

二叉树基础
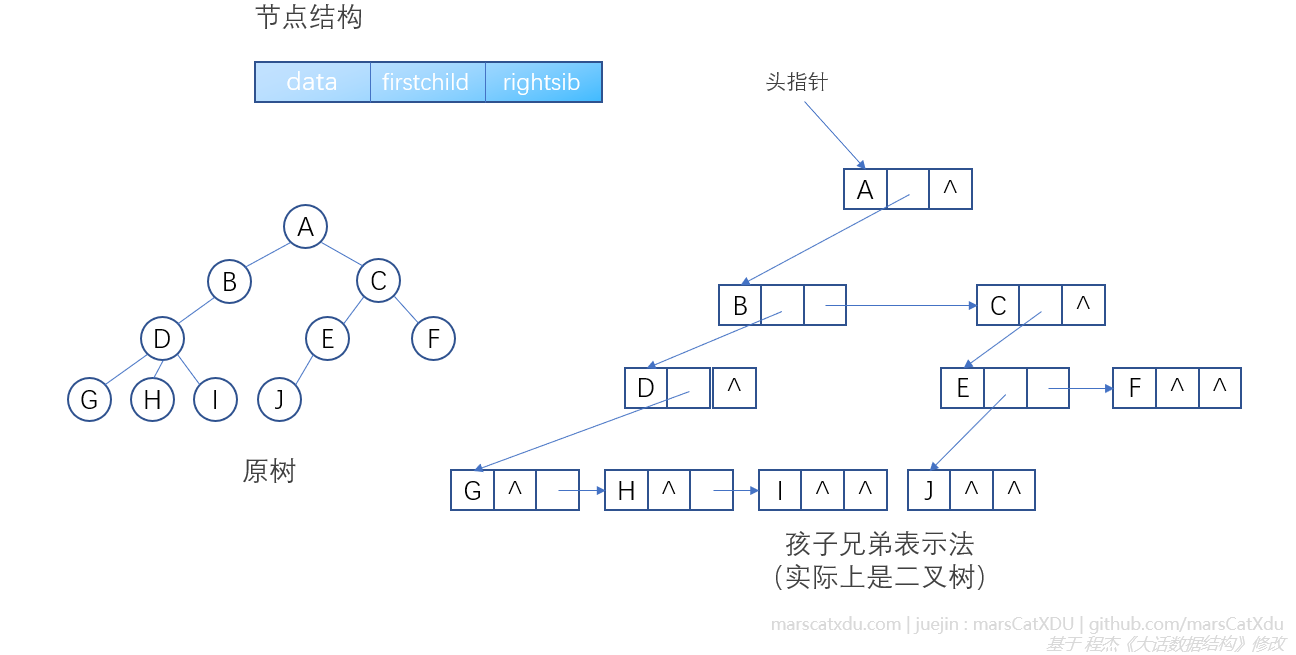
一般树可以转化为二叉树
将一般树用【孩子兄弟表示法】进行表示,即可转化为二叉树
特殊的二叉树
- 满二叉树:所有分支节点都有左右两个子树,所有叶子都在同一层上;
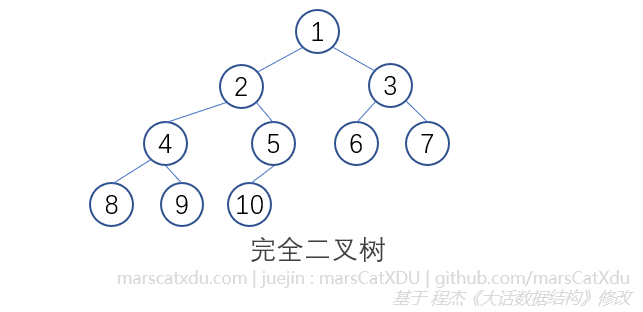
- 完全二叉树:从根开始,节点从上到下、从左到右排满,节点标号同样是从上到下、从左到右排列,中间不能随意为空、跳过节点。节点数相同的二叉树,完全二叉树深度最小。
二叉树性质
- 二叉树第 i 层至多有 2i-1 个节点(记法:根节点有 21-1 = 1 个节点);
- 深度为 k 的二叉树至多有 2k-1 个节点(等比数列前 n 项和 [a1(1-qn)]/(1-q) );
- 对终端节点数为 n0、度为 2 的节点数为 n2 的任意二叉树,有 n0 = n2 + 1 除了根节点之外,每个节点都配有一条线,故总线数是 n-1,n-1 = 2n2 + n1 (有几个子节点就有几个线,可以通过求线数,再 +1 求得最终的节点数);
- n 节点完全二叉树深度为 ⌊log2n⌋ + 1(因为,log2n = k,k-1=深度。参考上面的第二条);
