

1.call,apply,bind他们有什么区别
var foo = {
value: 1
}
function bar () {
console.log(this.value)
}
// 如果不对this进行绑定执行bar() 会返回undefined
bar.call(foo) // 1共同点:
都可以改变函数执行的上下文环境;bind返回对应函数, 便于稍后调用; apply, call则是立即调用。
不同点:
fun.call(xh,"a","b");
fun.apply(xh,["a","b"]);
fun.bind(xh,"a","b")();
原理:
- 将函数设为对象的属性
- 执行这个函数
- 删除这个函数
2.常见的继承有哪些?组合式继承中,子函数继承父函数的prototype怎么继承?
function Parent2(){
this.name = "parent2";
this.colors = ["red","blue","yellow"];
}
function Child2(){
Parent2.call(this);
this.type = "child2";
}
Child2.prototype = new Parent2()复制代码var s1 = new Child2();
s1.colors.push("black");
var s2 = new Child2();
s1.colors; // (4) ["red", "blue", "yellow", "balck"]
s2.colors; // (3) ["red", "blue", "yellow"]我了解的面试官可能想要考啥深度克隆和浅克隆,但是不知道对不对。我回答object.assign
Object.assign
JSON.parse(JSON.stringify(obj)): 性能最快
- 具有循环引用的对象时,报错
- 当值为函数、
undefined、或symbol时,无法拷贝 - $.extend
4.描述一下作用域,作用域链是怎么生成的?
简单来讲,作用域(scope)就是变量访问规则的有效范围。
- 全局作用域
var foo = 'foo'; console.log(window.foo); // => 'foo' 函数作用域function doSomething () { var thing = '吃早餐'; } console.log(thing); // Uncaught ReferenceError: thing is not defined
- ES6的块级作用域
很多书上都有一句话,javascript没有块级作用域的概念。所谓块级作用域,就是{}包裹的区域。但是在ES6出来以后,这句话并不那么正确了。因为可以用 let 或者 const 声明一个块级作用域的变量或常量。
比如:
for (let i = 0; i < 10; i++) {
// ...
}
console.log(i); // Uncaught ReferenceError: i is not defined默认使用 const,只有当确实需要改变变量的值的时候才使用let。因为大部分的变量的值在初始化之后不应再改变,而预料之外的变量的修改是很多bug的源头。
var a = 123;
function fn1 () {
console.log(a);
}
function fn2 () {
var a = 456;
fn1();
}
fn2(); // 123通俗地讲,当声明一个函数时,局部作用域一级一级向上包起来,就是作用域链。
- 当执行函数时,总是先从函数内部找寻局部变量
- 如果内部找不到(函数的局部作用域没有),则会向创建函数的作用域(声明函数的作用域)寻找,依次向上
- 由两部分组成:
[[scope]]属性: 指向父级变量对象和作用域链,也就是包含了父级的[[scope]]和AO- AO: 自身活动对象
如此 [[scopr]]包含[[scope]],便自上而下形成一条 链式作用域。
5.闭包
6.[]==0?
两个不同类型的简单类型数据通过 == 进行比较时,都会转换为数值类型再进行比较。
[]会转化成0, 0==0返回true
7.用splice如何删除数组
8.reduce方法内部是怎么实现的
reduce(callback,initiaValue)会传入两个变量,回调函数(callback)和初始值(initiaValue)。
假设函数有个传入参数,prev和next,index和array。 Prev和next是你必须要了解的。
当没有传入初始值时,prev是从数组中第一个元素开始的,next是第二个函数。
但是当传入初始值(initiaValue)后,第一个prev将是initivalValue,next将是数组中的第一个元素。
// 实现的原理
Array.prototype.myReduce = function(fn, initialValue) {
if (this.length === 0) {
if (initialValue === undefined) {
console.error("reduce of empty array with no initialValue")
} else {
return initialValue
}
} else {
var prev = initialValue !== undefined ? initialValue : this[0]
var startIndex = initialValue !== undefined ? 0 : 1
for (var i = startIndex; i < this.length; i++) {
prev = fn(prev, this[i])
}
return prev
}
}
var ret = arr.myReduce(function(prev, curr) {
return prev + curr
}, 5) 3q
console.log(ret)
//reduce
Array.prototype.reduce = function (callback, pre) { for (let i = 0; i < this.length; i++) { if (typeof pre == undefined) { pre = callback(this[i + 1], this[i], i, this); i++; } else { pre = callback(pre, this[i], i, this) } } return pre}let rd = [1, 2, 3].reduce((a, b, index, arr) => { return a + b}, 0)
10.map
ES6 提供了 Map 数据结构。它类似于对象,也是键值对的集合,但是“键”的范围不限于字符串,各种类型的值(包括对象)都可以当作键。也就是说,Object 结构提供了“字符串—值”的对应,Map 结构提供了“值—值”的对应,是一种更完善的 Hash 结构实现。如果你需要“键值对”的数据结构,Map 比 Object 更合适。
const m = new Map();
const o = {p: 'Hello World'};
m.set(o, 'content')
m.get(o) // "content"
m.has(o) // true
m.delete(o) // true
m.has(o) // false11.盒子水平居中,transform和margin的区别
transform 属于合成属性(composite property),对合成属性进行 transition/animation 动画将会创建一个合成层(composite layer),这使得被动画元素在一个独立的层中进行动画。通常情况下,浏览器会将一个层的内容先绘制进一个位图中,然后再作为纹理(texture)上传到 GPU,只要该层的内容不发生改变,就没必要进行重绘(repaint),浏览器会通过重新复合(recomposite)来形成一个新的帧。
top/left属于布局属性,该属性的变化会导致重排(reflow/relayout),所谓重排即指对这些节点以及受这些节点影响的其它节点,进行CSS计算->布局->重绘过程,浏览器需要为整个层进行重绘并重新上传到 GPU,造成了极大的性能开销。
对布局属性进行动画,浏览器需要为每一帧进行重绘并上传到 GPU 中
对合成属性进行动画,浏览器会为元素创建一个独立的复合层,当元素内容没有发生改变,该层就不会被重绘,浏览器会通过重新复合来创建动画帧
11.事件模型,怎么阻止冒泡,preventdefult会不会退去所有元素的冒泡?
