

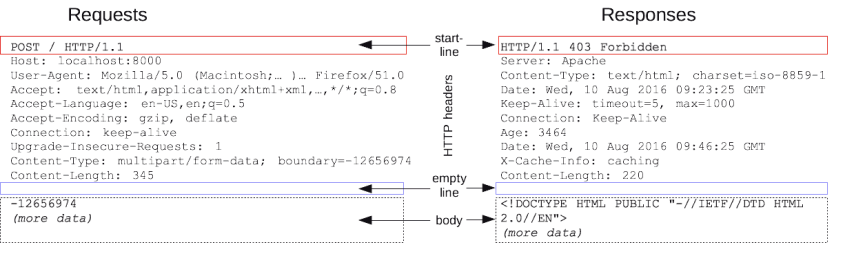
什么是HTTP消息?
HTTP消息指的是服务器和客户端之间交换数据的方式。有两种类型的消息︰ 请求(requests)--由客户端发送用来触发一个服务器上的动作;响应(responses)--来自服务器的应答。
HTTP消息由采用ASCII编码的多行文本构成。在HTTP/1.1及早期版本中,这些消息通过连接公开地发送。在HTTP/2中,为了优化和性能方面的改进,曾经可人工阅读的消息被分到多个HTTP帧中。
Web 开发人员或网站管理员,很少自己手工创建这些原始的HTTP消息︰ 由软件、浏览器、 代理或服务器完成。他们通过配置文件(用于代理服务器或服务器),API (用于浏览器)或其他接口提供HTTP消息。

HTTP/2二进制框架机制被设计为不需要改动任何API或配置文件即可应用︰ 它大体上对用户是透明的。
HTTP消息格式
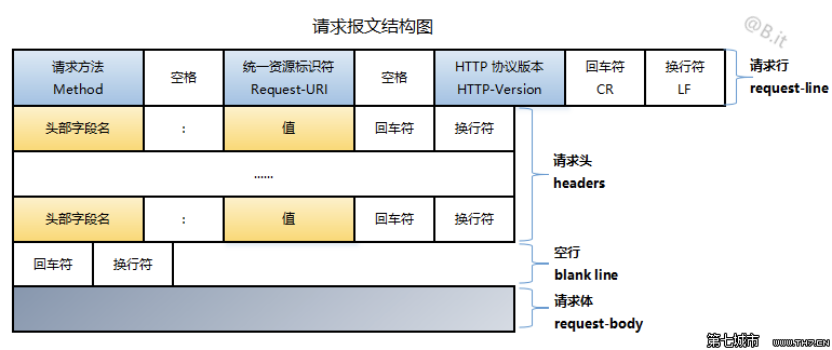
HTTP 请求和响应具有相似的结构,由以下部分组成︰
- 一行起始行用于描述要执行的请求,或者是对应的状态,成功或失败。这个起始行总是单行的。
- 一个可选的HTTP头集合指明请求或描述消息正文。
- 一个空行指示所有关于请求的元数据已经发送完毕。
- 一个可选的包含请求相关数据的正文 (比如HTML表单内容), 或者响应相关的文档。
起始行和HTTP 消息中的HTTP 头统称为请求头,而其有效负载被称为消息正文。
所有http/1.1消息都由一个起始行和一系列八位字节组成,其格式与internet邮件格式类似:零个或多个标头字段。空行表示标头部分的末尾,以及可选的消息正文。
HTTP-message = start-line
*( header-field CRLF )
CRLF
[ message-body ]
Start line
HTTP消息可以是客户端到服务器的请求,也可以是服务器到客户端的响应。从理论上讲,客户端可以接收请求,而服务器可以接收响应,通过不同的起始行格式来区分它们,但是实际上,服务器的实现只希望收到请求(响应被解释为未知或无效的请求方法),并且客户端仅期望响应。
start-line = request-line / status-line
request line
请求行以方法开头,后跟一个空格(SP),请求目标,另一个单个空格(SP),协议版本,并以CRLF(回车换行符)结尾。
request-line = method SP request-target SP HTTP-version CRLF
起始行 (start-line) 包含三个元素:
- 请求方法,一个 HTTP 方法,一个动词 (像 GET, PUT 或者 POST) 或者一个名词 (像 HEAD 或者 OPTIONS), 描述要执行的动作。例如, GET 表示要获取资源,POST 表示向服务器推送数据 (创建或修改资源, 或者产生要返回的临时文件)。注意区分大小写。
