学习链接:mooc.study.163.com/smartSpec/d…
一、定义
- 机器学习: 计算机从数据中学习出规律及模式,以应用在新数据上做预测的任务。
- 作为一套数据驱动的方法,在互联网、生物、医疗、金融、能源、交通等领域有广泛的应用。
二、机器学习分类
- 监督学习: 特征+标签
- 分类:离散个结果中做选择
- 回归:输出连续值结果
- 无监督学习:特征
- 聚类:抱团学习
- 关联规则
- 强化学习:从环境到行为映射的学习
三、机器学习概念
- 样本/示例/样例、特征/属性、训练集、测试集
四、机器学习工业应用方向
- 自然语言处理、计算机视觉、电商推荐与预估
五、机器学习基本流程与工作环节
- 数据驱动方法: 数据 + 机器学习算法 = 预测模型
- 机器学习应用阶段
- (1)、数据预处理: 数据采样、数据切分、特征抽取、特征选择、降维
- (2)、模型学习: 超参选择、交叉验证、结果评估、模型选择、模型训练
- (3)、模型评估: 分类、回归、排序评估标准
- (4)、模型上线
六、机器学习中的评估指标
- 机器学习的目标:给定的训练数据上,试图给出规律的模型,在未知样本下,会有很好的效果。泛化能力强,能很好地适用于没见过的样本,比如错误率低、精度高。
- 评估常用方法:(测试机[用于评估]应该与训练集[用于模型学习]'互斥')
- 留出法(hold-out)
- 保持数据分布一致性(例如:分层采样)
- 多次重复划分(例如:100次随机划分)
- 测试集不能太大、不能太小(例如:1/5 ~ 1/3)
