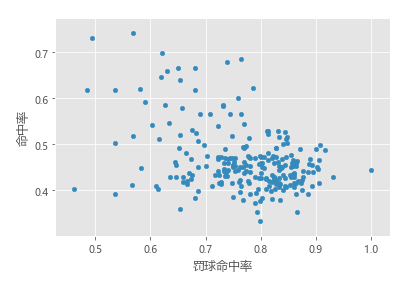
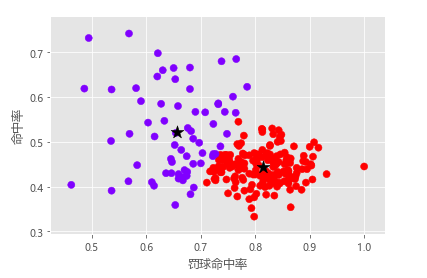
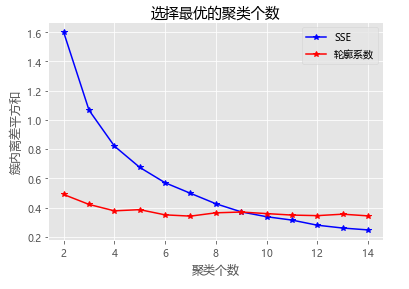
# K-Means聚类算法defkMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))#create mat to assign data points #to a centroid, also holds SE of each point
centroids = createCent(dataSet, k)
clusterChanged = Truewhile clusterChanged:
clusterChanged = Falsefor i in range(m):#for each data point assign it to the closest centroid
minDist = inf; minIndex = -1for j in range(k):
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex: clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
print(centroids)
for cent in range(k):#recalculate centroids
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]#get all the point in this cluster
centroids[cent,:] = mean(ptsInClust, axis=0) #assign centroid to mean return centroids, clusterAssment
# 二分K均值聚类算法(bisecting K-means)defbiKmeans(dataSet, k, distMeas=distEclud):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
centroid0 = mean(dataSet, axis=0).tolist()[0]
centList =[centroid0] # create a list with one centroidfor j in range(m): # calc initial Error
clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2while (len(centList) < k):
lowestSSE = inf
for i in range(len(centList)):
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:]#get the data points currently in cluster i
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas)
sseSplit = sum(splitClustAss[:,1])#compare the SSE to the currrent minimum
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1])
print("sseSplit, and notSplit: ",sseSplit,sseNotSplit)
if (sseSplit + sseNotSplit) < lowestSSE:
bestCentToSplit = i
bestNewCents = centroidMat
bestClustAss = splitClustAss.copy()
lowestSSE = sseSplit + sseNotSplit
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #change 1 to 3,4, or whatever
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit
print('the bestCentToSplit is: ',bestCentToSplit)
print('the len of bestClustAss is: ', len(bestClustAss))
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0]#replace a centroid with two best centroids
centList.append(bestNewCents[1,:].tolist()[0])
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss#reassign new clusters, and SSEreturn mat(centList), clusterAssment
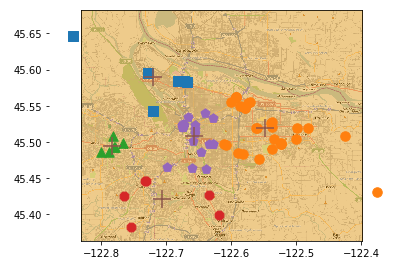
demo Yahoo map
import urllib
import json
defgeoGrab(stAddress, city):
apiStem = 'http://where.yahooapis.com/geocode?'#create a dict and constants for the goecoder
params = {}
params['flags'] = 'J'#JSON return type
params['appid'] = 'aaa0VN6k'
params['location'] = '%s %s' % (stAddress, city)
url_params = urllib.urlencode(params)
yahooApi = apiStem + url_params #print url_params
print(yahooApi)
c=urllib.urlopen(yahooApi)
return json.loads(c.read())
from time import sleep
defmassPlaceFind(fileName):
fw = open(r'E:\资料\Python学习资料(、重要、)\005python机器学习\机器学习实战源码\machinelearninginaction\Ch10\places.txt', 'w')
for line in open(fileName).readlines():
line = line.strip()
lineArr = line.split('\t')
retDict = geoGrab(lineArr[1], lineArr[2])
if retDict['ResultSet']['Error'] == 0:
lat = float(retDict['ResultSet']['Results'][0]['latitude'])
lng = float(retDict['ResultSet']['Results'][0]['longitude'])
print("%s\t%f\t%f" % (lineArr[0], lat, lng))
fw.write('%s\t%f\t%f\n' % (line, lat, lng))
else: print("error fetching")
sleep(1)
fw.close()
defdistSLC(vecA, vecB):#Spherical Law of Cosines
a = sin(vecA[0,1]*pi/180) * sin(vecB[0,1]*pi/180)
b = cos(vecA[0,1]*pi/180) * cos(vecB[0,1]*pi/180) * \
cos(pi * (vecB[0,0]-vecA[0,0]) /180)
return arccos(a + b)*6371.0#pi is imported with numpy