- 请求目标 (request target),通常是一个 URL,或者是协议、端口和域名的绝对路径,通常以请求的环境为特征。请求目标的格式因不同的 HTTP 方法而异。它可以是:
- 一个绝对路径,末尾跟上一个 ' ? ' 和查询字符串。这是最常见的形式,称为原始形式(origin form),被 GET,POST,HEAD 和 OPTIONS 方法所使用。
POST / HTTP 1.1 HEAD /test.html?query=alibaba HTTP/1.1- 一个完整的URL,被称为绝对形式 (absolute form),主要在使用 GET 方法连接到代理时使用。
GET http://developer.mozilla.org/en-US/docs/Web/HTTP/Messages HTTP/1.1- 由域名和可选端口(以':'为前缀)组成的 URL 的 authority component,称为 authority form。 仅在使用 CONNECT 建立HTTP隧道时才使用。
CONNECT developer.mozilla.org:80 HTTP/1.1- 星号形式 (asterisk form),一个简单的星号('*'),配合 OPTIONS 方法使用,代表整个服务器。
OPTIONS * HTTP/1.1 - HTTP 版本 (HTTP version),定义了剩余报文的结构,作为对期望的响应版本的指示符。
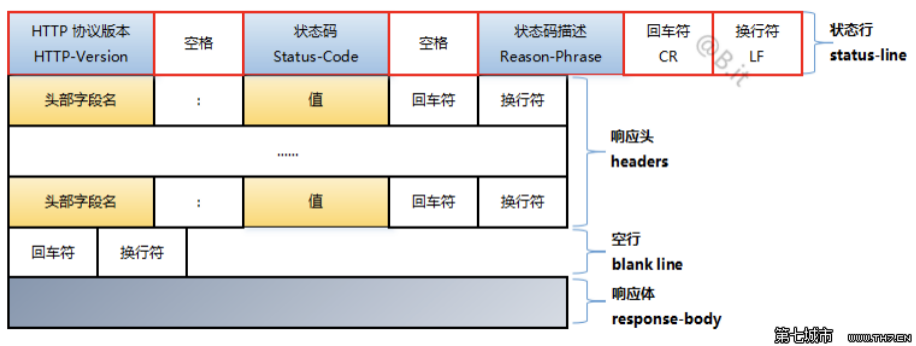
status line
HTTP 响应的起始行被称作状态行 (status line),包含以下信息:
- 协议版本,通常为 HTTP/1.1。
- 状态码 (status code),表明请求是成功或失败。常见的状态码是 200,404,或 301。
- 状态文本 (status text)。一个简短的,纯粹的信息,通过状态码的文本描述,帮助人们理解该 HTTP消息。
一个典型的状态行看起来像这样:HTTP/1.1 200 OK。
响应消息的第一行是状态行,包括协议版本,空格(SP),状态代码,另一个空格,可能是空的描述状态代码的文字短语,并以CRLF结尾。
status-line = HTTP-version SP status-code SP reason-phrase CRLF
状态行 = 协议版本 + 空格 + 状态码 + 空格 + 状态码描述 + 回车符 + 换行符
状态代码是3位整数代码,用于描述服务器尝试理解并满足客户要求的结果相应的请求。 原因短语的存在仅是为了提供一个与数字状态代码关联的文字描述,主要是不符合早期的Internet应用协议更常用于交互式文本客户端,客户应忽略原因短语内容。
Header field
来自请求的 HTTP headers 遵循和 HTTP header 相同的基本结构:不区分大小写的字符串,紧跟着的冒号 (':') 和一个结构取决于 header 的值。 整个 header(包括值)由一行组成,这一行可以相当长。