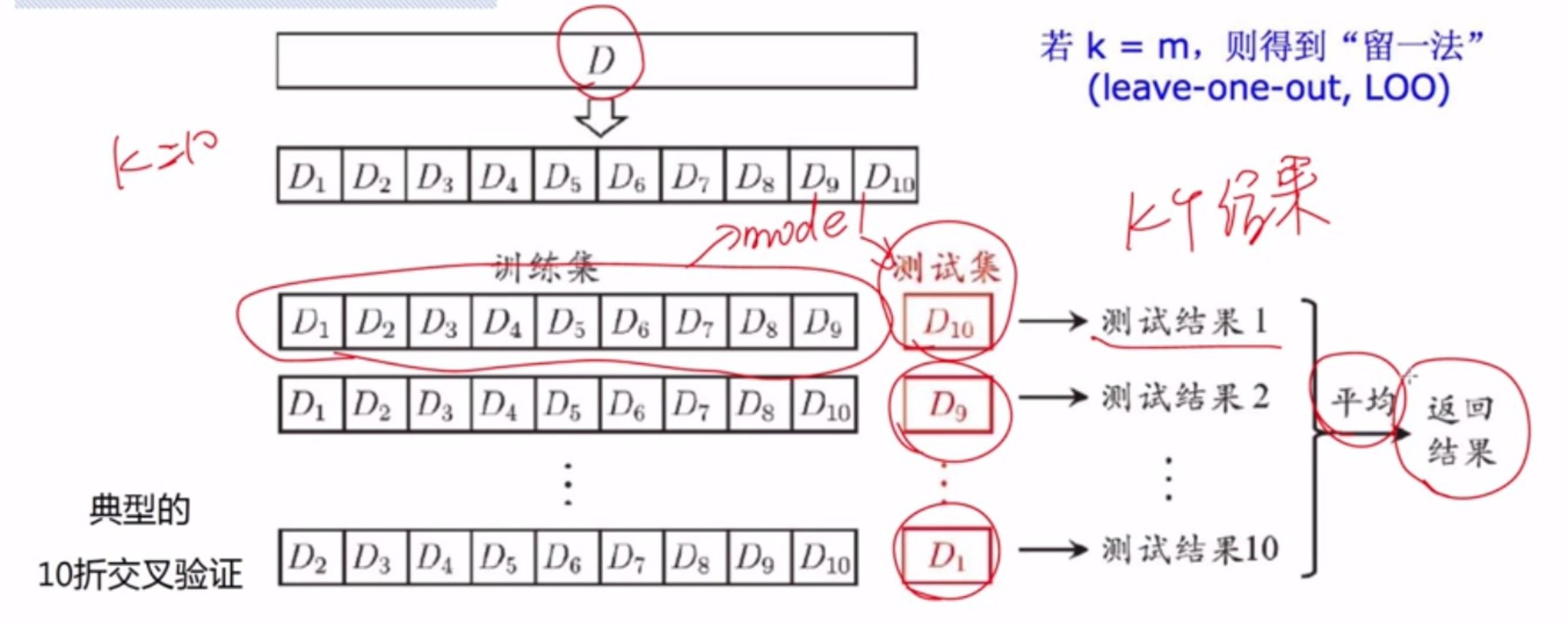
- k折交叉验证法(cross validation)
- 别称:"有放回采样"、"可重复采样"
- 训练集与原样本同规模
- 数据分布有说改变
- “包外估计”
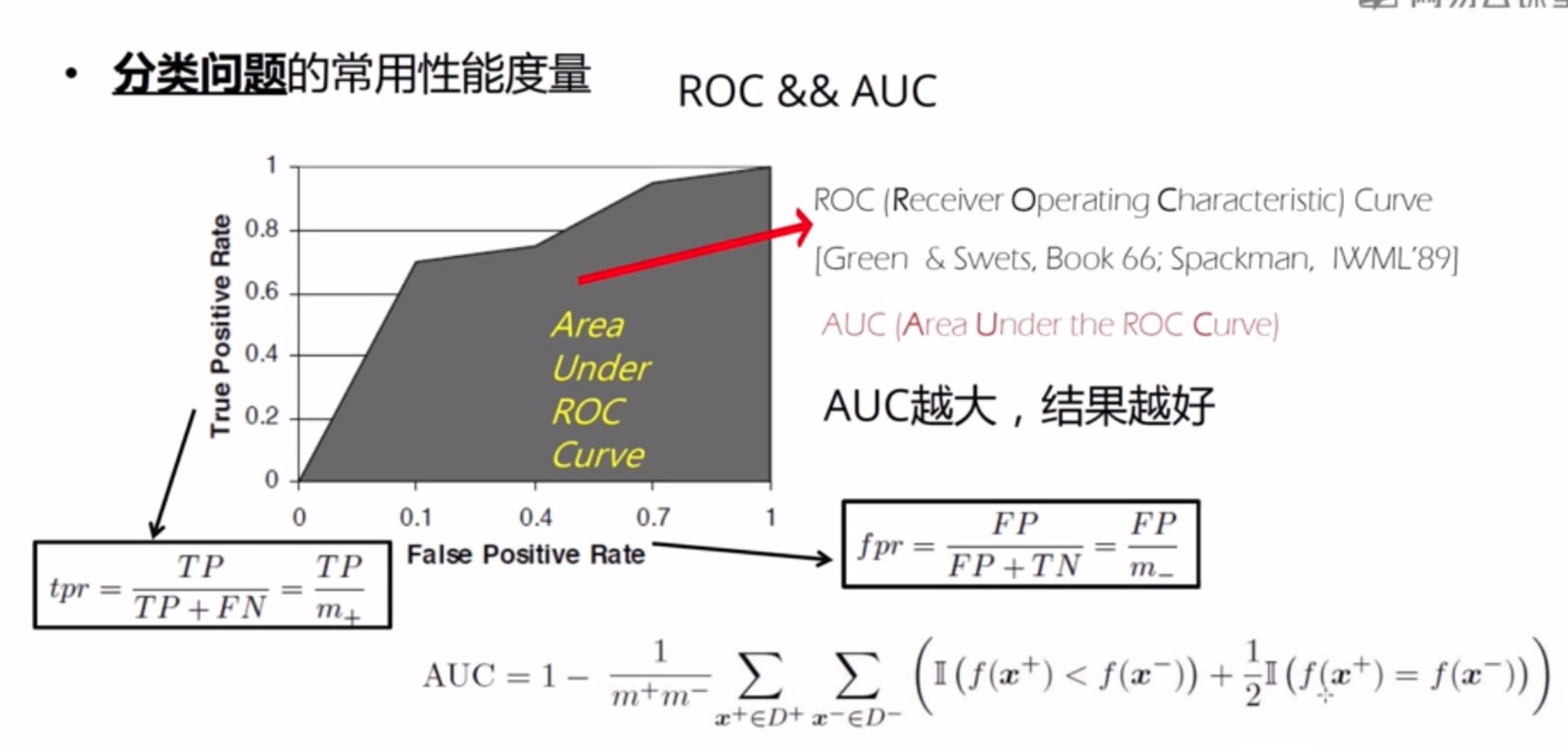
3. 性能度量: 是衡量模型泛化能力的数值评价标准,反映了当前问题(任务需求),使用不同的性能度量可能会导致不同的评判效果。
