

第 4 章 排序算法(第二部分)
第 1 节 归并排序(Merge Sort)
这一节我们介绍归并排序。
- 归并排序是我们学习的第 1 个
级别的排序算法;
- 归并排序应用到的递归方法的设计和分而治之的思想是十分经典且重要的;
- 归并排序是一种稳定的排序方法,Java 语言中对象数组(非原始类型)的排序就是使用归并排序的升级版 TimSort 实现的。
归并排序的想法的来源
首先我们先介绍什么是归并。所谓归并,就是将两个或两个以上的有序序列合并成一个新的有序序列的过程。
说明:
- 这里的「序列」是指具有线性结构的序列,可以是数组,也可以是链表;
- 在归并的过程中,有序是归并得以有效进行的前提,这一点很重要。
我们先直观感受一下,两个有序的序列是怎样归并的。
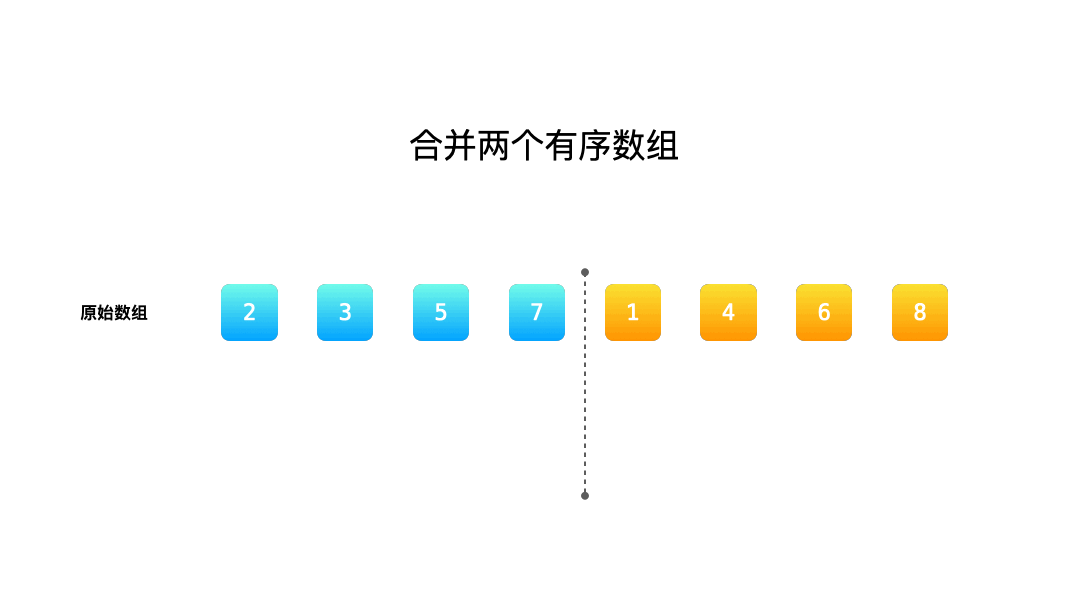
归并的过程相信大家现在脑子里也有了一个大致的想法,那就是:
- 首先将输入数组做一次拷贝;
- 然后每一次我们都比较拷贝数组最开始的那个元素,哪个元素小,我们就把赋值回放到归并以后的那个数组(原始输入数组)中;
- 直到拷贝数组中所有的元素都遍历完成(都赋值回去)。
可以看到在数组里实现的归并过程需要使用额外空间,所以归并排序是一个非原地排序的算法。
使用额外空间用于辅助数组的好处:如果一个元素在数组靠后的位置,它可以借助辅助数组一下子来到数组的前面,正好解决了插入排序的痛点,并且这一点也使得稳定性得以保证。
