

对象创建过程
1. 类加载检查
虚拟机遇到一条new指令时,首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
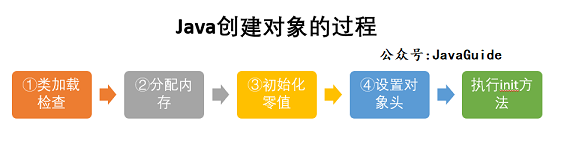
2. 分配内存
在类加载检查通过后,接下来虚拟机将为新生对象分配内存。对象所需的内存大小在类加载完成后便可确定,为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来。
2.1 分配方式
分配方式有 “指针碰撞” 和 “空闲列表” 两种,选择那种分配方式由 Java 堆是否规整决定,而 Java 堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定。
-
指针碰撞:堆内存规整的情况下;用过的内存整合到一边,没用过的整合到另一边,中间是一个分界指针,分配时只需要让指针向没使用过的内存方向移动对象内存大小即可。
-
空闲列表:堆内存不规整的情况下;虚拟机会维护一个列表,记录哪些空间是空闲的,分配时找一块足够大的内存给对象,列表做记录。
分配方式的选择 取决于 Java堆内存是否规整; 而 Java堆是否规整由所采用的垃圾收集器是否带有压缩整理功能决定。因此:
-
使用基于 标记整理 算法的垃圾收集器时,采用指针碰撞;如
Serial、ParNew垃圾收集器 -
使用基于标记清除 算法的垃圾收集器时,采用空闲列表。如
CMS垃圾收集器
2.2 内存分配并发问题(分配内存时,可能存在冲突)
在创建对象的时候有一个很重要的问题,就是线程安全,因为在实际开发过程中,创建对象是很频繁的事情,作为虚拟机来说,必须要保证线程是安全的,通常来讲,虚拟机采用两种方式来保证线程安全:
-
CAS+失败重试: CAS 是乐观锁的一种实现方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。虚拟机采用 CAS 配上失败重试的方式保证更新操作的原子性。
-
TLAB(Thread Local Allocation Buffer,线程私有的分配缓冲区): 为每一个线程预先在 Eden 区分配一块儿内存,当然申请这个空间的过程是线程同步的。JVM 在给线程中的对象分配内存时,首先在 TLAB 分配,当对象大于 TLAB 中的剩余内存或 TLAB 的内存已用尽时,它会再向Eden空间去申请一个TLAB(同步);如果新的TLAB还是放不下,再采用上述的 CAS 进行内存分配
3. 初始化零值
内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),这一步操作保证了对象的实例字段在 Java 代码中可以不赋初始值就直接使用,程序能访问到这些字段的数据类型所对应的零值。
从虚拟机的视角来看,一个新的对象已经产生了,从 Java 程序角度来看,对象创建才刚刚开始
4. 设置对象头
初始化零值完成之后,虚拟机要对对象进行必要的设置,例如这个对象是那个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息。 这些信息存放在对象头中。 另外,根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
5. 执行init(类实例初始化方法) 方法
在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始,<init> 方法还没有执行,所有的字段都还为零。所以一般来说,执行new指令之后会接着执行 <init> 方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来。
5.1 init与clinit
构造器是由javac命令生成,而构造函数则实质为我们写的 java 代码 构造方法(也叫构造函数)
<init>构造器的生成和构造函数相互对应,如果我们的java代码没有显示的构造函数,那编译器将会添加一个没有参数的、访问性(public、protected或private)与当前类一致的默认构造函数.并根据默认构造函数生成<init>.
实例代码块{}优先级高于构造函数中的赋值动作.多个{}按先后顺序最终合并到<init>中.