- n 节点 ⌊log2n⌋ + 1 深度的完全二叉树,按层序编号的任意节点 i,有:
- 节点 i 的父节点为 ⌊i/2⌋(当然,除了根);
- 2i 是 i 的左孩子,若 2i>n 则无左孩子;
- 2i+1 是 i 的右孩子,同样若 2i+1>n 则无右孩子
二叉树存储
顺序存储
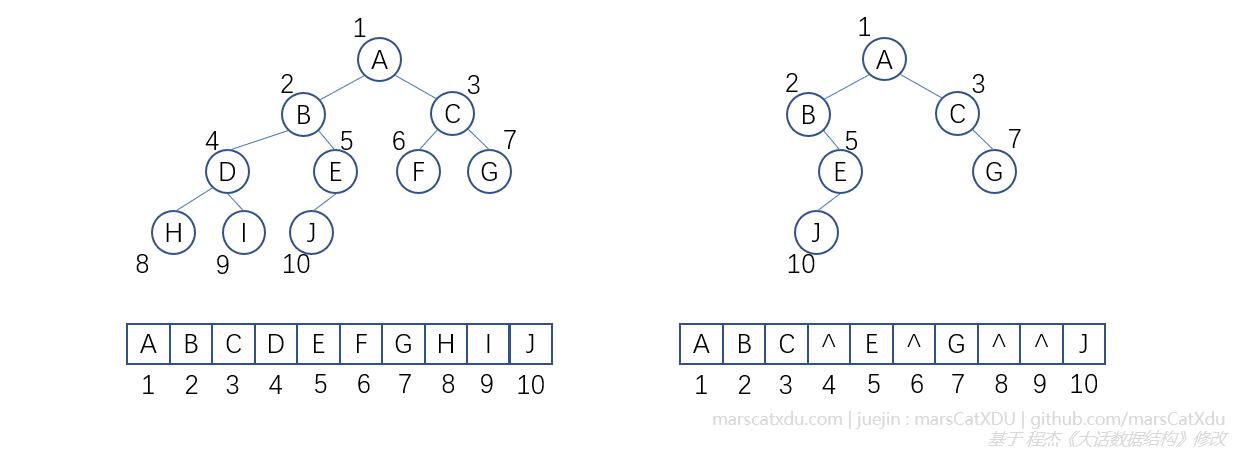
得益于二叉树的严格定义,顺序存储也能体现其结构。满二叉树如下图左,一般二叉树如下图右。该方法适用于很小的二叉树
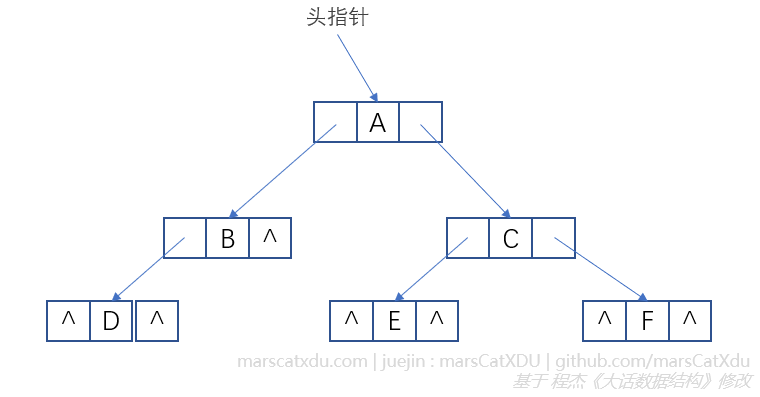
二叉链表
如图
二叉树遍历
二叉树下面的三种遍历都是递归过程。所谓的 “前、中、后” 都是说明访问子树根节点的时机。
这里的重点,是用递归的方式思考。
前序遍历
树为空,返回;否则先根,然后前序遍历左子树,再前序遍历右子树
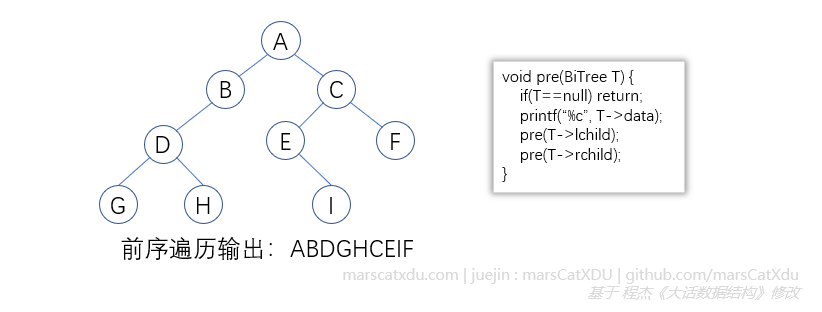
这是一个递归的过程,想要彻底理解,需要在脑内放一个调用栈的动画。
下面这张图是我尝试把我脑子里面的调用栈图形化的结果,怕不是只有我一个人能看懂。。无论如何,祝愿你也能看懂。
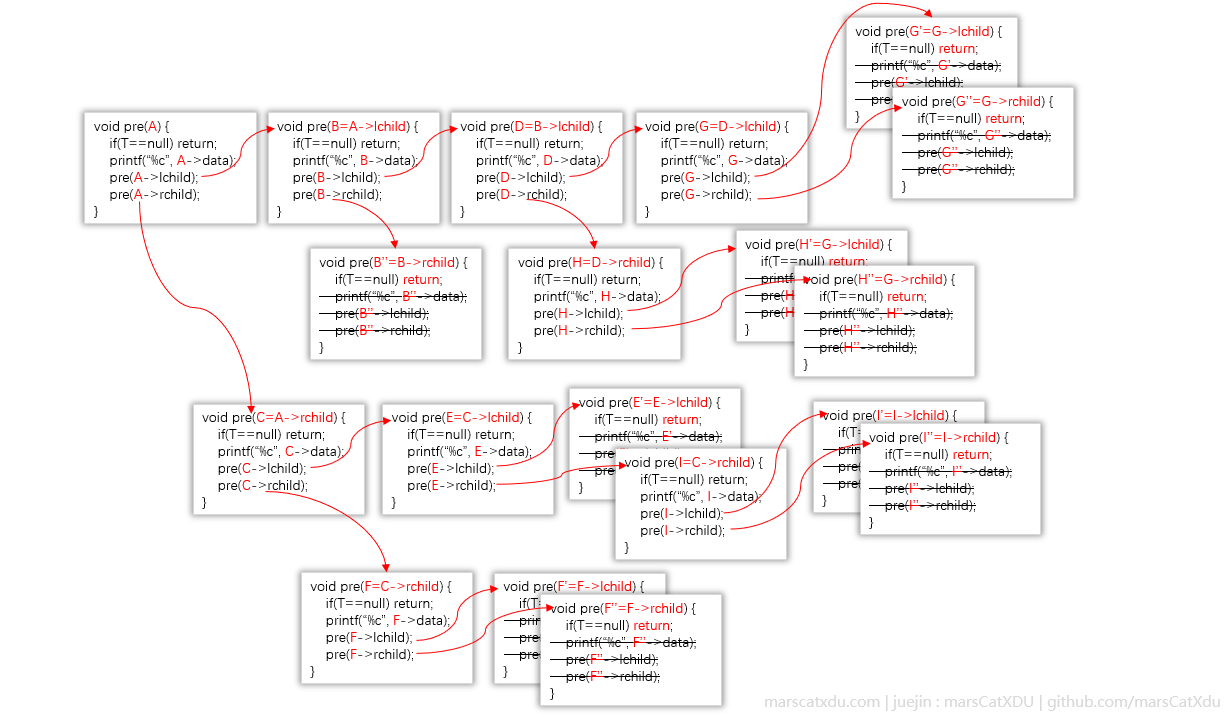
