十大算法
1、选择排序
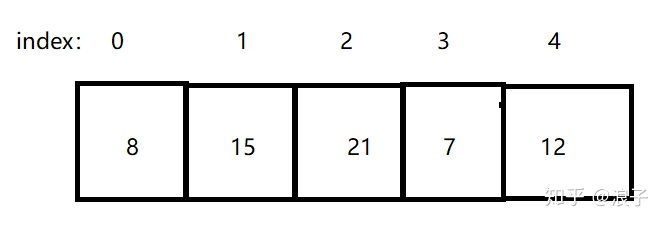
选择排序的思想是:如果一个数组按照升序排序,那么第一轮选出一个最小的元素放在0的位置,之后这个元素的位置就不需要再动了,第二轮选出剩余元素中最小的一个放在1的位置,如此循环。因此需要两层循环,外层循环控制选择的轮数,和数组长度有关,内层循环负责在剩余元素中寻找最小的一个,找到后将其放在合适的位置。如下图为排序前数组
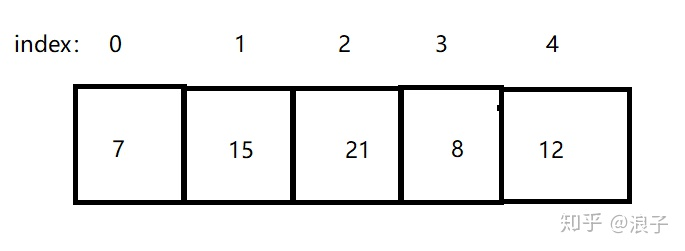
第一次排序,arr[3] = 7 最小,那么将7放入index=0的位置,第一次排序的结果为:
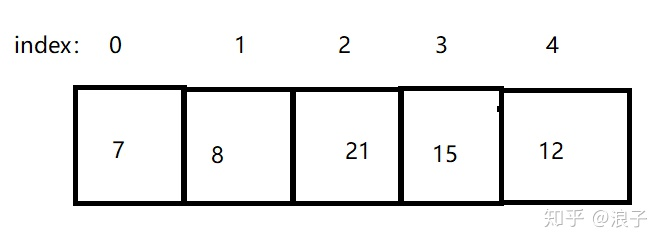
第二次排序,arr[3] =8最小,那么将8放到index=1的位置,排序结果为:
第三次排序,arr[4]=12最小,将12放入index=2中,排序结果为:
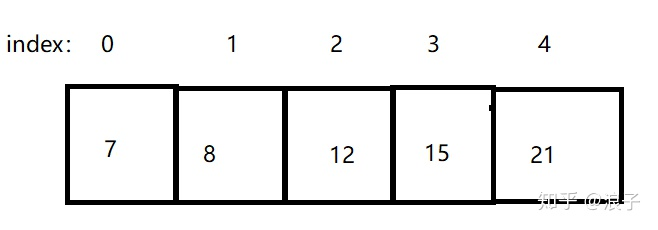
那么以此类推,后续排序思想跟前面三次排序如出一辙。
public class SelectionSort {
public static void main(String[] args) {
int[] arr=new int[]{8,15,21,7,12};
//输出排序前的数组:
System.out.println("排序前的数组:"+Arrays.toString(arr));
//调用排序方法:
sort(arr);
//输出排序后的数组:
System.out.println("排序后的数组:"+Arrays.toString(arr));
}
//选择排序:从小到大的顺序排列:
public static void sort(int[] arr){
for (int j = 1; j <=arr.length-1; j++) {
for (int i = j; i <=arr.length-1; i++) {
if(arr[j-1]>arr[i]){
//交换两个数:
int t;
t=arr[j-1];
arr[j-1]=arr[i];
arr[i]=t;
}
}
}
}
}
2、冒泡排序
1)基本概念:冒泡排序(Bubble Sort,台湾译为:泡沫排序或气泡排序)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端,故名。
请看下面引用网上的动态图可以更直观的了解冒泡排序的一个工作原理:
2) 算法描述:
1)i从0开始,i与i+1比较,如果i>i+1,那么就互换
2)i不断增加,直到i<n-1(n是数组元素的个数,n-1是数组的最后一个元素,一趟下来,可以让数组元素最大值排在数组的最后面)
从最简单开始,首先我们创建一个数组,这个数组有五个数字
int [] arrays = {2,5,1,3,4}
3) 第一趟排序
下面我们根据算法描述进行代码验算(第一趟排序)
//使用临时变量,让两个数互换
int temp;
//第一位和第二位比
if (arrays[0] > arrays[1]) {
//交换
temp = arrays[0];
arrays[0] = arrays[1];
arrays[1] = temp;
}
//第二位和第三位比
if (arrays[1] > arrays[2]) {
temp = arrays[1];
arrays[1] = arrays[2];
arrays[2] = temp;
}
//第三位和第四位比
if (arrays[2] > arrays[3]) {
temp = arrays[2];
arrays[2] = arrays[3];
arrays[3] = temp;
}
//第四位和第五位比
if (arrays[3] > arrays[4]) {
temp = arrays[3];
arrays[3] = arrays[4];
arrays[4] = temp;
}
3、插入排序
插入排序的基本操作就是将一个数据插入到已经排好序的数据中,从而得到一个新的,个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为O(n^2)。对于基本有序的数组最好用,稳定。
// 方法二 待排元素小于有序序列的最后一个元素时,向前插入
int temp;
for (int i = 1; i < a.length; i++) {
if(a[i] < a[i-1]){