每个标题字段均包含一个不区分大小写的字段名,后跟冒号(“:”),可选的前导空格,字段值和可选的尾随空白。
header-field = field-name : OWS field-value OWS
字段名称标记将相应的字段值标记为具有该标头字段定义的语义。
顺序:理论上头字段的key顺序是无所谓的,但是最佳实践是将控制字段放在前面,比如请求的时候Host,响应的Date,这样可以尽快发现是否需要处理。
重复:除了Set-Cookie这个key,其他都不行,如果发送方发了重复的key,接收方会将它合并,值是以逗号分隔。
字段限制:协议本身对每个头字段没有限制,但是在工程实践中得出过一些实践,没有通用的限制,和字段具体的语义有关。整体的header大小限制没有定义标准值,有些4K,有些8K。server端检查到header头超过了限制值,处于安全考虑,不会忽略掉。而是会抛出4XX错误。
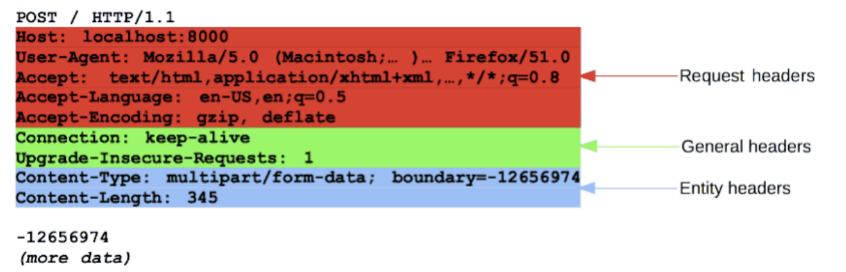
有许多请求头可用,它们可以分为几组:
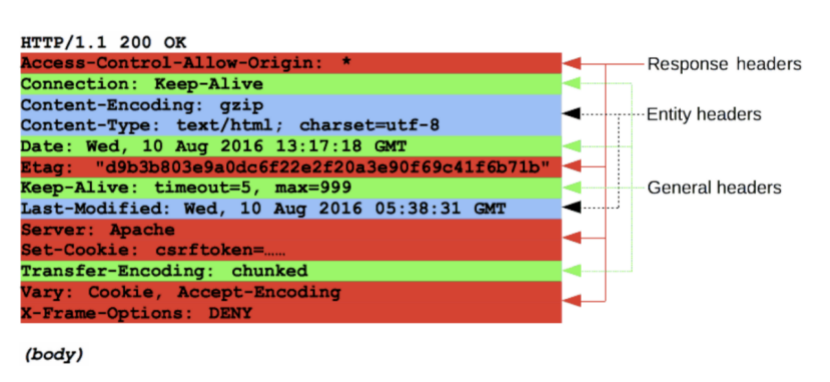
General headers,例如 Via,适用于整个报文。Request headers,例如 User-Agent,Accept-Type,通过进一步的定义(例如 Accept-Language),或者给定上下文,或者进行有条件的限制 (例如 If-None) 来修改请求。Response headers,例如 Vary 和 Accept-Ranges,提供其它不符合状态行的关于服务器的信息。Entity headers,例如 Content-Length,适用于请求的 body。显然,如果请求中没有任何 body,则不会发送这样的头文件。
请求头:
blank line
最后一个请求头之后是一个空行,通知服务器以下不再有请求头,进入消息正文。
message body
消息正文(如果有)用于承载该请求或响应的有效内容主体。邮件正文为与有效载荷主体相同,除非已进行传输编码。
message-body = * OCTET
-
请求体: 请求中消息正文的存在由Content-Length或Transfer-Encoding标头字段表示。
请求的最后一部分是它的 body。不是所有的请求都有一个 - - - body:例如获取资源的请求,GET,HEAD,DELETE 和 OPTIONS,通常它们不需要 body。 有些请求将数据发送到服务器以便更新数据:常见的的情况是 POST 请求(包含 HTML 表单数据)。
Body 大致可分为两类:
- Single-resource bodies,由一个单文件组成。该类型 body 由两个 header 定义: Content-Type 和 Content-Length.