画图画的好累。。。不想解释了,总之代码肯定是从上往下一行一行执行,调用顺着箭头走
中序遍历
树为空,返回;否则从根节点开始先中序遍历左子树,再访问根节点,再中序遍历右子树
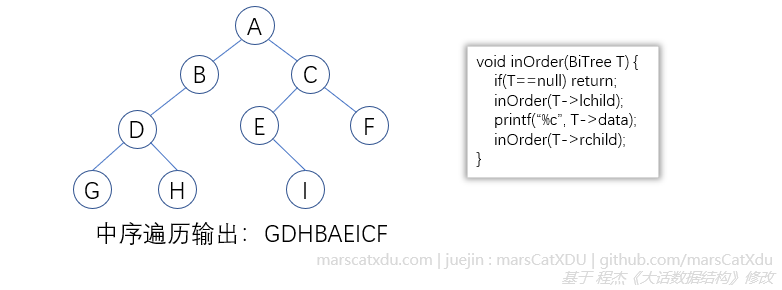
中序遍历的输出有个特点:某个字母,只有在该字母所在节点的左子树全输出完后才会被输出。
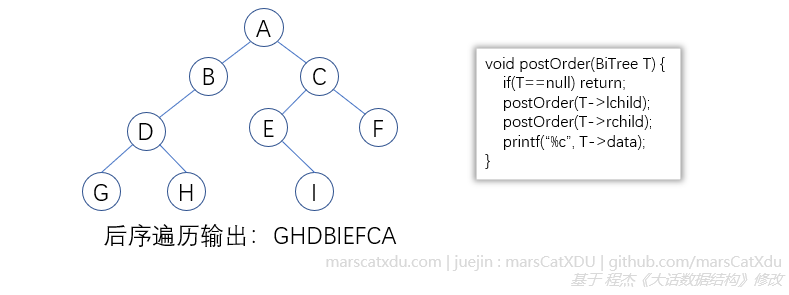
后序遍历
树为空,返回;否则先从左到右先叶子后节点地遍历左右子树,最后访问根节点
层序遍历
从上往下,读完一层再读下一层。用和上面相同的树为例,输出结果是:ABCDEFGHI
附1:可用于检查理解程度并练习的例子
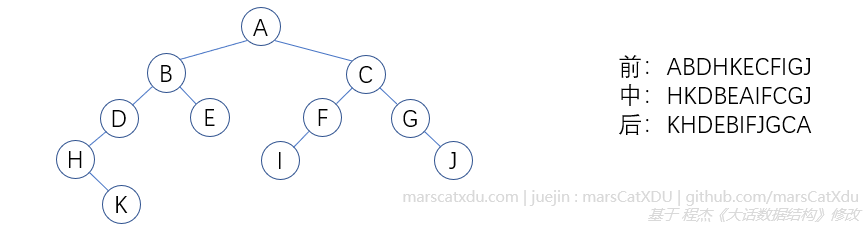
附2:某类题
已知某二叉树前序遍历输出:ABCDEF,中序遍历输出:CBAEDF,求树的后序遍历输出。
答案:CBEFDA。
关键点:
- A 肯定是根;
- 在中序遍历中,某个字母,只有在该字母所在节点的左子树全输出完后才会被输出。那么 CB 、 EDF 肯定分别是 A 的左右子树。
二叉树遍历性质
- 已知前、中,可唯一确定二叉树;
- 已知中、后,也可;
- 已知前、后,布星。