变量初始化 & 语句块的顺序等于定义的顺序
<init>包含了以下部分
- 非静态变量初始化
- 语句块
- 构造函数
- 父类的
<init>
<clinit>包含了以下部分
- 静态变量初始化
- 静态语句块
5.2 父类、子类的初始化顺序
一个有父类的子类,new一个对象,加载顺序为:
当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
- 父类的
<clinit>方法 - 子类的
<clinit>方法
当初始化类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化
- 父类的
<init>方法 - 子类的
<init>方法
5.3 子类调用父类构造器
我们可以通过super实现对超类构造器的调用。
使用super调用构造器的语句必须是子类构造器的第一条语句。
如果子类的构造器没有显式地调用超类的构造器,则将自动地调用超类默认(没有参数)的构造器。
如果超类没有不带参数的构造器,并且在子类的构造器中又没有显式地调用超类的其他构造器,则Java编译器将报告错误。
对象在内存中的布局
在 Hotspot 虚拟机中,对象在内存中的布局可以分为 3 块区域:对象头、实例数据和对齐填充。
1. 对象头
Hotspot 虚拟机的对象头包括两部分信息
-
用于存储对象自身的运行时数据(哈希码、GC 分代年龄、锁状态标志等等),
-
类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是那个类的实例;
此外,如果对象是一个Java数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是如果数组的长度是不确定的,将无法通过元数据中的信息推断出数组的大小。
普通对象
|--------------------------------------------------------------|
| Object Header (64 bits) |
|------------------------------------|-------------------------|
| Mark Word (32 bits) | Klass Word (32 bits) |
|------------------------------------|-------------------------|
数组对象
|---------------------------------------------------------------------------------|
| Object Header (96 bits) |
|--------------------------------|-----------------------|------------------------|
| Mark Word(32bits) | Klass Word(32bits) | array length(32bits) |
|--------------------------------|-----------------------|------------------------|
对象头详解:www.jianshu.com/p/3d38cba67…
2. 实例数据
实例数据部分是对象真正存储的有效信息,也是在程序中所定义的各种类型的字段内容。
3. 对齐填充
对齐填充部分不是必然存在的,也没有什么特别的含义,仅仅起占位作用。
因为 Hotspot 虚拟机的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,换句话说就是对象的大小必须是 8 字节的整数倍。
对象头部分正好是 8 字节的倍数(1 倍或 2 倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
对象的访问定位
建立对象就是为了使用对象,我们的 Java 程序通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式由虚拟机实现而定,目前主流的访问方式有句柄和直接指针两种。
reference要符合以下两点要求:
- 从此引用直接或间接地查找到对象在 Java 堆中的数据存放的起始地址索引(找到对象数据)
- 从此引用直接或间接地查找到对象所属数据类型在方法区中存储地类型信息(找到类型信息)
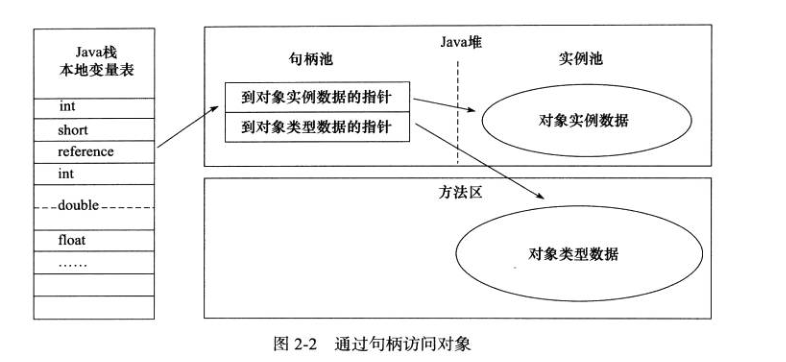
1. 句柄
如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息;
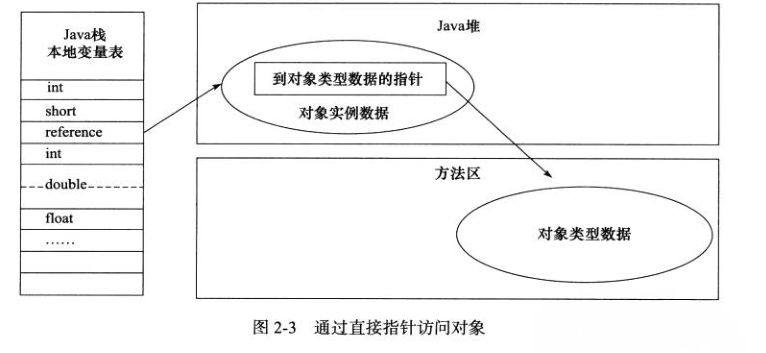
2. 直接指针
如果使用直接指针访问,那么 Java 堆对象的布局中就必须考虑如何放置访问类型数据的相关信息,而 reference 中存储的直接就是对象的地址。
3. 两种方式对比
这两种对象访问方式各有优势。
使用句柄来访问的最大好处是 reference 中存储的是稳定的句柄地址,在对象被移动时只会改变句柄中的实例数据指针(垃圾收集时,移动对象非常普遍),而 reference 本身不需要修改。
使用直接指针访问方式最大的好处就是速度快,它节省了一次指针定位的时间开销。 由于对对象的访问在Java总非常频繁,因此这类开销极少成多之后,也是很大的成本。(商业虚拟机都使用此方式)