w3c的方法是e.stopPropagation(),IE则是使用e.cancelBubble = true
原文链接:caibaojian.com/javascript-…
取消默认事件
w3c的方法是e.preventDefault(),IE则是使用e.returnValue = false;·
preventDefault它是事件对象(Event)的一个方法,作用是取消一个目标元素的默认行为。既然是说默认行为,当然是元素必须有默认行为才能被取消,如果元素本身就没有默认行为,调用当然就无效了。什么元素有默认行为呢?如链接<a>,提交按钮<input type=”submit”>等。当Event 对象的 cancelable为false时,表示没有默认行为,这时即使有默认行为,调用preventDefault也是不会起作用的。
var a = document.getElementById("testA");
a.onclick =function(e){
if(e.preventDefault){
e.preventDefault();
}else{
window.event.returnValue == false;
}
}function cancelHandler(event) {var e = window.event || event;if(document.all) {e.returnValue = false;}else {e.preventDefault();}}12.绑定事件有什么
13.http协议,url到服务器返回数据都经历了什么,http1的keep alive和http2有什么区别
KeepAlive带来的好处是可以减少tcp连接的开销.websocket不同,它本身就规定了是正真的、双工的长连接,两边都必须要维持住连接的状态。
HTTP/2中,在HTTP / 2.0中引入了多路复用,能够让多个请求使用同一个TCP链接,极大的加快了网页的加载速度。并且还支持Header压缩,进一步的减少了请求的数据大小,可以一次性发很多请求。
14.promise原理,用法,promise all原理
- 可以把
Promise看成一个状态机。初始是pending状态,可以通过函数resolve和reject,将状态转变为resolved或者rejected状态,状态一旦改变就不能再次变化。then函数会返回一个Promise实例,并且该返回值是一个新的实例而不是之前的实例。因为Promise规范规定除了pending状态,其他状态是不可以改变的,如果返回的是一个相同实例的话,多个then调用就失去意义了。- 对于
then来说,本质上可以把它看成是flatMap
http://blog.poetries.top/FE-Interview-Questions/advance/#_16-promise-%E5%AE%9E%E7%8E%B0Promise.all的返回值是一个Promise实例
Promise.all = function (promise) {
return new Promise((resolve, reject) => {
let index = 0
let result = []
if (promise.length === 0) {
resolve(result)
} else {
function processValue(i, data) {
result[i] = data
if (++index === promise.length) {
resolve(result)
}
}
for (let i = 0; i < promise.length; i++) {
Promise.resolve(promise[i]).then((data) => {
processValue(i, data)
}, (err) => {
reject(err)
return
})
}
}
})
}
在实际应用中,如果可以从几个接口获取相同的数据,哪个接口数据先到就先用哪个,就可以使用Promise.race(),所需时间等于其中最快的那个接口。下面是代码:
const race = function (iterable) {
return new Promise(function (resolve, reject) {
for (const i in iterable) {
const v = iterable[i]
if (typeof v === 'object' && typeof v.then === 'function') {
v.then(resolve, reject)
} else { resolve(v)
} } })}const p1 = new Promise(function (resolve) {
setTimeout(resolve, 200, 1) })
const p2 = new Promise(function (resolve) { s
etTimeout(resolve, 100, 2) })
race([p1, p2]).then(function (res) { console.log(res) }) // 2promise
.then(result => {···})
.catch(error => {···})
.finally(() => {···});上面代码中,不管promise最后的状态,在执行完then或catch指定的回调函数以后,都会执行finally方法指定的回调函数。
下面是一个例子,服务器使用 Promise 处理请求,然后使用finally方法关掉服务器。
promise
.then(result => {···})
.catch(error => {···})
.finally(() => {···});
finally方法的回调函数不接受任何参数,这意味着没有办法知道,
前面的 Promise 状态到底是fulfilled还是rejected。这表明,
finally方法里面的操作,应该是与状态无关的,不依赖于 Promise 的执行结果。
15.微任务和宏任务的执行机制,微任务和宏任务是如何切换的,什么时候执行微任务什么时候执行宏任务,执行的时机是什么?