- Multiple-resource bodies,由多部分 body 组成,每一部分包含不同的信息位。通常是和 HTML Forms 连系在一起。
-
响应体: 响应中消息体的存在取决于它所响应的请求方法和响应状态代码。
响应的最后一部分是 body。不是所有的响应都有 body:具有状态码,如 1xx(信息性), 204(无内容)或 304(未修改) 的响应,均不包含消息正文。所有其他响应的确包含消息正文,尽管该正文的长度可能为零。
Body 大致可分为三类:
- Single-resource bodies,由已知长度的单个文件组成。该类型 body 由两个 header 定义:Content-Type 和 Content-Length。
- Single-resource bodies,由未知长度的单个文件组成,通过将 Transfer-Encoding 设置为 chunked 来使用 chunks 编码。
- Multiple-resource bodies,由多部分 body 组成,每部分包含不同的信息段。但这是比较少见的。
body就是传输的内容。因为Http是应用层协议,所以除了传输数据,还需要定义传输的数据格式。这些格式定义在header中指定。Content-Length请求或者响应的body长度,必须要带上这个字段,以便对方可以方便的分辨出报文的边界,也就是Body数据何时结束。如果Body太大,需要边计算边传输,不到最后计算结束是无法知道整个Body大小的,这个时候可以使用chunk传输,通过Transfer-Encoding指定,这两个header key是互斥的,只能指定一个。通常body的数据比较多时,都使用chunk来传输,效率比较高。没有了length,通过一个长度为 0的chunk,对应的分块数据没有内容,来表示body内容结束。
消息格式总结
HTTP 请求和响应具有相似的结构,由以下部分组成︰
- 一行起始行用于描述要执行的请求,或者是对应的状态,成功或失败。这个起始行总是单行的。
- 一个可选的HTTP头集合指明请求或描述消息正文。
- 一个空行指示所有关于请求的元数据已经发送完毕。
- 一个可选的包含请求相关数据的正文 (比如HTML表单内容), 或者响应相关的文档。
HTTP消息编码
传输编码
传输编码在 HTTP 的报文头中,使用 Transfer-Encoding 首部进行标记,它就是指明当前使用的传输编码。
通常情况下,HTTP的响应消息体 message body 是作为整包发送到客户端的,用头部字段『Content-Length』 来表示消息体的长度, 这个长度对客户端非常重要,因为对于持久连接TCP并不会在请求完立马结束,而是可以发送多次请求/响应,客户端需要知道哪个位置才是响应消息的结束,以及后续响应的开始,因此Content-Length显得尤为重要,服务端必须精确地告诉客户端 message body 的长度是多少, 如果Content-Length 比实际返回的长度短,那么就会造成内容截断,如果比实体内容长,客户端就一直处于pendding状态,直到所有的 message body 都返回了,请求才结束。
Web2.0的出现使得网页变得丰富多彩,内容也比早期的网页复杂很多,这样就会遇到一个问题,对于一个复杂的页面来说,如果是等到消息体完全创建好之后再计算出Content-Length返回给客户端的话,在客户端那边会有一个漫长的等待过程,而对于用户来说,一个页面的所能容忍的等待时间不超过3秒,因此如何让响应内容尽可能早的让用户看到是HTTP协议要考虑的问题。
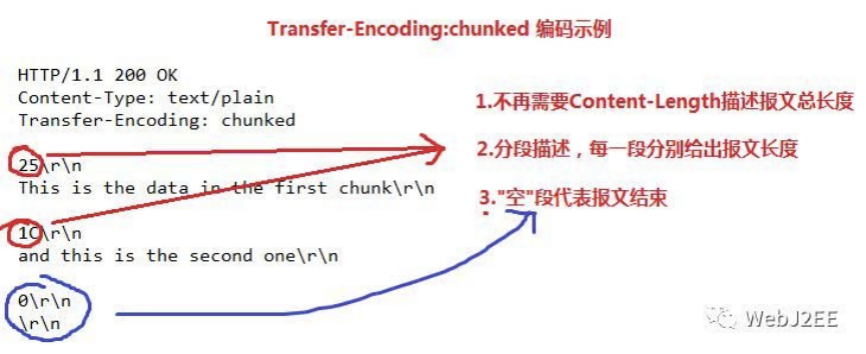
分块传输编码(Transfer-Encoding)就是这样一种解决方案:它把数据分解成一系列数据块,并以多个块发送给客户端,服务器发送数据时不再需要预先告诉客户端发送内容的总大小,只需在响应头里面添加Transfer-Encoding: chunked,以此来告诉浏览器我使用的是分块传输编码,这样就不需要 Content-Length 了,这就是分块传输编码的作用。
那么什么时候会用到分块传输编码呢?Stack Overflow 上有一句非常精辟的总结:
Transfer-Encoding: chunked is needed when the total content length is unknown before the first bytes are sent.