使用扩展树建立二叉树
想要建立一个一般的二叉树,可以将二叉树扩展为【扩展二叉树】,再通过输入的遍历序列来建立之。
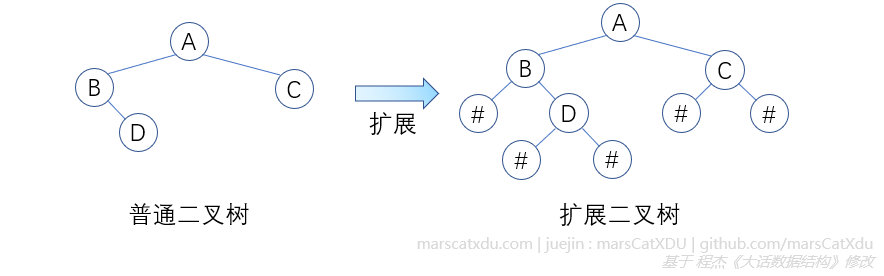
不难看出,上图中扩展二叉树的前序遍历序列为:AB#D##C##
运行如下算法,我们便可以通过用键盘敲上面的前序遍历序列来建立扩展二叉树了。如果彻底理解了前面的遍历,那这个应该非常好懂
// 代码出自 程杰《大话数据结构》,有极细微修改
void CreateBiTree(BiTree *T) {
TElemType ch;
scanf("%c", &ch);
if(ch=='#') {
*T = NULL;
} else {
*T = (BiTree)malloc(sizeof(BiTNode));
if(!*T) {
exit(OVERFLOW);
}
(*T)->data = ch; // 生成根节点
CreateBiTree(&(*T)->lchild); // 构造左子树
CreateBiTree(&(*T)->rchild); // 构造右子树
}
}
线索二叉树