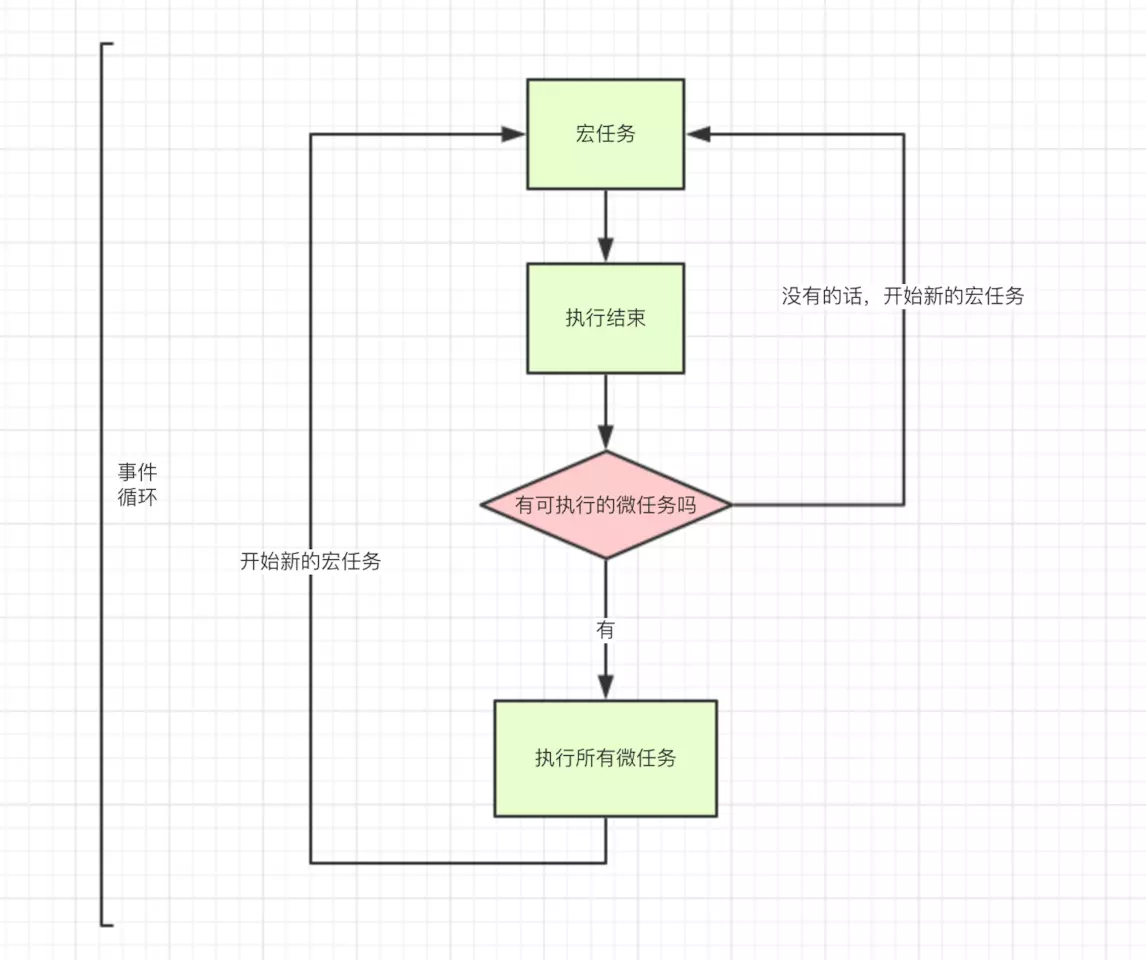
执行完宏任务必须执行微任务,而不是一次性把所有微任务执行完。
宏任务中包括了 script ,浏览器会先执行一个宏任务,接下来有异步代码的话就先执行微任务.
