

reactor模式是node异步的核心,比如node的单线程和非阻塞I/O。下面从I/O去理解Reactor模式
I/O
I(input)/O(out)它是缓慢的,比如
- 访问RAM的时间为ns级别(10E-9s),访问磁盘或者网络上的数据则为ms级别(10E-3s),宽带也是一样的。
- I/O对CPU而言通常代价不是很高,但是它在请求发送的时刻和操作完成的时刻增加了一个延迟。
- 人为因素,例如单击按钮或聊天软件中发送的新消息
所以I/O可以比磁盘或网络满许多个数量级
阻塞I/O
传统阻塞I/O编程中,与I/O请求相对应的函数将阻塞线程的执行,直到操作完成。
看一下它的执行流程
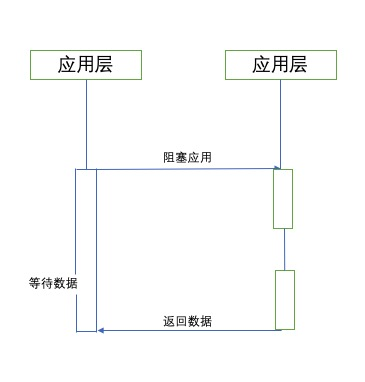
- 比如我们同步执行写法,它直接返回结果的写法,不需要在回调函数中处理,它是顺序执行的,会发生阻塞,比如模拟阻塞
const fs = require('fs');
function filter (files = []) {
files.forEach( file => {
if(/^hello/.test(file)) {
console.log(file);
}
})
}
function sleep (seconds) {
const startTime = new Date().getTime();
while (new Date().getTime() < startTime + seconds)
}
const files = fs.readdirSync('.')
sleep(10000)
filter(files)
执行以上代码,sleep执行了10s 然后执行filter函数,所以同步虽好,要慎用,在node中,异步才是常态,最好要以异步的方式去思考和解决问题
- 典型的案例执行socket来阻塞线程的情况:
// 直到返回data,才开启线程
const data = socket.read();
// data 成功返回
console.log(data)
其实我们发现,阻塞I/O实现的web服务无法处理同一线程中的多个连接。socket上的每一个I/O操作将组织任何其他连接的处理。
这时候就要解决阻塞I/O带来的问题,其实在web服务中传统处理并发做法就是为每个连接开启一个线程或者进程(或者重用线程池中的进程)
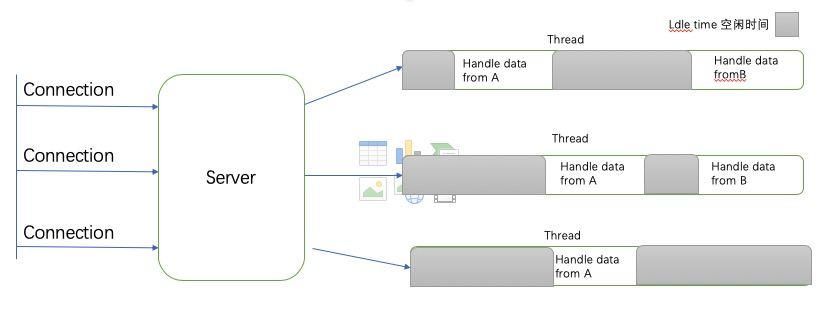
图很很清晰显示了每个线程的空闲的时间量,这个时间用于等待从相关连接接收新数据,另外还有阻塞I/O都有可能阻塞线程,造成整个线程阻塞。然而线程是个不便宜的系统资源,消耗内存,上下文切换,因此线程为一个连接长时间运行,并且大多数时间空闲的话,从效率和资源上来说不是一个最佳方案。
