

什么是 ZAB 协议
ZAB 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议
ZAB 协议包括两种基本模式,分别是奔溃恢复模式和消息广播模式
ZAB 协议的特性
-
ZAB 协议需要确保那些已经在 Leader 服务器上提交的事务最终被所有服务器提交
-
ZAB 协议需要丢弃那些只在 Leader 服务器上被提出的事务
第 2 点相信大家都很好理解,奔溃恢复过程中,发现当前的数据事务日志状态是非 commit 状态的日志都是无效的,都需要被丢弃,比如 Leader 发起 proposal 同步写请求给 follower 还没有收到 ack 或者还没有发出 commit 就挂了
关于第 1 点就存在一些疑问了,比如说如果 Leader 收到了过半服务器的 ACK 那么此时它就会异步发送 commit 给 follower 节点,同时自己也会去 commit,那么极端情况下 Leader commit 持久化磁盘成功,发送给 follower 由于网络等等原因导致 follower 没有接收到,此时正好 Leader 挂了,剩下的 Follower 节点会选出新的 Leader,epoch +1 进入新的 Leader 时代,此后之前失联的那台老的 Leader 重启恢复了,它会以 follower 的形式接入的新的集群中并且与 Leader 通信同步数据,这个时候老的 Leader 被 commit 的数据会被删除同步成新的 Leader 的数据,这一点从顺序一致性就能理解,如果再去还原老的 Leader 的 commit 数据那么新 Leader 在最新集群状态下处理的数据全部就变为无效了,如下图
发送给 follower 的由于网络等原因失败了,自己 commit 成功了,正好 Leader 挂了,由于选举新的 Leader 后会删除最新无效的数据所以 B C D E 节点 a = 1,A 节点 a = 3
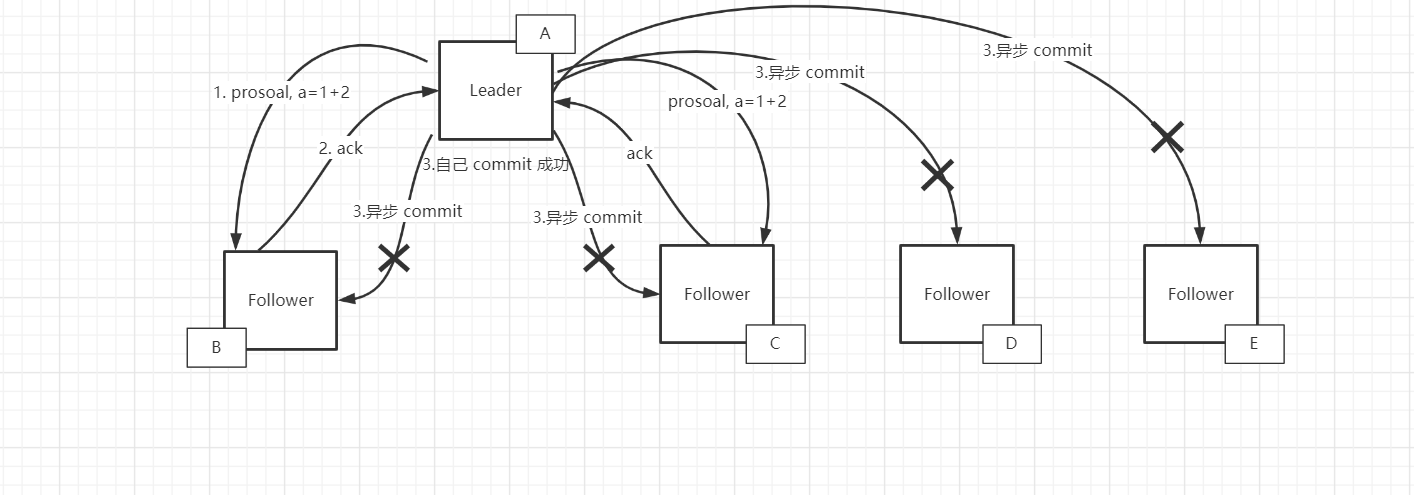
之后选举出新的 Leader 出来处理请求,经过一系列操作 a 最终变为了 100,此时原先的 A 结点恢复了,它的 a = 3 当然就只能抛弃被新的 Leader 同步为 a=100 了
当然这是思考过程,实际上的实现是,新选举出来的 Leader zxid 中的高 32 为 epoch 会加 1,这样意味着新选举出来的 zxid 一定会大于之前宕机的老 Leader 的最大的 zxid 这时候现在集群中的 Leader 就会要求新加入老 Leader(它会以 follower 的身份加入到集群)去同步更新集群中最新的数据,也就是发送新选举出来之后的所有的 prososal 然后追加 commit 让其同步完成,同步完成后它就会参与到处理客户端请求的过程中去