所以正确的一次 Event loop 顺序是这样的
- 执行同步代码,这属于宏任务
- 执行栈为空,查询是否有微任务需要执行
- 执行所有微任务
- 必要的话渲染 UI
- 然后开始下一轮
Event loop,执行宏任务中的异步代码
process.nextTickpromiseObject.observeMutationObserver
scriptsetTimeoutsetIntervalsetImmediateI/OUI rendering
Promise.resolve().then(()=>{
console.log('Promise1')
setTimeout(()=>{
console.log('setTimeout2')
},0)
})
setTimeout(()=>{
console.log('setTimeout1')
Promise.resolve().then(()=>{
console.log('Promise2')
})
},0)
执行结果为:Promise1,setTimeout1,Promise2,setTimeout2
16.generator函数使用过程
传统的编程语言,早有异步编程的解决方案(其实是多任务的解决方案)。其中有一种叫做"协程"(coroutine),意思是多个线程互相协作,完成异步任务。
协程有点像函数,又有点像线程。它的运行流程大致如下。
- 第一步,协程
A开始执行。 - 第二步,协程
A执行到一半,进入暂停,执行权转移到协程B。 - 第三步,(一段时间后)协程
B交还执行权。 - 第四步,协程
A恢复执行。
上面流程的协程A,就是异步任务,因为它分成两段(或多段)执行。
举例来说,读取文件的协程写法如下。
function* asyncJob() {
// ...其他代码
var f = yield readFile(fileA);
// ...其他代码
}创建了这个函数的句柄,并没有实际执行,需要进一步调用next()
加上 * 的函数执行后拥有了 next函数,也就是说函数执行后返回了一个对象。每次调用 next函数可以继续执行被暂停的代码。以下是 Generator函数的简单实现
function* helloGenerator() {
yield "hello";
yield "generator";
return;
}
var h = helloGenerator();
console.log(h.next());//{ value: 'hello', done: false }
console.log(h.next());//{ value: 'generator', done: false }
console.log(h.next());//{ value: 'undefined', done: true }
(1)创建了h对象,指向helloGenerator的句柄, (2)第一次调用nex(),执行到"yield hello",暂缓执行,并返回了"hello" (3)第二次调用next(),继续上一次的执行,执行到"yield generator",暂缓执行,并返回了"generator"。 (4)第三次调用next(),直接执行return,并返回done:true,表明结束。 经过上面的分析,yield实际就是暂缓执行的标示,每执行一次next(),相当于指针移动到下一个yield位置。 总结一下,Generator函数是ES6提供的一种异步编程解决方案。通过yield标识位和next()方法调用,实现函数的分段执行。
原文链接:blog.poetries.top/FE-Intervie…
await的特点
1. 简洁
由示例可知,使用Async/Await明显节约了不少代码。我们不需要写.then,不需要写匿名函数处理Promise的resolve值,也不需要定义多余的data变量,还避免了嵌套代码。这些小的优点会迅速累计起来,这在之后的代码示例中会更加明显。
function timeout(ms) {
return new Promise((resolve) => {
setTimeout(resolve, ms);
});
}
async function asyncPrint(value, ms) {
await timeout(ms);
console.log(value);
}
asyncPrint('hello world', 50);2. 错误处理
Async/Await让try/catch可以同时处理同步和异步错误。在下面的promise示例中我们需要使用.catch,这样错误处理代码非常冗余。并且,在我们的实际生产代码会更加复杂。·promise处理异常需要在catch中捕捉错误异常,而await只在asnic中处理就行
const makeRequest = async () => { await callAPromise() await callAPromise() await callAPromise() await callAPromise() await callAPromise() throw new Error("oops"); } makeRequest() .catch(err => { console.log(err); // output // Error: oops at makeRequest (index.js:7:9) })
18.数据劫持
Object.defineProperty(obj,prop,descriptor)
obj:目标对象
prop:需要定义的属性或方法的名称
descriptor:目标属性所拥有的特性
可供定义的特性列表value:属性的值writable:如果为false,属性的值就不能被重写。
get: 一旦目标属性被访问就会调回此方法,并将此方法的运算结果返回用户。
set:一旦目标属性被赋值,就会调回此方法。
configurable:如果为false,
则任何尝试删除目标属性或修改属性性以下特性(writable, configurable, enumerable)的行为将被无效化。
enumerable:是否能在for...in循环中遍历出来或在Object.keys中列举出来。Object.defineProperty主要是通过set和get来让属性值发生变化
var data = {
name:'lhl'
}
Object.keys(data).forEach(function(key){
Object.defineProperty(data,key,{
get:function(){
console.log('get');
},
set:function(){
console.log('监听到数据发生了变化');
}
})
});
data.name //控制台会打印出 “get”
data.name = 'hxx' //控制台会打印出 "监听到数据发生了变化"
使用 Object.defineProperty() 多数要配合 Object.keys() 和遍历,于是多了一层嵌套
Object.keys(obj).forEach(key => {
Object.defineProperty(obj, key, {
// ...