非阻塞I/O
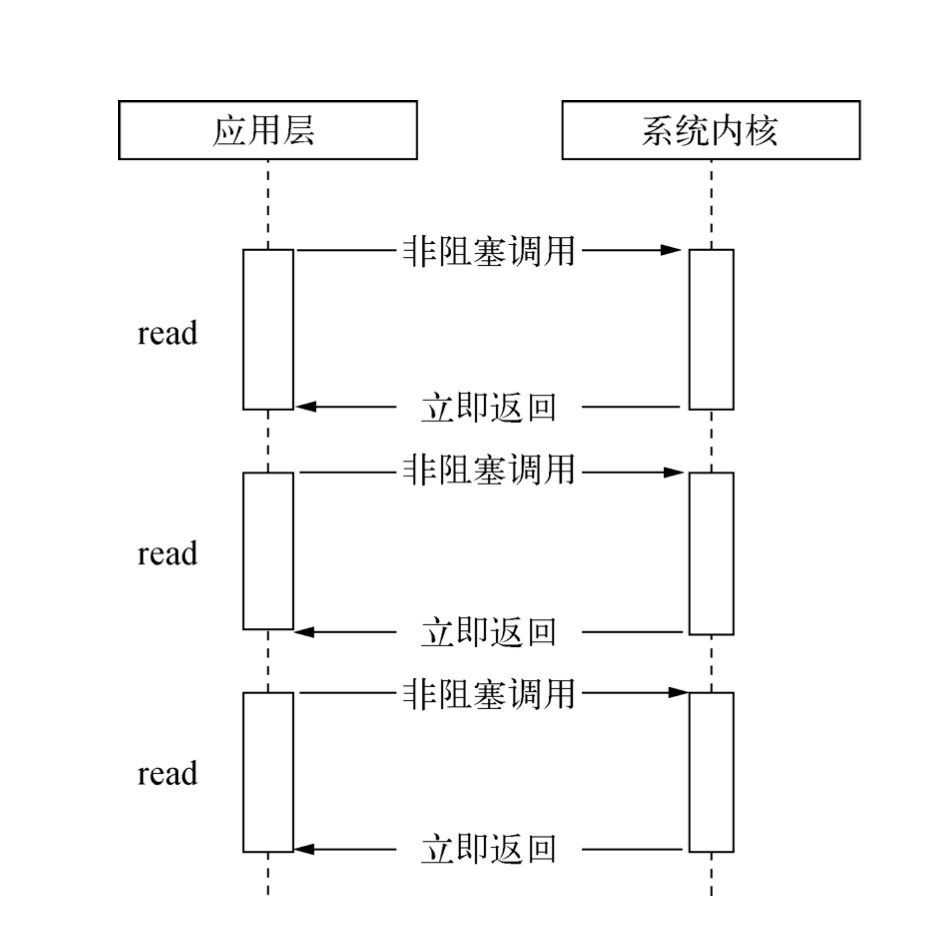
在非阻塞I/O操作模式下,系统调用总是立即返回的,无需等待读取或写入,如果在调用时候没有可用结果,则函数将简单返回预定义的常量,代表此时没有可用的返回数据。示意图如下
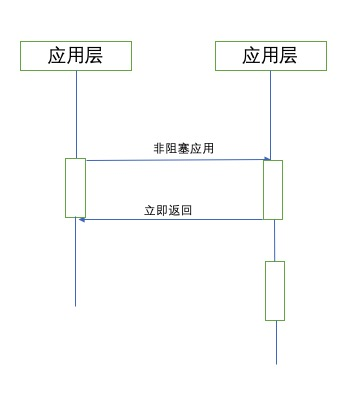
node在解决阻塞I/O并没有采用单线程串行执行,多线程并行完成,他们都存在很大的弊端。
所以node给出了一个解决方案,利用单线程,远离多线程死锁,状态同步,效率低下等问题,利用异步异步I/0,让单线程远离阻塞,更好地利用CPU。异步I/O也算是node的特色,因为它是首个大规模将异步I/O应用在应用上的平台,力求在单线程上将资源分配的更高效。以下是异步I/O调用示意图
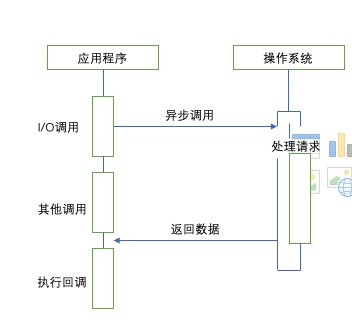
异步I/O最核心的是EventLoop,它和Ajax有异曲同工之处,ajax核心是XHR(XMLHttpRequest)如下对比图一目了然。
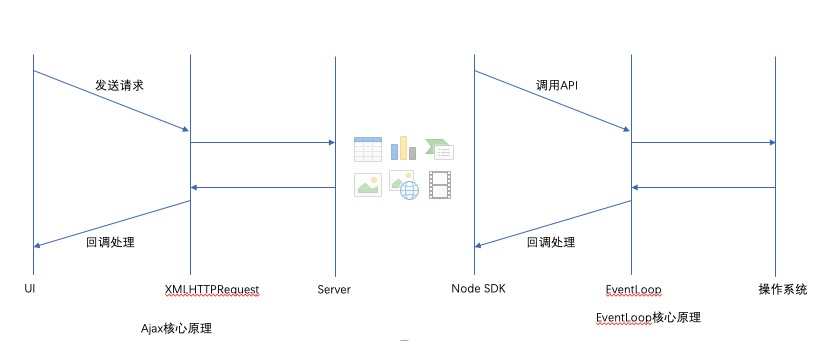
顺便简单说一下ajax和Eventloop执行原理
ajax:它定义好回调后,剩下事情会交给XHR处理,XHR与服务器交互会产生时间差异,异步操作可以很好的解决这个问题,不许要刷新页面的情况下就可以获取数据
EventLoop:调用node api时候,操作和回调函数会交给evnetloop去执行,eventLoop维护了一个回调函数队列,当异步函数执行的时候,callback会被放入到这个队列,js引擎直到异步函数执行完成以后,才会开始处理Eventloop。EventLoop维护的是一个先进先出(FIFO)队列,说明回调函数在队列中顺序执行的。这里有一些特殊情况比如processNextTick和SetImediate, 这个先不说啦,以后会在将node同步事件和异步事件会仔细介绍。
忙碌等待模式
它是访问非阻塞I/O的最基本模式,它在循环内主动轮询资源,直到返回一些实际数据。
以下伪代码说明如何使用非阻塞I/O和轮询从多个资源中读取数据
const resources = [ socketA, socketB, socketC ];
while(!resources.isEmpty()) {
for ( i = 0; i < resources.lengtn; i++ ) {
resource = resoures[i]
// try to load