分块传输编码chunked
分块传输编码(Chunked transfer encoding)是超文本传输协议(HTTP)中的一种数据传输机制,用于界定报文从哪开始、到哪结束用的。允许服务端在不预先给出报文长度的情况下,分块将输出发送给客户端。 Transfer-Encoding 在最新的 HTTP/1.1 协议里,就只有 chunked 这个参数,标识当前为分块编码传输。 通常,HTTP 应答消息中发送的数据是整个发送的,Content-Length 消息头字段表示数据的长度。数据的长度很重要,因为客户端需要知道哪里是应答消息的结束,以及后续应答消息的开始。然而,使用分块传输编码,数据分解成一系列数据块,并以一个或多个块发送,这样服务器可以发送数据而不需要预先知道发送内容的总大小。
- 注1:服务端开启压缩后,通常会采用分块传输方式。
- 注2:Content-Length与Transfer-Encoding不能同时出现在响应中。
分块传输的优点
- HTTP 分块传输编码允许服务器为动态生成的内容维持 HTTP 持久链接。通常,持久链接需要服务器在开始发送消息体前发送 Content-Length 消息头字段,但是对于动态生成的内容来说,在内容创建完之前是不可知的。
- 分块传输编码允许服务器在最后发送消息头字段。对于那些头字段值在内容被生成之前无法知道的情形非常重要,例如消息的内容要使用散列进行签名,散列的结果通过HTTP消息头字段进行传输。没有分块传输编码时,服务器必须缓冲内容直到完成后计算头字段的值并在发送内容前发送这些头字段的值。
- HTTP 服务器有时使用压缩 (gzip)以缩短传输花费的时间。分块传输编码可以用来分隔压缩对象的多个部分。在这种情况下,块不是分别压缩的,而是整个负载进行压缩,压缩的输出使用本文描述的方案进行分块传输。在压缩的情形中,分块编码有利于一边进行压缩一边发送数据,而不是先完成压缩过程以得知压缩后数据的大小。
分块传输的格式
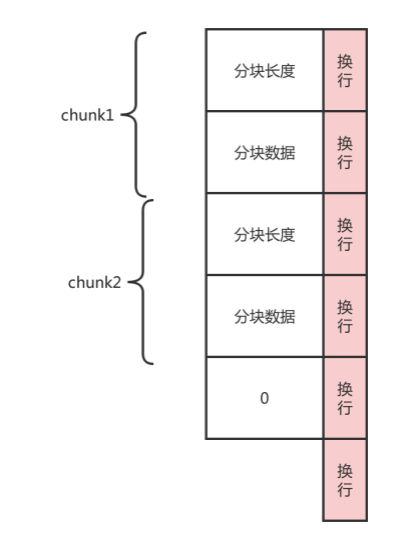
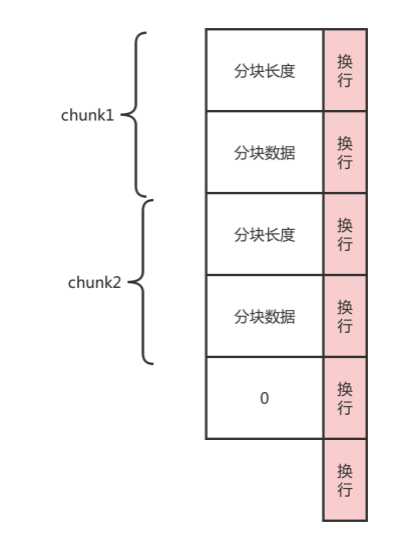
在消息头中指定Transfer-Encoding: chunked 就表示整个response将使用分块传输编码来传输内容,一个完整的消息体由n个块组成,并以最后一个大小为0的块为结束。
- 每个分块包含一个 16 进制的数据长度值和真实数据。
- 数据长度值独占一行,和真实数据通过 CRLF分割。
- 数据长度值,不计算真实数据末尾的 CRLF,只计算当前传输块的数据长度。
- 最后通过一个数据长度值为 0 的分块,来标记当前内容实体传输结束。
chunked的拖挂