})
}
如果是这一类嵌套对象,那就必须逐层遍历,直到把每个对象的每个属性都调用 Object.defineProperty() 为止。 Vue 的源码中就能找到这样的逻辑 (叫做 walk 方法)。
在数据劫持这个问题上,Proxy 可以被认为是 Object.defineProperty() 的升级版。外界对某个对象的访问,都必须经过这层拦截。因此它是针对 整个对象,而不是 对象的某个属性,所以也就不需要对 keys 进行遍历。支持数组,Proxy 不需要对数组的方法进行重载,省去了众多 hack,减少代码量等于减少了维护成本。
let obj = {
name: 'Eason',
age: 30
}
let handler = {
get (target, key, receiver) {
console.log('get', key)
return Reflect.get(target, key, receiver)
},
set (target, key, value, receiver) {
console.log('set', key, value)
return Reflect.set(target, key, value, receiver)
}
}
let proxy = new Proxy(obj, handler)
proxy.name = 'Zoe' // set name Zoe
proxy.age = 18 // set age 18let arr = [1,2,3]
let proxy = new Proxy(arr, {
get (target, key, receiver) {
console.log('get', key)
return Reflect.get(target, key, receiver)
},
set (target, key, value, receiver) {
console.log('set', key, value)
return Reflect.set(target, key, value, receiver)
}
})
proxy.push(4)
// 能够打印出很多内容
// get push (寻找 proxy.push 方法)
// get length (获取当前的 length)
// set 3 4 (设置 proxy[3] = 4)
// set length 4 (设置 proxy.length = 4)19.js的编译过程
网上也没有查到,面试官说是AU,GO
20.高阶函数
map():reduce():filter();filter也是一个常用的操作,它用于把Array的某些元素过滤掉,然后返回剩下的元素。和map()类似,Array的filter()也接收一个函数。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是true还是false决定保留还是丢弃该元素。sort排序算法
函数作为参数或者函数返回函数
array.reduce(function(total, currentValue, currentIndex, arr), initialValue)
total:必需。初始值, 或者计算结束后的返回值。currentValue:可选。当前元素的索引.
arr:可选。当前元素所属的数组对象。initialValue:可选。传递给函数的初始值function pow(x) {
return x * x;
}
var arr = [1, 2, 3, 4, 5, 6, 7, 8, 9];
arr.map(pow); // [1, 4, 9, 16, 25, 36, 49, 64, 81]
var arr=[1,2,3]
arr.reduce((pre,cur)=>{
return pre+cur
})//6
//例如,在一个Array中,删掉偶数,只保留奇数,可以这么写:
var arr = [1, 2, 4, 5, 6, 9, 10, 15];var r = arr.filter(function (x) {
return x % 2 !== 0;
});
r; // [1, 5, 9, 15]
var arr = [10, 20, 1, 2];
arr.sort((a,b)=>{
return a-b})// [1, 2, 10, 20]
20.函数柯里化
函数柯里化是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
function add(){
var args=Array.prototype.slice.call(arguments);
// 在内部声明一个函数,利用闭包的特性保存_args并收集所有的参数值
var adder=function(){
args.push(...arguments)
return adder;
}
// 利用toString隐式转换的特性,当最后执行时隐式转换,并计算最终的值返回
adder.toString=function(){
return adder.reduce((a,b)=>{
return a+b}
)
}
return adder;
}
add(1)(2)(3) // 6add(1, 2, 3)(4) // 10add(1)(2)(3)(4)(5) // 15
21.import,require,link的区别
node编程中最重要的思想就是模块化,
import和require都是被模块化所使用。遵循规范
require是 AMD规范引入方式import是es6的一个语法标准,如果要兼容浏览器的话必须转化成es5的语法
调用时间
- require是运行时调用,所以require理论上可以运用在代码的任何地方
- import是编译时调用,所以必须放在文件开头
本质
- require是赋值过程,其实require的结果就是对象、数字、字符串、函数等,再把require的结果赋值给某个变量
- import是解构过程,但是目前所有的引擎都还没有实现import,我们在node中使用babel支持ES6,也仅仅是将ES6转码为ES5再执行,import语法会被转码为require
22.pwa,amt了解么
PWA并不是单指某一项技术,你更可以把它理解成是一种思想和概念,目的就是对标原生app,将Web网站通过一系列的Web技术去优化它,提升其安全性,性能,流畅性,用户体验等各方面指标,最后达到用户就像在用app一样的感觉。
PWA中包含的核心功能及特性如下:
- Web App Manifest
- Service Worker
- Cache API 缓存
- Push&Notification 推送与通知
- Background Sync 后台同步
- 响应式设计
23.缓存机制(强缓存,协商缓存,本地缓存)
24.介绍一下WebSocket
