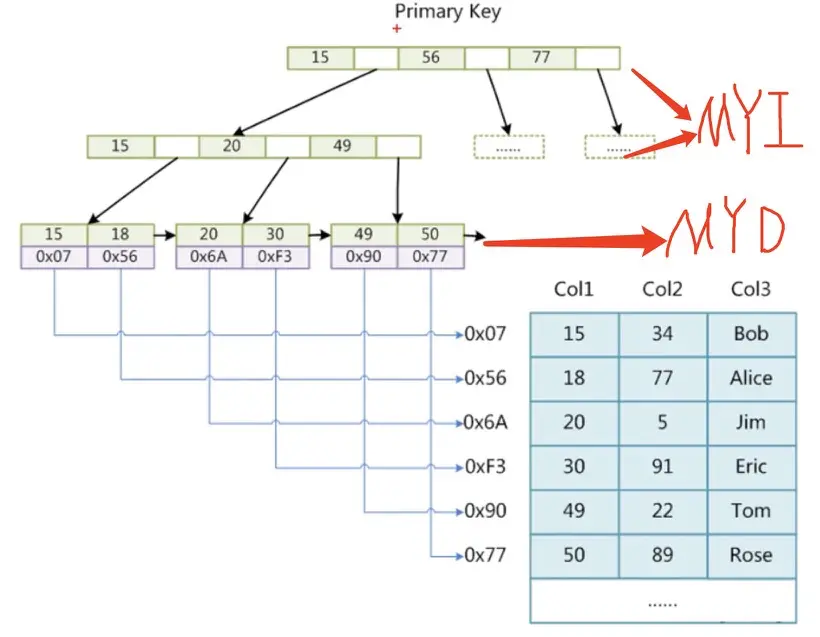
我们再回顾一下之前所说的索引的数据结构及其查找,如果上图的Col1是索引的话,sql语句的where条件进行索引查找的时候,会先在MYI的文件里去查找这个索引,然后进过上图的第一层的指针继续往下查找,查找到第三层的时候,会根据索引的指针查找到当前索引所在行在磁盘上的位置,最后会在MYD的文件里查找。(这里补充一下为什么上图的最后一层会有箭头的指针,因为索引的数据结构除了B+Tree之外还有hash,而hash的存储是散列,散列的单项查找的性能要比B+Tree高太多,所以B+Tree的最后一层的指针是为了索引的范围性查找服务的。)
四.搜索引擎-innodb(聚集)
当我们打开innodb创建的表在mysql里的存储文件的时候,会发现只有两个文件,一个是以frm结尾的,另一个是idb结尾的,前面我们说到frm是形容表结构的,而idb是什么呢?当我们打开这个文件的时候,发现其就是把myisam搜索引擎里的MYD和MYI整合在一起,如下图所示:
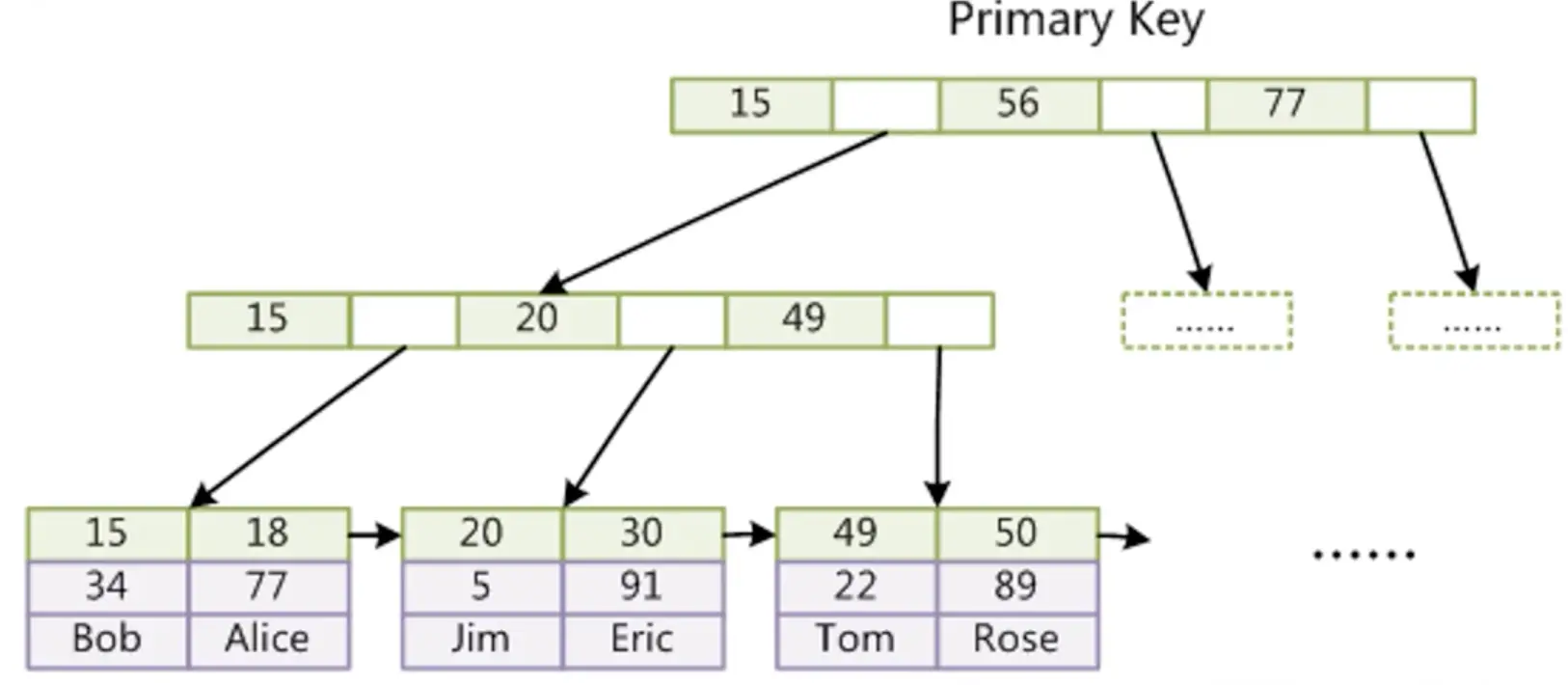
idb文件本身就是按照B+Tree组织的一个索引结构文件。所以在创建innodb的时候,一定要有主键。并且innodb推荐整数类型自增长。
五.面试总结
- 为什么全文索引是使用myisam?
- 什么是聚集索引?什么是非聚集索引?
- 索引为什么失效了?
- 为什么innodb推荐整数类型自增长?
- 为什么使用索引?
- MySQL索引底层使用什么数据结构?
- 什么是回表?
- 什么是覆盖索引?
- 等一些mysql优化策略