当我们使用 chunked 进行分块编码传输的时候,传输结束之后,还有机会在分块报文的末尾,再追加一段数据,此数据称为拖挂(Trailer)。
拖挂的数据,可以是服务端在末尾需要传递的数据,客户端其实是可以忽略并丢弃拖挂的内容的,这就需要双方协商好传输的内容了。
在拖挂中可以包含附带的首部字段,除了 Transfer-Encoding、Trailer 以及 Content-Length 首部之外,其他 HTTP 首部都可以作为拖挂发送。
一般我们会使用拖挂来传递一些在响应报文开始的时候,无法确定的某些值,例如:Content-MD5 首部就是一个常见的在拖挂中追加发送的首部。和长度一样,对于需要分块编码传输的内容实体,在开始响应的时候,我们也很难算出它的 MD5 值。
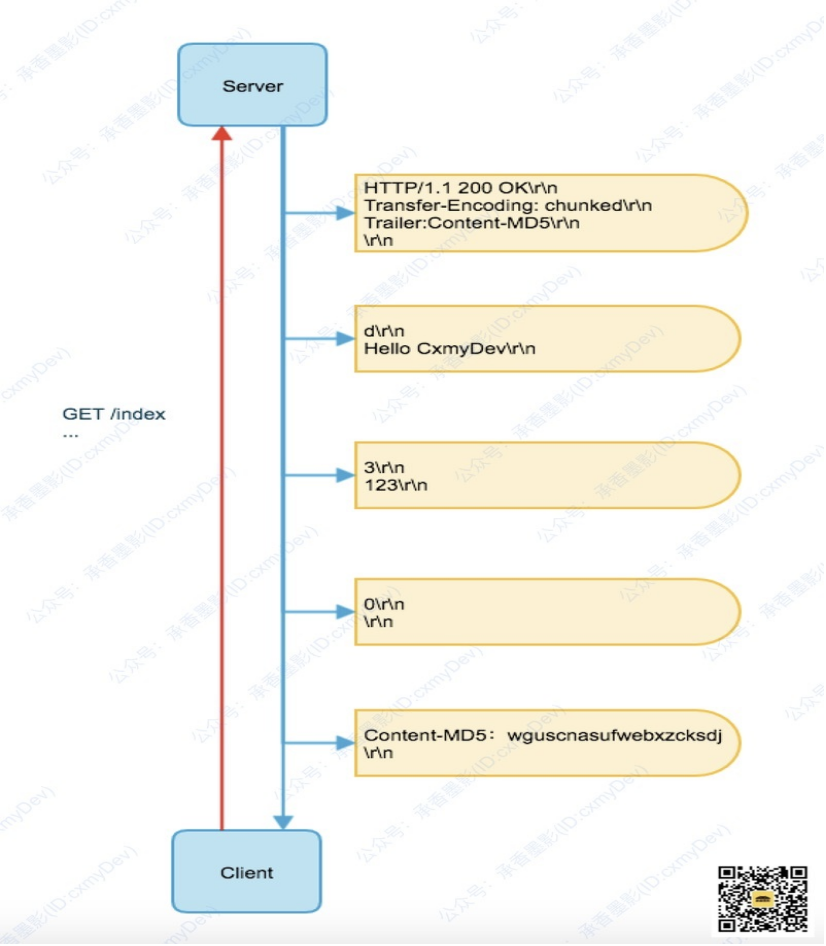
注意:这里在头部增加了 Trailder,用以指定末尾还会传递一个 Content-MD5 的拖挂首部,如果有多个拖挂的数据,可以使用逗号进行分割。
压缩编码
在http协议中,可以对内容(也就是body部分)进行编码, 可以采用gzip这样的编码,从而达到减小响应尺寸、节省带宽、提高速度的目的。
在http协议中,客户端与服务端之间通过Accept-Encoding与Content-Encoding合作完成。
-
Accept-Encoding:请求头部,用于告知服务器,浏览器支持的压缩方式,供服务器选择;
例:Accept-Encoding:gzip, br
-
Content-Encoding:响应头部,用于告知浏览器,传输数据的压缩方式,以便浏览器解压;
-
例:Content-Encoding:gzip
以下定义的编码可用于压缩信息。
- Compress Coding 表明实体采用Unix的文件压缩程序。
- Deflate Coding 表明实体是用zlib的格式压缩的。
- Gzip Coding 表明实体采用GNU zip编码。
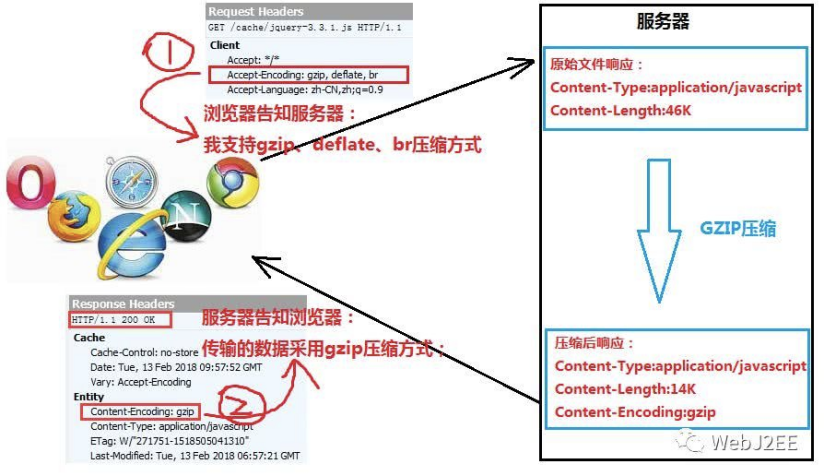
压缩的过程
- 浏览器发送Http request 给Web服务器, request 中有
Accept-Encoding: gzip, br。 (告诉服务器,浏览器支持gzip,br压缩) - Web服务器接到request后, 生成原始的Response, 其中有原始的
Content-Type和Content-Length。 - Web服务器通过
Gzip,来对Response进行编码, 编码后header中有Content-Type和Content-Length(压缩后的大小),并且增加了Content-Encoding:gzip. 然后把Response发送给浏览器。 - 浏览器接到Response后,根据