let data = resource.read();
if(data === NO_DATA_AVAILABLE) {
// 这是无用数据情况
continue
}
if(data === RESOURCE_CLOSED) {
// 资源被关闭,并移除
resources.remove()
}
else {
// 一些数据被结合搜,执行
consumeData(data)
}
}
}
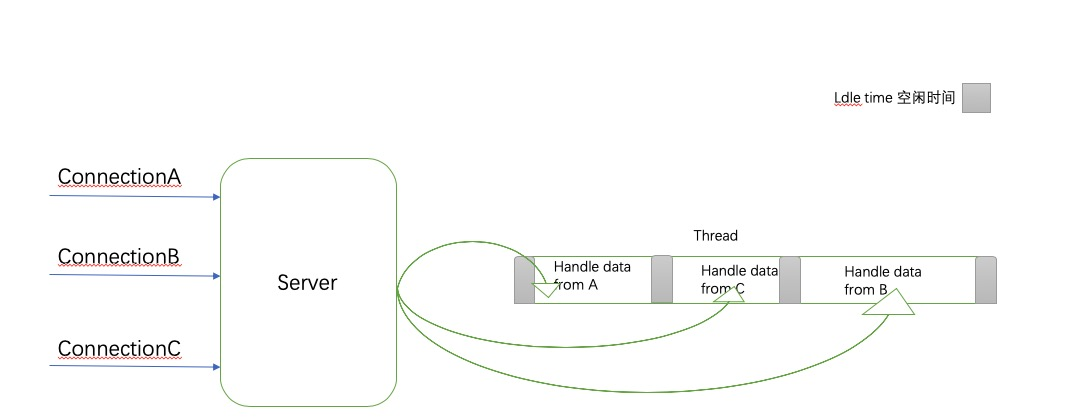
下面是其运行示意图
可以看到,我们已经可以在同一个线程中处理不同的资源, 但是它仍然效率不是很高,因为循环仅消耗宝贵的CPU时间来对大多数时间不可用资源进行迭代,轮询算法通常会导致大量的cpu时间浪费。另外还有其他几种轮询机制,会在将异步事件会详细介绍到。
事件多路分解器
该机制通过一种有效的方式处理并发和非阻塞资源,它被称之为同步事件多路分解器或事件通知接口,此组件收集并排列一套被监视的资源的i/o事件,并阻塞它们,直到有新事件处理它。
以下是通过使用此机制从两个不同资源读取数据
socketA, pipeB
watchedList.add(socketA, FOR_READ)
watchedList.add(pipeB, FOR_READ) // 将资源添加到数据结构,与具体操作关联,就是read事件
while(events = demultiplexer.watch(watchList)) { // 通过对资源组的监视,事件通知被设置,此调用是同步的,直到任何被监视的资源准备好进行read,此时,事件多路分解器从调用返回,有了一组新的事件用于处理
// eventloop
foreach(event in events) { // 处理事件多路分解器返回的每个事件,并保证和每个关联事件的资源被读取,并且在操作期间不被阻塞。处理完所有事件后,流再次阻塞多路分解器,直到有新的事件用于处理,这称之为事件循环
// this read will never block and will always return data
data = event.resource.read()
if(data === RESOURCE_CLOSED) {
// the resource was closedm remove it from the watchList
demultiplexer.unwatch(event.resource)
} else {
// some actual data was received, process it
consumeData(data)
}
}
}