WebSocket 使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在 WebSocket API 中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
在 WebSocket API 中,浏览器和服务器只需要做一个握手的动作,然后,浏览器和服务器之间就形成了一条快速通道。两者之间就直接可以数据互相传送。
现在,很多网站为了实现推送技术,所用的技术都是 Ajax 轮询。轮询是在特定的的时间间隔(如每1秒),由浏览器对服务器发出HTTP请求,然后由服务器返回最新的数据给客户端的浏览器。这种传统的模式带来很明显的缺点,即浏览器需要不断的向服务器发出请求,然而HTTP请求可能包含较长的头部,其中真正有效的数据可能只是很小的一部分,显然这样会浪费很多的带宽等资源。
HTML5 定义的 WebSocket 协议,能更好的节省服务器资源和带宽,并且能够更实时地进行通讯。
25.前端安全
主要有两种xss,CSRF攻击
xss:
在项目开发中,评论是个常见的功能,如果直接把评论的内容保存到数据库,那么显示的时候就可能被攻击。
当前用户的登录凭证存储于服务器的 session 中,而在浏览器中是以 cookie 的形式存储的。如果攻击者能获取到用户登录凭证的 Cookie,甚至可以绕开登录流程,直接设置这个 Cookie 值,来访问用户的账号。
防御:
httpOnly: 在 cookie 中设置 HttpOnly 属性后,js脚本将无法读取到 cookie 信息。对一些字符进行转义:& --> & < --> < > -->> " --> " ' --> ' / --> /
csrf:跨站点请求伪造(Cross-Site Request Forgeries),也被称为 one-click attack 或者 session riding。冒充用户发起请求(在用户不知情的情况下), 完成一些违背用户意愿的事情(如修改用户信息,删初评论等)。
案例:
- 比如某网站的转账操作
- 受害者张三给李四转账100
防御
- 验证码;强制用户必须与应用进行交互,才能完成最终请求。此种方式能很好的遏制 csrf,但是用户体验比较差。
- 尽量使用 post ,限制 get 使用;上一个例子可见,get 太容易被拿来做 csrf 攻击,但是 post 也并不是万无一失,攻击者只需要构造一个form就可以。
- Referer check;请求来源限制,此种方法成本最低,但是并不能保证 100% 有效,因为服务器并不是什么时候都能取到 Referer,而且低版本的浏览器存在伪造 Referer 的风险。
- token;token 验证的 CSRF 防御机制是公认最合适的方案
28.nodejs用过什么?nodeJs事件怎么循环的
- timers: 这个阶段执行定时器队列中的回调如
setTimeout()和setInterval()。 - I/O callbacks: 这个阶段执行几乎所有的回调。但是不包括close事件,定时器和
setImmediate()的回调。 - idle, prepare: 这个阶段仅在内部使用,可以不必理会。
- poll: 等待新的I/O事件,node在一些特殊情况下会阻塞在这里。
- check:
setImmediate()的回调会在这个阶段执行。 - close callbacks: 例如
socket.on('close', ...)这种close事件的回调。
29.koa和express框架的区别
Koa 利用 co 作为底层运行框架,利用 Generator 的特性,实现“无回调”的异步处理,路由处理 Express 是自身集成的,而 Koa 需要引入中间件。
var koa = require('koa')
var route = require('koa-route') //中间件
var app = koa()
app.use(route.get('/', function *(){
this.body = 'Hello World'
}))面试官概括说koa中间件要自己加,express自集成了好多中间件。
30.koa-body的原理,服务器的渲染
这个没有查到
31.描述react的生命周期
第一个是组件初始化(initialization)阶段
第二个是组件的挂载(Mounting)阶段
此阶段分为componentWillMount,render,componentDidMount三个时期。
- componentWillMount:
在组件挂载到DOM前调用,且只会被调用一次,在这边调用this.setState不会引起组件重新渲染,也可以把写在这边的内容提前到constructor()中,所以项目中很少用。
- render:
根据组件的props和state(无两者的重传递和重赋值,论值是否有变化,都可以引起组件重新render) ,return 一个React元素(描述组件,即UI),不负责组件实际渲染工作,之后由React自身根据此元素去渲染出页面DOM。render是纯函数(Pure function:函数的返回结果只依赖于它的参数;函数执行过程里面没有副作用),不能在里面执行this.setState,会有改变组件状态的副作用。
- componentDidMount:
组件挂载到DOM后调用,且只会被调用一次
第三个是组件的更新(update)阶段
在componentWillReceiveProps方法中,将props转换成自己的state
在该函数(componentWillReceiveProps)中调用 this.setState() 将不会引起第二次渲染。
此阶段分为componentWillReceiveProps,shouldComponentUpdate,componentWillUpdate,render,componentDidUpdate
卸载阶段
此阶段只有一个生命周期方法:componentWillUnmount
- componentWillUnmount
此方法在组件被卸载前调用,可以在这里执行一些清理工作,比如清楚组件中使用的定时器,清楚componentDidMount中手动创建的DOM元素等,以避免引起内存泄漏。
新引入了两个新的生命周期函数:getDerivedStateFromProps,getSnapshotBeforeUpdate
getDerivedStateFromProps本来(React v16.3中)是只在创建和更新(由父组件引发部分),也就是不是不由父组件引发,那么getDerivedStateFromProps也不会被调用,如自身setState引发或者forceUpdate引发。getSnapshotBeforeUpdate()
被调用于render之后,可以读取但无法使用DOM的时候。它使您的组件可以在可能更改之前从DOM捕获一些信息(例如滚动位置)。此生命周期返回的任何值都将作为参数传递给componentDidUpdate()。