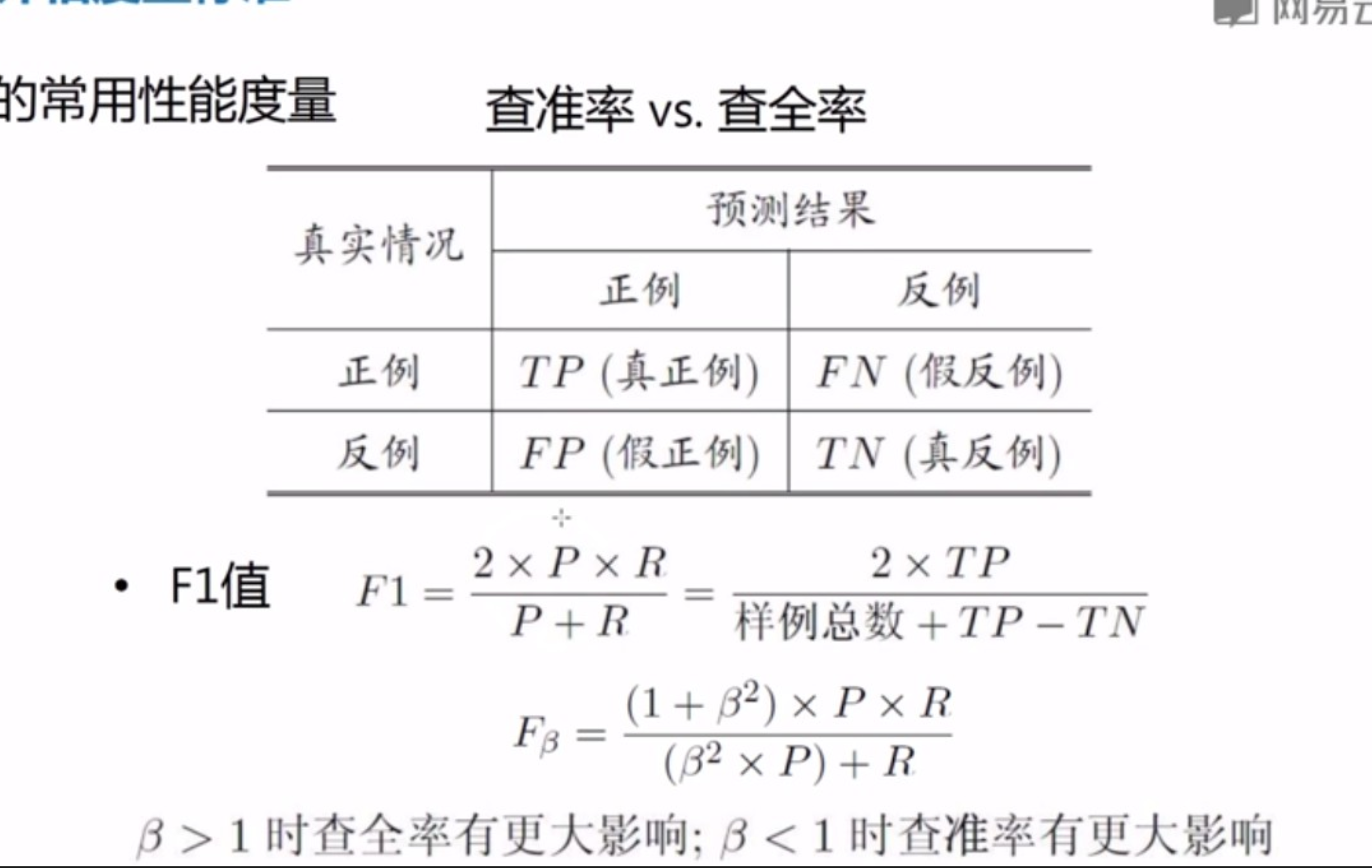
- 分类问题常用性能度量
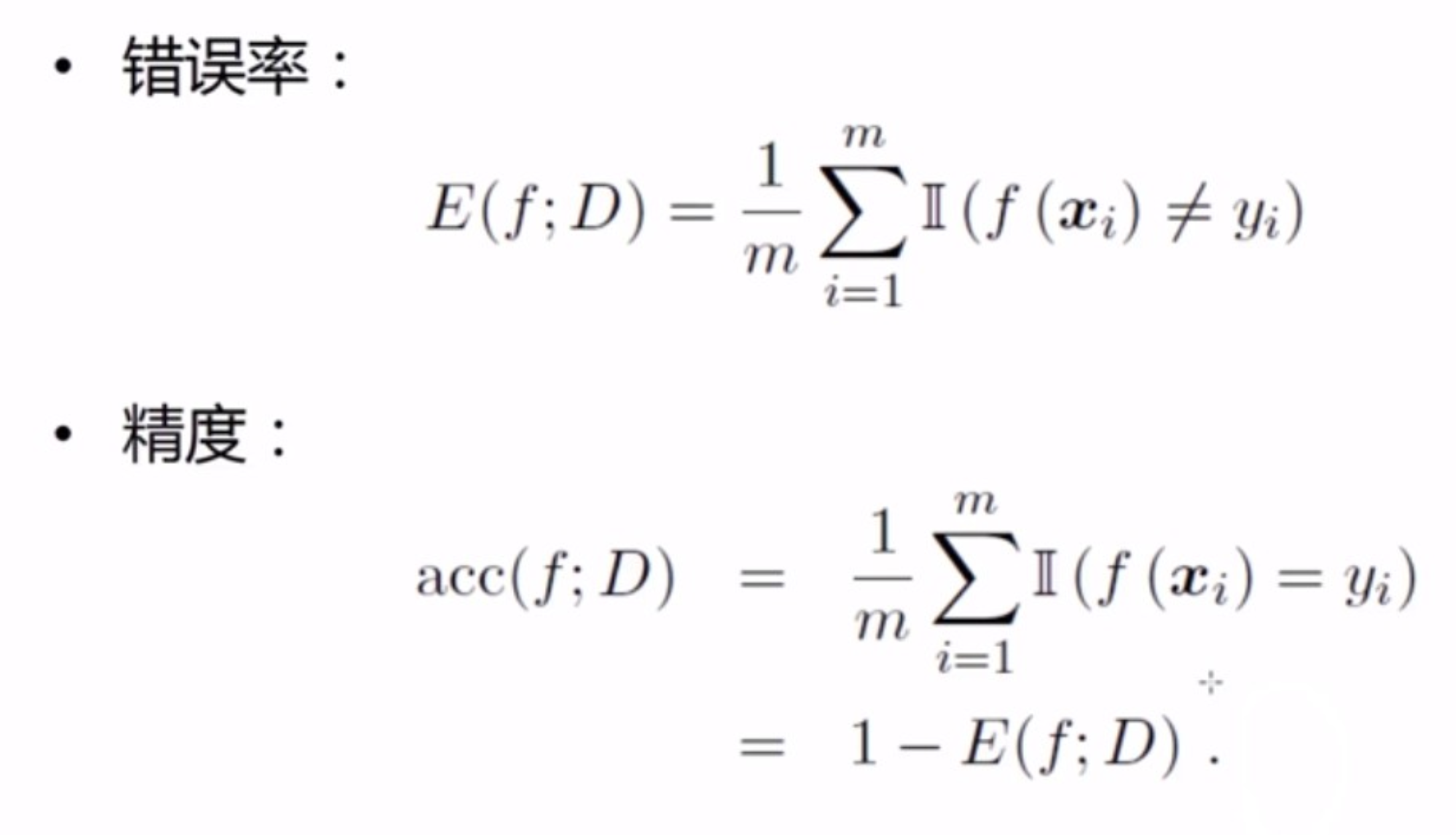


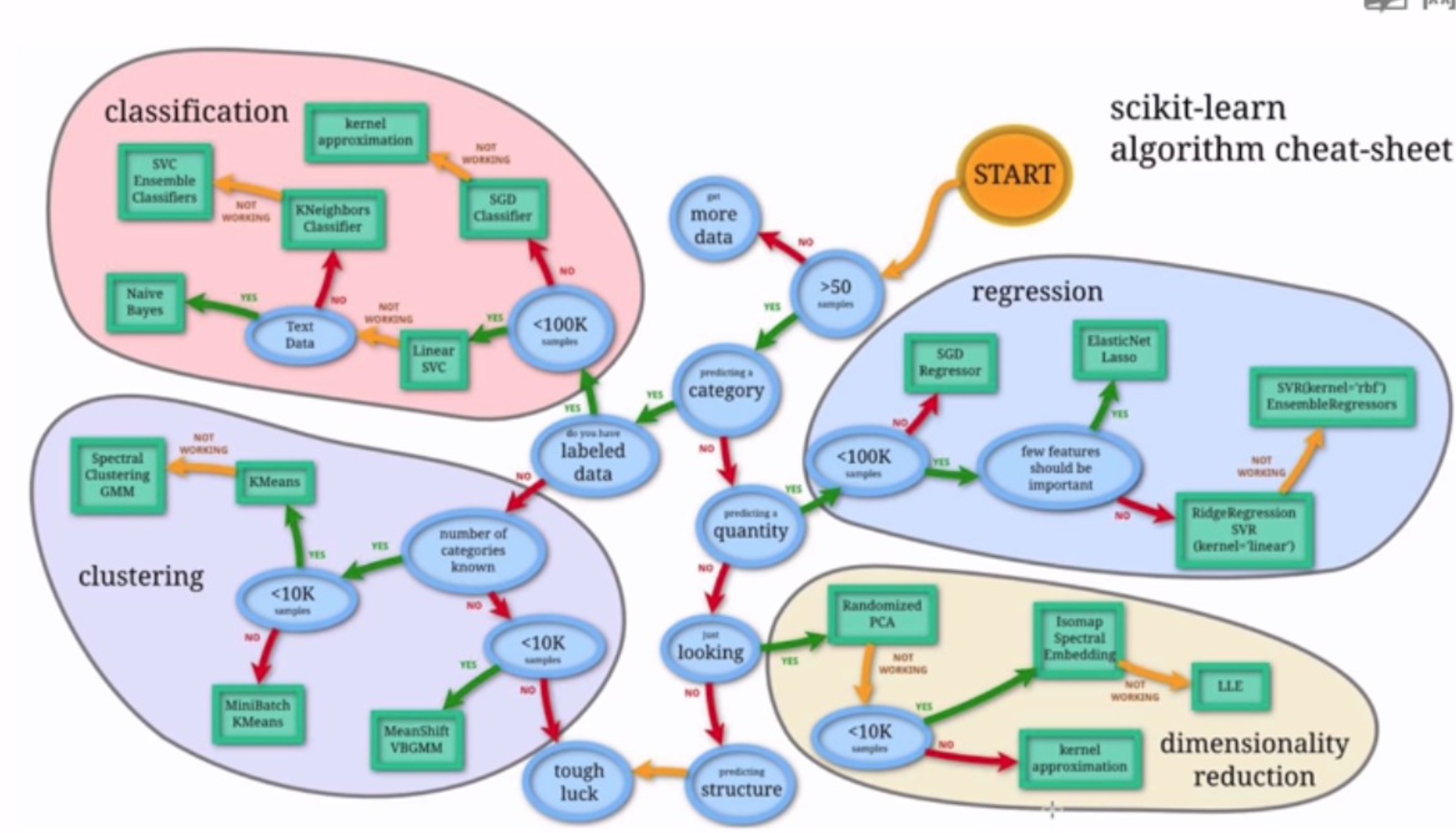
七、机器学习算法一览
- 机器学习地图

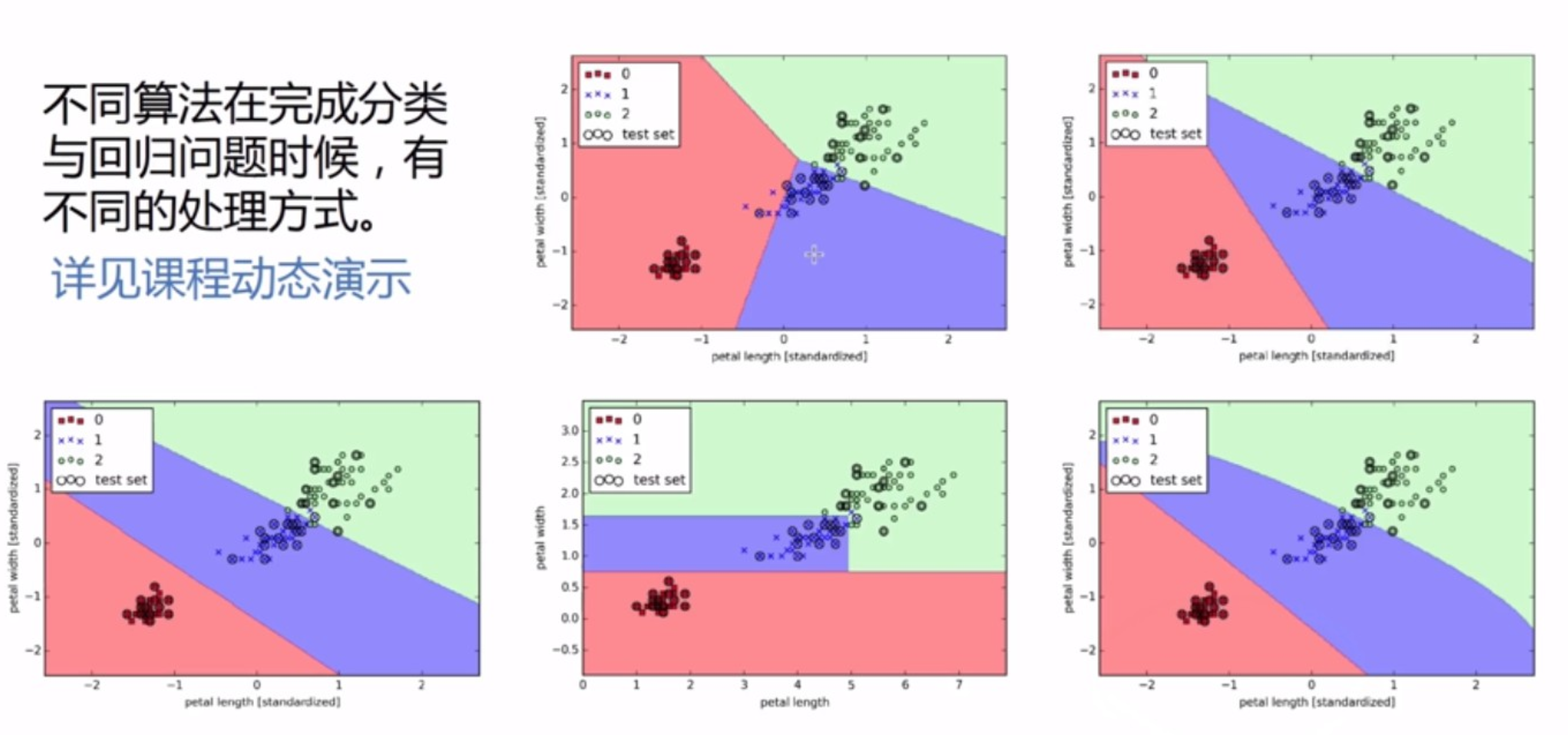
- 不同算法在完成分类与回归问题时候,有不同的处理方式
- 机器学习算法
- 监督学习
~ 分类:K最近邻、逻辑回归、朴素贝叶斯、支持向量机、树模型....
~ 回归:线性回归、多项式回归、岭回归、树模型回归...
- 无监督学习
~ 聚类: K-means、层次聚类、密度聚类、GMM...
~ 关联规则:Fpgrowth
- 机器学习算法可视化理解
- 分类问题
~ 不同的算法在尝试生成不同的决策边界,从而完成分类
~ 回归类问题有不同拟合方式
八、学习机器学习方法