Content-Encoding:gzip来对Response 进行解码。 获取到原始response后, 然后显示出网页。
gzip,compress, 以及deflate编码都是无损压缩算法,用于减少传输报文的大小,不会导致信息损失。 其中gzip通常效率最高,使用最为广泛。
TE
请求中的TE标头字段指示客户端除了愿意分块传输之外还愿意接受哪些传输编码,以及客户端是否愿意接受分块传输编码中的Trailer字段。TE字段值由逗号分隔的传输编码名称列表组成,每个传输编码名称都允许使用可选参数和或关键字“ trailers”。客户端不得在TE中发送分块的传输编码名称;HTTP / 1.1收件人始终可以接受分块。关键字“ trailers”的存在表示客户端愿意代表自己和任何下游客户端接受分块传输编码中的Tralier字段。
当可接受多种传输编码时,客户端可以使用不区分大小写的“ q”参数按优先级对编码进行排序。等级值是介于0到1之间的实数,其中0.001是最不优选的,而1是最优选的;值为0表示“不可接受”。
trailer
当消息包括用分块传输编码的消息主体,并且发件人希望在消息末尾以Tralier字段的形式发送数据时,发件人应在消息主体之前生成尾部标头字段以指示哪些字段将出现在拖挂中。这允许接收者在开始处理正文之前准备接收该数据,这在流式传输消息且接收者希望即时确认完整性检查时很有用。
编码总结
- 传输编码使用
Transfer-Encoding首部进行标记,在最新的HTTP/1.1协议里,它只有chunked这一个取值,表示分块编码。 - 传输编码主要是为了解决持久连接里将数据分块传输之后,判定内容实体传输结束。
- 分块的格式:数据长度(16进制)+ 分块数据。
- 如果还有额外的数据,可以在结束之后,使用
Trailer进行拖挂传输额外的数据。 - 传输编码通常会配合内容编码一起使用。我们会先使用内容编码,将内容实体进行压缩,然后再通过分块传输编码发送出去。客户端接收到分块的数据,再将数据进行重新整合,还原成最初的数据。
- 压缩编码类型,
content-encoding值:gzip,br,deflate,其中gzip最常用。
扩展:
- HTTP隧道技术就是把所有要传送的数据全部封装到HTTP协议里进行传送,HTTP隧道技术几乎支持了所有的上网方式,如:拨号上网、ADSL、Cable Modem、NAT透明代理、HTTP的GET型和CONNECT型代理、SOCKS4代理、SOCKS5代理等。
- OCTET:八位字节,同byte,1OCTET=8bit。