二叉链表中必存在空指针域,我们可以用这些原本无用的空指针来存放指向节点再某种遍历次序下的前驱和后继节点地址。这种指向前驱、后继的指针叫【线索】,增加了线索的二叉链表叫【线索链表】,二叉树即【线索二叉树】(Threaded Binary Tree)
二叉树中序遍历线索化
将所有空 rchild 指向遍历中的后继节点,空 lchild 指向遍历中的前驱节点。
BiThrTree pre;
void InThreading(BiThrTree p) {
if(p) {
InThreading(p->lchild);
if(!p->lchild) {
p->LTag = 1;
p->lchild = pre;
}
if(!pre->rchild) {
pre->RTag = 1;
pre->rchild = p;
}
pre = p;
InThreading(p->rchild);
}
}
二叉树、树、森林
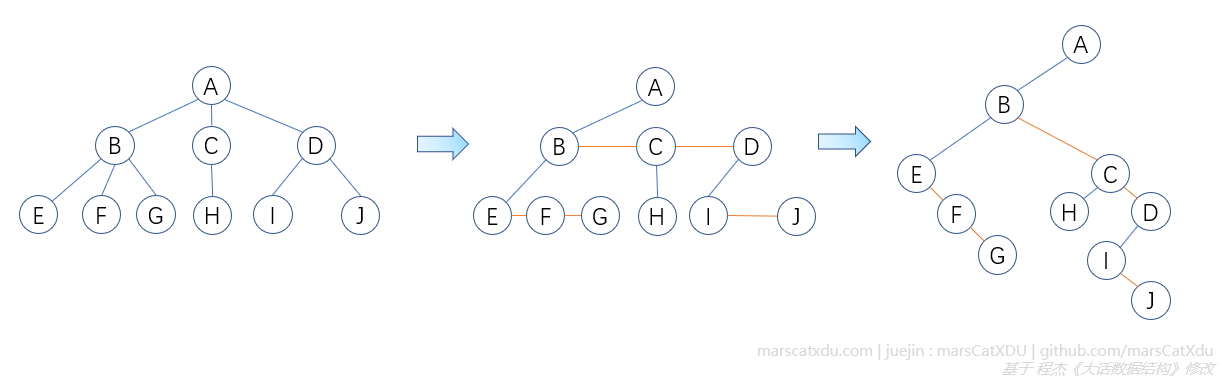
树转化为二叉树
参考本文最前面的内容,下面给出图例。注意原有的线是左子节点,新添加横线的线(下图中橙色线)都是右子节点即可。
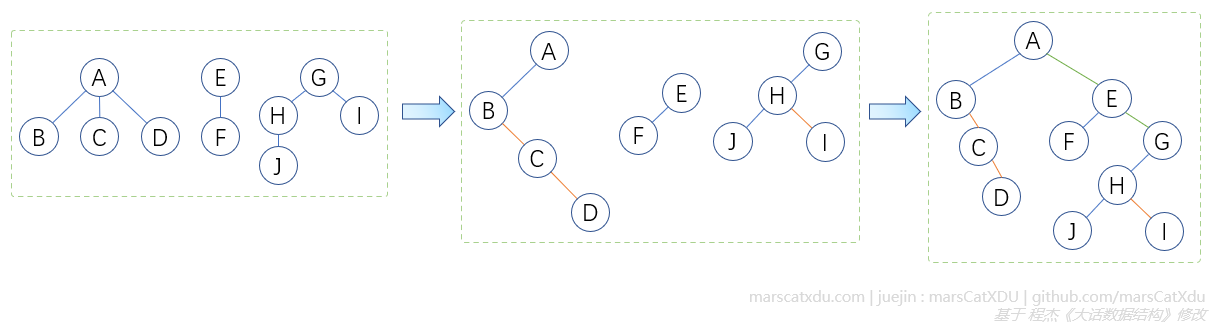
森林转为二叉树
先将树转为二叉树,再把每个相对右侧树作为相对左侧树根节点之下的右子树
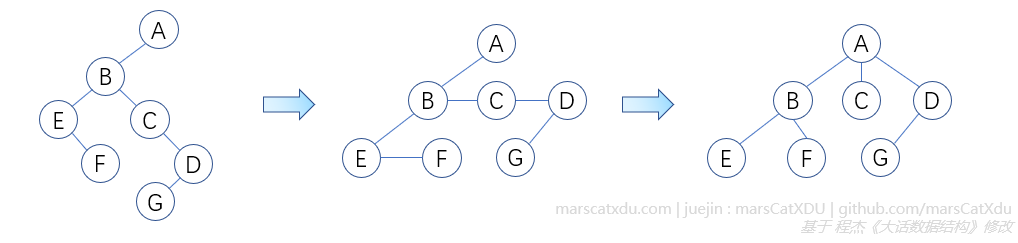