使用这种模式,现在可以在单个线程处理多个I/O操作,无须使用忙碌等待技术,下图显示了web服务能够使用同步事件多路分解器和单个线程处理多个连接
该图清晰显示了使用同步事件分解器和非阻塞I/O的单线程应用程序中并发如何工作。单线程随着时间推移而传播,使线程总空闲时间最小,这个有点可以明显的看到。
Reactor模式
经过以上的了解其实不难发现它背后思想主要就是让一个处理程序与每个I/O操作相关联(在node中就是回调函数),在事件循环产生并发处理时立即调用相应的程序。结构图如图所示
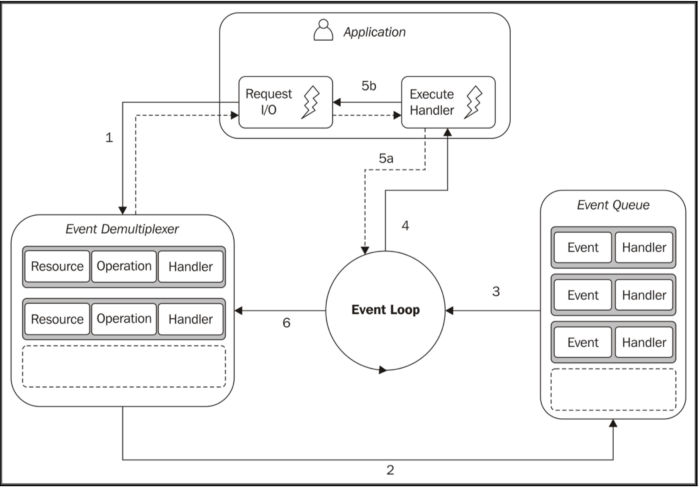
- 应用程序通过向Event Demultiplexer (事件多路分解器)提交请求。 生产新的i/o操作。应用程序还指定一个处理程序,操作完成时调用。向Demultiplexer提交请求是非阻塞调用,它立即将控制权返回给应用程序。
- 当一组i/o完成时Event Demultiplexer将新的event推入EventQueue。
- 此时,eventLoop遍历EventQueue。
- 对于每个事件,调用关联的处理程序。
- 处理完成是将控制权返回给eventLoop(5a)。如果出现新的异步操作(5b),这时新的操作差入Event Demultiplexer(1)。
- 当eventLoop所有事件处理完成时,再次阻塞Event Demultiplexer,但有新的事件可用时候,Event Demultiplexer将再出发一个周期。
总结:reactor通过阻塞来处理i/o,直到一组被观察资源的新事件可用,然后将每个事件分派到相关联的处理程序来作出反应。
libuv的非阻塞I/O引擎
每个操作系统有自己的Event Demultiplexer: linux:epoll;macox:kqueue;windows: IOCP。这些都是Event Demultiplexer的更高级抽象。这时候就有了node中的libuv,目的生死node与所有platform兼容,规范不同类型资源的非阻塞行为,它是node的底层i/o引擎。
libuv还提供了一系列api,用于创建事件循环,管理事件队列,运行异步i/o和排列其他类型任务
Reactor模式和libuv是node基本架构
来看一下node最终架构
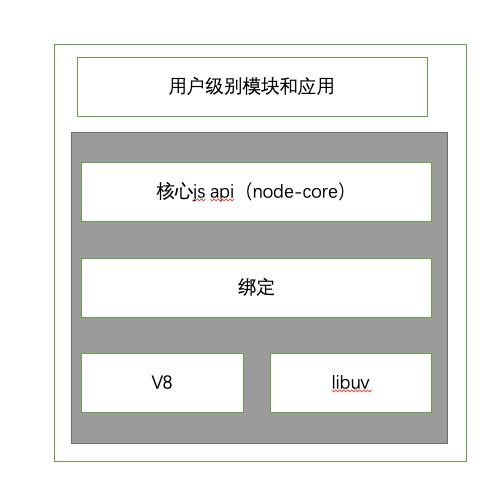
PS 第一次写相关类型文章,哈哈。希望能帮助有需要的人去理解相关内容。当然会存在一些问题,还请各位大佬见谅,希望大家能够一起学习,一起交流。
最后立个flag,以后每周坚持输出一篇到两篇自己这一周的所学所想。我一定能做到哈哈。