服务器结点的几种状态
leading:领导状态,一般称其为 Leader,所有的事务请求都必须由一个全局唯一的服务器来处理,这样的服务器被称作 Leader 服务器
followering:跟随者状态,一本称呼其为 Follower,参与 Leader 选举和请求 ack 的,当收到写请求的时候会转发给 Leader 结点,Leader 结点的写操作必须被超过半数 Follower(这个数量包括 Leader 自己) 提交后才会响应给客户端成功状态
observing:围观状态,一般称呼其为 Observer,它只同步最后的选举结果不参与选举也不参与 ack,对外只提供读服务,也会转发写请求给 Leader
looking:处于竞选状态中
由于 Observer 不参与选举所以后续的讲解不会涉及到该状态的节点服务器
奔溃恢复模式
集群启动过程中或者 Leader 出现网络中断、奔溃退出、重启等情况,ZAB 协议就会进入恢复模式选举出新的 Leader 服务器
当有新的服务器加入到集群中,如果此时已经存在 Leader 服务器了那么直接进入奔溃恢复模式
myid 是搭建集群的时候给服务器设置的 id 值
什么是 zxid
zxid 是一个 64 位的数字,其中低 32 位是一个单调递增的计数器,高 32 位则代表的是 Leader 周期的 epoch 的编号
每次写请求到达 Leader 的时候,Leader 都会广播给 Follower 其中就会携带 zxid,每次处理写请求,单调递增的计数器都会加一,这个计数器的值可以用来标识请求的先后顺序
epoch 它的释义有纪元、朝代的含义,王朝的更替,改朝换代,上一任 Leader 下台,这一任 Leader 登基,登基后 epoch 值加 1 表示开启新元年
启动时候 Leader 的选举过程
每个服务器告诉其它服务器自己想竞选 Leader,发起竞选的时候同时携带了自身的 zxid、myid、epoch 信息
每个节点都发出自己的 zxid、myid、epoch 等信息给其它节点表明我想要竞选 Leader
- 节点首先会去检测选票的有效性查看 epoch 是否是本轮投票并且检查投票者的状态是否是 looking 等
- 然后会先对比 zxid 谁的 zxid 大选谁
- 然后对比 myid 谁的 myid 大就投票给谁
- 只要得到半数以上的节点支持那么就选举成功
myid 大的节点去连接小的节点(小节点连接大节点不会成功,避免重复连接)