二叉树转为树
先把所有右子树都往上搬,让曾经向着右下方倾斜的线变成横线。然后再把横线都改为直接连向上一级父节点
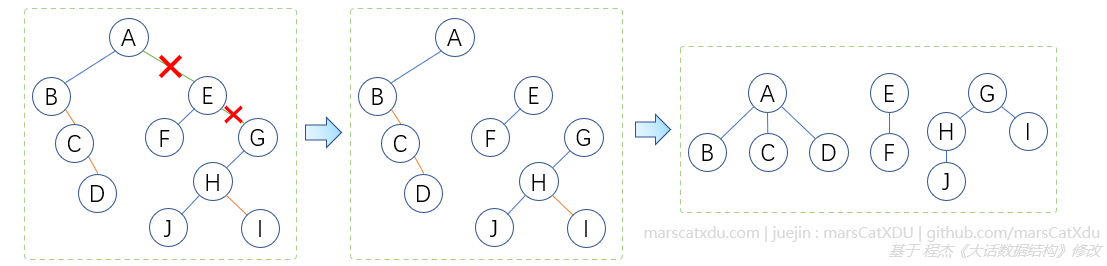
二叉树转森林
先拆再改。首先从根节点开始,向着右下方拆掉右子树。然后再将二叉树转为树
树遍历
先根、后根遍历。因子节点数量不定,故只分了最先访问根还是最后访问根两种情况。

森林和与其对应的二叉树的前序结果相同,森林的后序和二叉树的中序遍历结果相同。
用二叉链表存树时,树的先根、后根遍历可以用二叉树的前序、中序遍历实现。
哈夫曼树
补充概念
-
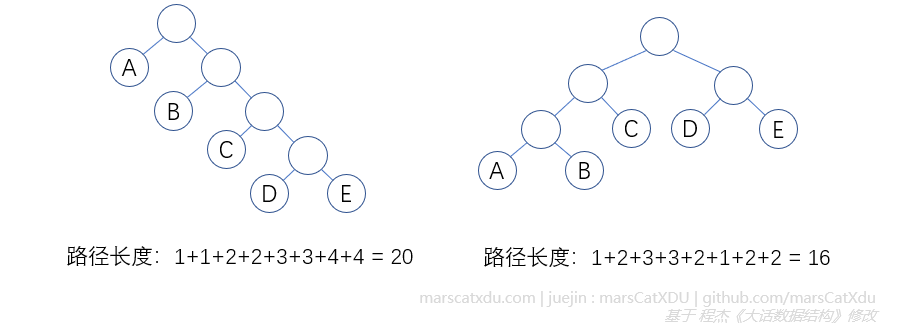
路径长度:从树中一个节点到另一个节点之间的分支构成两个节点之间的路径,路径上的分支数目叫路径长度;
-
树的路径长度:从树根到每一节点的路径长度和
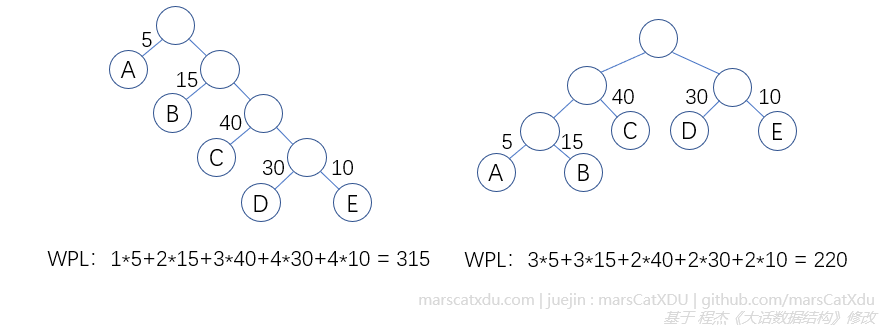
- 带权路径长度(WPL):从该节点到树根之间的路径长度 × 节点的权 注意是到达的节点本身的权,而不是一路上的权值之和之类的。。
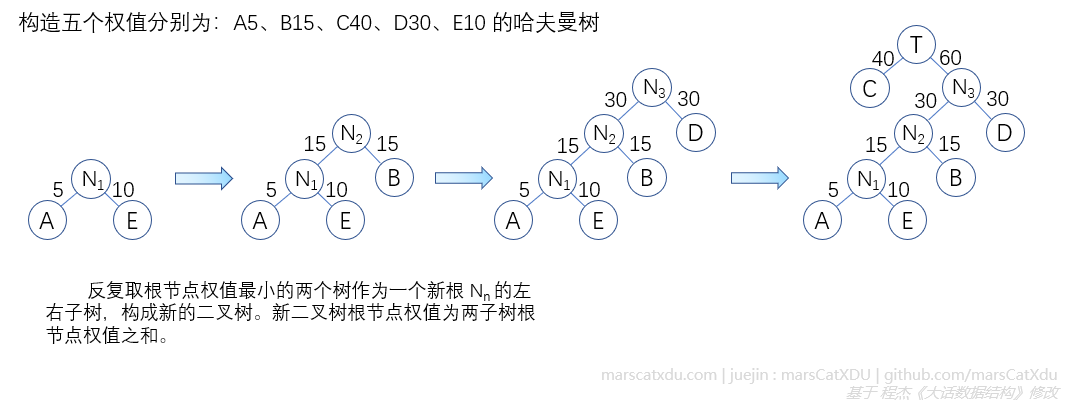