temp = a[i];
for (int j = i; j >=0; j--) {
if(j >0 && a[j-1]>temp){
a[j] = a[j-1];
}else {
a[j] = temp;
break;
}
}
}
}
// 方法三
for(int i = 1;i < a.length;i++){
int temp1 = a[i];
int j = i-1;
while (j>=0 && a[j]>temp1){
a[j+1] = a[j]; // j=1 temp=3 a[j-1]=9
j--;
}
a[j+1] = temp1;
}
4、希尔排序
1)概念及实现
思想:分治策略
希尔排序是一种分组直接插入排序方法,其原理是:先将整个序列分割成若干小的子序列,再分别对子序列进行直接插入排序,使得原来序列成为基本有序。这样通过对较小的序列进行插入排序,然后对基本有序的数列进行插入排序,能够提高插入排序算法的效率。
具体如下**(实现为升序)**:
-
先取一个小于n的整数d1作为第一个增量,将所有距离为d1的倍数的记录放在同一个组中,把无序数组分割为若干个子序列。
-
在各子序列内进行直接插入排序。
-
然后取第二个增量d2<d1,重复步骤1~2,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
实现代码
public static void ShellSort(){ int [] arr ={89,-7,999,-89,7,0,-888,7,-7}; int length = arr.length; // 间隔增量,所有距离为space的倍数的记录放在同一个组里 int space = length/2; if(length > 1){ while (space >= 1){ ShellSort(arr,length,space); // 每次增量为原来的1/2 space = space / 2; } } for(int i = 0;i < arr.length;i++){ System.out.print(arr[i]+" "); } } public static void ShellSort(int arr [],int length,int space){ int i,j,k; // 将arr数组分为有序区和无序区,初始有序区只有一个元素 // 0-(i-1) 为有序区;i-(length-1)为无序区 for (i = space; i < length; i++) { int temp = arr[i]; // 边找位置边后移元素 for (j = i - space; j >= 0 && arr[j]>temp; ) { // 如果已排序的元素大于新元素,将该元素移到下一位置 arr[j + space] = arr[j]; j = j - space; } // 将 arr[i] 放到正确位置上 arr[j + space] = temp; } }2)算法复杂度
1)时间复杂度: O(nlog2n)
希尔排序耗时的操作有:比较 + 后移赋值。时间复杂度如下:
-
最好情况:序列是升序排列,在这种情况下,需要进行的比较操作需(n-1)次。后移赋值操作为0次。即O(n)
-
最坏情况:O(nlog2n)。
-
渐进时间复杂度(平均时间复杂度):O(nlog2n)
增量选取:希尔排序的时间复杂度与增量的选取有关,但是现今仍然没有人能找出希尔排序的精确下界。一般的选择原则是:取上一个增量的一半作为此次序列的划分增量。首次选择序列长度的一半为增量。(因此也叫
缩小增量排序) 平均时间复杂度:O(nlog2n),希尔排序在最坏的情况下和平均情况下执行效率相差不是很多,与此同时快速排序(O(log2n))在最坏的情况下执行的效率会非常差。专家们提倡,几乎任何排序工作在开始时都可以用希尔排序,若在实际使用中证明它不够快,再改成快速排序这样更高级的排序算法.
2)空间复杂度:O(1)
从实现原理可知,希尔排序是在原输入数组上进行后移赋值操作的(称“就地排序”),所需开辟的辅助空间跟输入数组规模无关,所以空间复杂度为:O(1)
3)稳定性
希尔排序是不稳定的。因为在进行分组时,相同元素可能分到不同组中,改变相同元素的相对顺序。
4优化改进
根据实际运行情况,我们也可以将希尔排序中查找插入位置部分的代码替换为二分查找方式。
-
5、归并排序
6、快速排序
7、计数排序
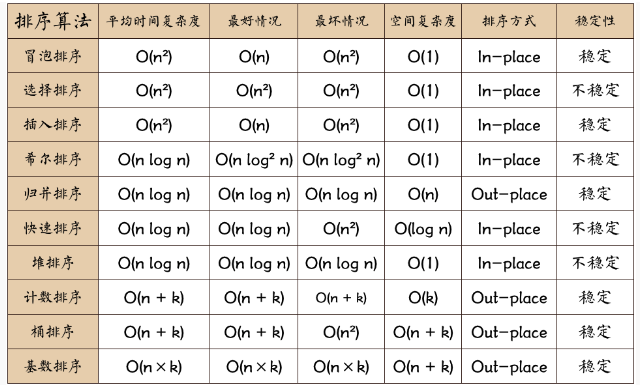
十大算法排序效率时间、空间复杂度对比