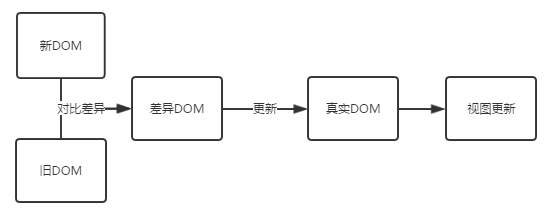
32.描述一下diff算法,diff算法是怎么对比两个节点的
33.react怎么进行路由的动态加载
根据官方文档中的 Code Splitting 部分,实现动态加载需要 webpack,babel-plugin-systax-dynamic-import和react-loadable。
修改后:
<Route exact path="/settings"
component={Loadable({
loader: () => import(/* webpackChunkName: "Settings" */ './Settings.js'),
loading:Loading
})}
/>34.redux的原理,redux为什么能进行跨组件传值
react-redux是一个轻量级的封装库,核心方法只有两个:
- Provider
- connect
核心是观察者模式,观察者模式又叫发布-订阅模式,它定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖它的对象都将得到通知
//observes.js
import React, { Component, PropTypes } from 'react';
import pick from 'lodash/object/pick';
const contextTypes = {
observeStores: PropTypes.func.isRequired
};
export default function connect(...storeKeys) {
return function (DecoratedComponent) {
const wrappedDisplayName = DecoratedComponent.name;
return class extends Component {
static displayName = `ReduxObserves(${wrappedDisplayName})`;
static contextTypes = contextTypes;
constructor(props, context) {
super(props, context);
this.handleChange = this.handleChange.bind(this);
this.unobserve = this.context.observeStores(storeKeys , this.handleChange); //订阅store数据
}
handleChange(stateFromStores) {
this.currentStateFromStores = pick(stateFromStores, storeKeys);
this.updateState(stateFromStores);
}
updateState(stateFromStores, props) {
stateFromStores = stateFromStores[storeKeys[0]];
const state = stateFromStores;
this.setState(state);//通过setState进行组件更新
}
componentWillUnmount() {
this.unobserve();//退订
}
render() {
return (
<DecoratedComponent {...this.props}
{...this.state} />
);
}
};
};
}35.react的组件是怎么通讯的
36.hooks
- 其实
HOC和Vue中的mixins作用是一致的,并且在早期React也是使用mixins的方式。但是在使用class的方式创建组件以后,mixins的方式就不能使用了,并且其实mixins也是存在一些问题的,比如
37.描述一下contex是怎么用的,组建通信
blog.poetries.top/FE-Intervie…
38.react中怎么引用样式
三种方法引入样式,{{}},style等于一样变量的方式引入,引入一个css的文件
39.描述下虚拟dom
在第一步算法中我们需要判断新旧节点的tagName是否相同,如果不相同的话就代表节点被替换了。如果没有更改tagName的话,就需要判断是否有子元素,有的话就进行第二步算法。在第二步算法中,我们需要判断原本的列表中是否有节点被移除,在新的列表中需要判断是否有新的节点加入,还需要判断节点是否有移动。
40.vue的生命周期
41.vuex
42.在那个生命周期不可以发送ajax请求
43.vue-router的原理,怎么监听hash,histoty的变化
vue-router 默认模式是 hash 模式 —— 使用 URL 的 hash 来模拟一个完整的 URL,当 URL 改变时,页面不会去重新加载。
hash(#)是URL 的锚点,代表的是网页中的一个位置,单单改变#后的部分(/#/..),浏览器只会加载相应位置的内容,不会重新加载网页,也就是说 #是用来指导浏览器动作的,对服务器端完全无用,HTTP请求中不包括#;同时每一次改变#后的部分,都会在浏览器的访问历史中增加一个记录,使用”后退”按钮,就可以回到上一个位置;所以说Hash模式通过锚点值的改变,根据不同的值,渲染指定DOM位置的不同数据。通过hashChange事件来监听URL的变化。
window.addEventListener('hashchange',()=>{//具体逻辑})HTML5 History API提供了一种功能,能让开发人员在不刷新整个页面的情况下修改站点的URL,就是利用 history.pushState API 来完成 URL 跳转而无须重新加载页面;
由于hash模式会在url中自带#,如果不想要很丑的 hash,我们可以用路由的 history 模式,只需要在配置路由规则时,加入"mode: 'history'",这种模式充分利用 history.pushState 和hostoty.replaceState改变URL,用户后退的时候会触发popState事件
history.pushSate(stateObject,title,URL)//新增历史记录
history.replaceState(stateObject,title,URl)//替换当前的历史记录当用户点击按钮回退会触发popStae事件
window.addEventListner('popState',e=>{
})两种模式的对比:
hash模式只可以改变#后面的内容,history模式可以通过api设置任意的同源URL
History模式可以通过api添加任意的数据到历史记录中,hash模式只能更改哈希值