构造算法描述
- 根据给定的 n 个权值 {w1, w2, ... , wn },构成 n 棵二叉树的集合 F = { T1, T2, ... , Tn} ,这些 T 此时都还是只有一个权值为 w1 的根节点的树;
- 在 F 中选两个根节点权值最小的二叉树作为左右子树构造一个新的二叉树,该新树根节点权值为左右子树根节点权值之和;
- 用新的树在集合 F 中替换掉构成它的两棵子树;
- 重复 2、3 至 F 仅含一棵树。剩下的就是哈夫曼树。
实例
哈夫曼编码
如果需要编码的字符集为 { d1, d2, ..., dn } ,各个字符出现的频率为 { w1, w2, ..., wn } 。则以 d1, d2, ..., dn 为权值分别为 w1, w2, ..., wn 的叶子节点,构造一棵哈夫曼树,并规定该树左分支代表 0 、右分支代表 1,则从根节点到叶子节点经过的路径分支组成的 01 串即为该节点字符对应的编码。这样的编码即哈夫曼编码。
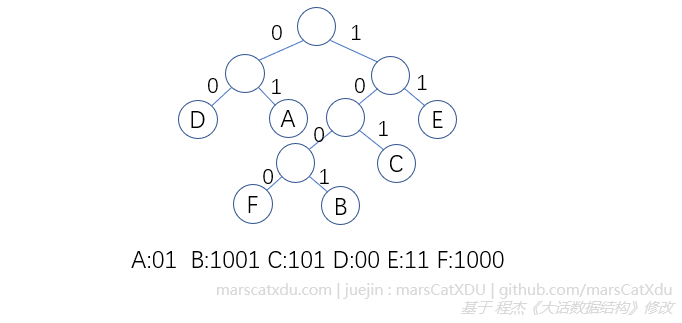
该编码方式的各个字符编码长度不等,为避免混淆,任意字符的编码都不是另一字符编码的前缀。该类编码被称为【前缀编码】。为了能够正常解码,收发双方必须提前约定好同样的编码规则。