运行时候 Leader 选举过程
当 Leader 出现网络中断、奔溃退出、重启或者集群中有半数结点失去连接等情况就会发起新一轮 Leader 选举
只要集群中有过半数的节点存活那么集群就有效
- 比如集群 2 台服务器 1 台失效,集群失效
- 集群 3 台服务器 1 台失效,集群有效
- 集群 4 台服务器 1 台失效,集群有效,2 台失效集群无效
基于这个规律所以说一般情况下把 zookeeper 集群节点配置为奇数个节点更加有价值一些
区别在于如果是 Leader 失效了会发起新一轮 Leader 选举,如果是 follower 失效了那么不会发生新的选举,最新的 follower 上来后会同步 Leader 数据完成后参与到接收客户端请求中去
它的选举过程和启用选举是相似的,不过多了几点的是
- Leader 失效后新的 Follower 选举的时候会将 zxid 最大的并且是被 commit 状态的数据的节点选为准 Leader,当然如果有 2 个一样大,就对比他们的 myid,这样做的好处是它就不会再去同步其它节点最新的数据了,他的 zxid 最大意味着它包含了最新的事务修改操作
- 新的 Leader 选举出来后,肯定会跟集群其它机器通信对比下如果有谁的 zxid 落后了,就把落后的数据发送 prosoal 然后紧跟一个 commit 要求他们全部把数据同步好
- 当集群中有过半的节点数据同步好了,集群恢复到广播模式,开始处理客户端请求
消息广播模式
当集群中已经有过半的 Follower 服务器的数据已经完成了和 Leader 的数据同步就会进入消息广播模式
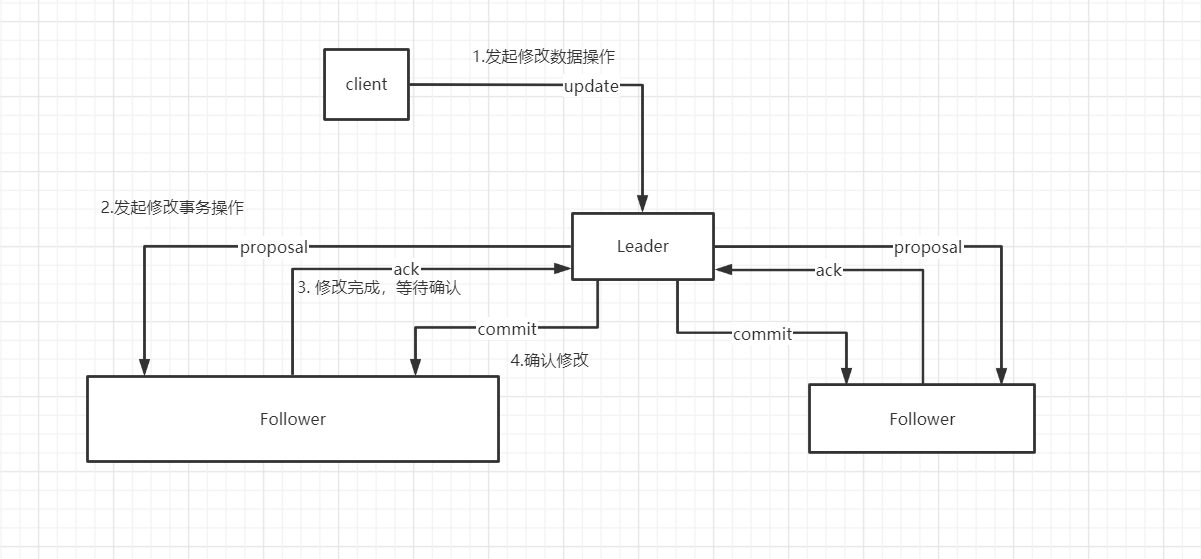
当集群中过半数 follower 节点返回 ack 后,Leader 就会异步发起 commit 要求 follower 提交事务,同时自己也会 commit 然后响应给客户端
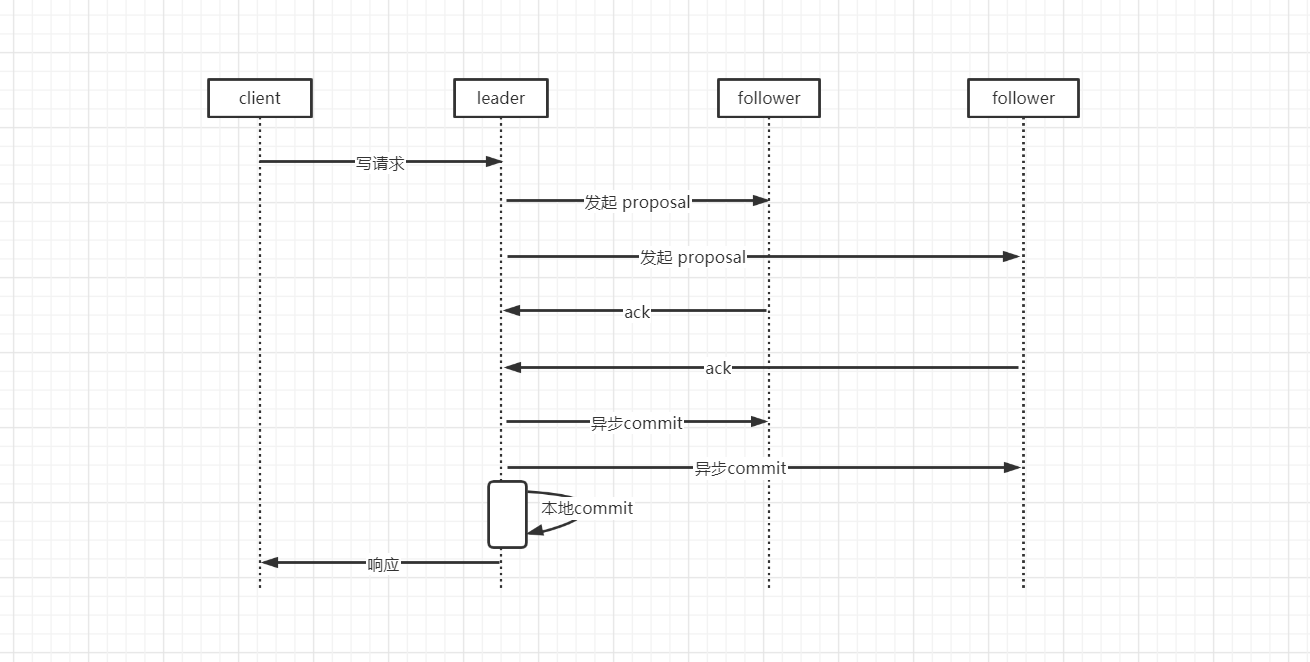
如果集群中其它的节点收到了写请求都会转发给 Leader 由 Leader 来统一发起
由于在处理客户端请求的过程中,集群机器可能会出现网络中断、奔溃退出、重启或者集群中有半数结点失去连接等问题,所以这个时候就需要配合奔溃恢复模式来恢复集群
Observer 服务器
Observer 只负责读请求,同时他需要同步 Leader 的写请求,不过它不参与过半数 ack 的统计,也不参与 Leader 选举,这样它就可以大幅度的提升集群的读性能
参考文献
- 从 Paxos 到 ZooKeeper 分布式一致性的原理和实践