hash模式无需后端配置兼容性比较好。history模式在用户手动输入地址或者刷新页面的时候发起uRL请求,后端需要配置index.html页面匹配不到资源的时候。
44.mvvm描述
45.vue双向绑定原理
46.vuex
原理运用了单例模式
let Vue;class Store{ constructor(options){ this.vm = new Vue({ // new Vue 会创建vue的实例 将状态变成响应式的 如果数据更新 则试图刷新 data:{state:options.state} }); this.state = this.vm.state this.mutations = options.mutations; this.actions = options.actions; } commit = (eventName)=>{ this.mutations[eventName](this.state) } dispatch = (eventName) =>{ this.actions[eventName](this); }}const install = (_Vue)=>{ Vue = _Vue; Vue.mixin({ beforeCreate(){ if(this.$options && this.$options.store){ this.$store = this.$options.store }else{ this.$store = this.$parent && this.$parent.$store } } })}export default { Store, install}47.vue-cli实现原理,vue-cli底层原理是怎么创建项目的,怎么把项目创建起来。
面试官说是通过命令行的配置,从远程仓库拉下来的
48,v-if,v-show的区别
49.v-if和v-for的优先级
面试官说v-if的优先级要高于v-for,因为在循环列表时候要判断数据是否存在
50.keep-alive是怎么缓存的
缓存动态组件:
使用keep-alive可以将所有路径匹配到的路由组件都缓存起来,包括路由组件里面的组件,keep-alive大多数使用场景就是这种。
<keep-alive>
<router-view></router-view>
</keep-alive>
新增属性:
include:匹配的 路由/组件 会被缓存exclude:匹配的 路由/组件 不会被缓存 <keep-alive include="a,b">
<keep-alive include="a,b">
<component :is="view"></component>
</keep-alive>
<!-- 正则表达式 (使用 `v-bind`) -->
<keep-alive :include="/a|b/">
<component :is="view"></component>
</keep-alive>
<!-- 数组 (使用 `v-bind`) -->
<keep-alive :include="['a', 'b']">
<component :is="view"></component>
</keep-alive>51.vue的循环列表为什么要加key
主要是为了更快的进行diff算法
52.vue监听字段的变化
发布订阅者模式
把函数push到一个数组里面,然后循环数据调用函数
var arr=[];
let a=()=>{console.log(a)}
arr.push(a)//订阅a函数
arr.push(a)//又订阅a函数
arr.forEach(fn=>fn())//发布所有
//订阅类
class Dep{
constructor(){
this.subs=[]
}
//订阅函数
addSub(sub){
this.subs.push(sub)
}
//发布函数
notify(){
this.subs.filter(item=>typeof item !=='string').forEach(sub=>sub.update())}
}前端路由
美团的面试题:
1.var a = ?;
a == 1 && a == 2 && a == 3
用toString的方法
a={
i:1,
toString():function(){
return a.i++
}
}
a==1 && a==2 && a==3 //true
let a = {
i: 1,
valueOf () {
return a.i++
}
}
a==1 && a==2 && a==3 //truelet a={
fg:(function*(){
yield 1;
yield 2;
yield 3;
})(),
valueof(){
this.fg()next().value
}
}
a==1 && a==2 && a==3 //trueObject.defineProperty(window, 'a', {
get: function() {
return this.value = this.value ? (this.value += 1) : 1;
}
});
a==1 && a==2 && a==3//true3.查出是杨辉三角,写出(m,n)的结果
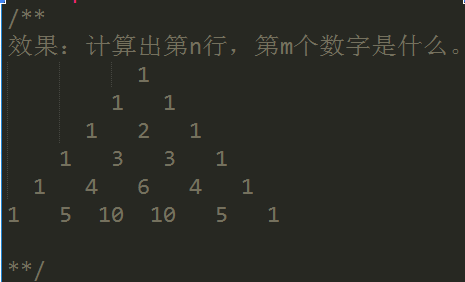
function findNum(n,m){ if(m>n){ return false; } if(m==1 || m==n){ return 1; } if(m==2 || m==n-1){ return n-1; } return findNum(n-1,m) + findNum(n-1,m-1);}console.log(findNum(7,5)) //154.var arrArrs = [{ name: 1, lableName: '小明' }, { name: 2, lableName: '小李' }, { name: 1, lableName: '小王' }, { name: 3, lableName: '校招' }, { name: 4, lableName: '小云' }];要求把最后的结果合并成为[1,“小明”,“小王”],[2,"小李"],[3,"校招"]
let map = {};
for(let i in arrArrs) {
console.log(i, arrArrs[i]['lableName']);
map[arrArrs[i]['name']] =
Array.isArray(map[arrArrs[i]['name']]) ?
[...map[arrArrs[i]['name']], arrArrs[i]['lableName']]:
[arrArrs[i]['name'], arrArrs[i]['lableName']]
}
console.log(map);