友情提示:归并排序还有原地实现的版本,思想也不难,但是实现比较复杂,感兴趣的朋友可以了解一下。
正是因为合并两个有序数组是相对容易的,而归并排序真正在做的事情就是不断合并两个有序的数组,直至我们得到最终整体上有序的数组。
归并排序的具体步骤
下面我们介绍,如何对一个数组进行归并排序。
我们以长度为 的数组为例。
- 先将数组一分为二;这个**「分」是逻辑上的分,不是将数组真正的切开**;
- 来到了第
层,现在要排序的元素只有
个,我们再一分为二;
- 来到了第
层,现在要排序的元素只有
- 来到了第
个,它一定是有序的,因此我们就可以使用归并的过程,把它们合并成一个有序数组;
- 然后回到了第
- 接下来,我们回到第
- 等到左边右边都处理完了,回到上一层;
- 最后回到第
这个过程可能看起来比选择排序和插入排序的过程要复杂,但是在归并的过程中,可以使得原先位于数组后面的元素在归并的时候,一下子来到数组的前面,这件事情是归并排序比插入排序和选择排序快的原因。
在写代码之前,我们先分析归并排序的时间复杂度与空间复杂度:
归并排序的复杂度分析
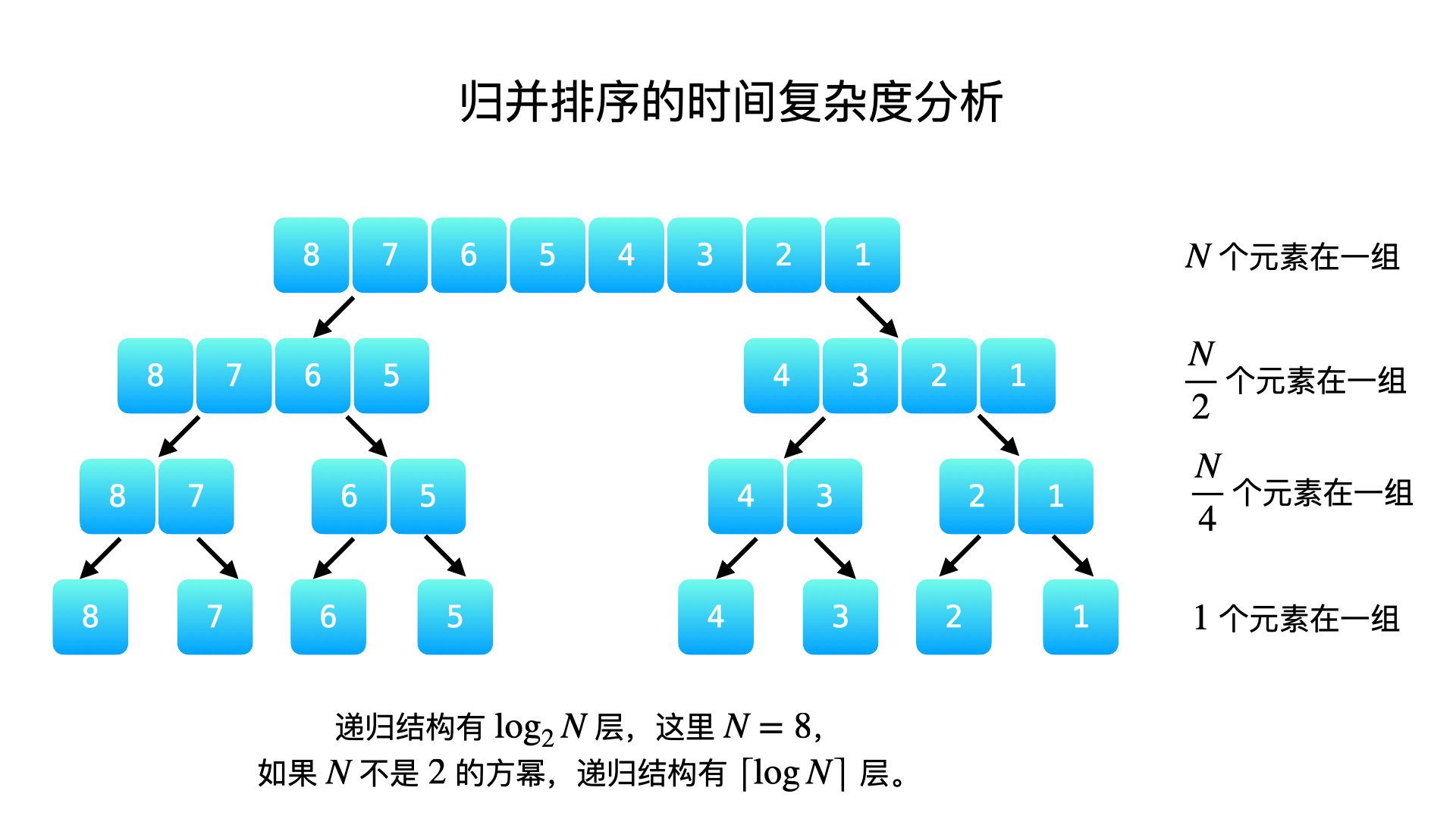
-
从整体上考虑,在每一层,都执行了数组长度这么多次的赋值和比较,每一层参与比较的数组元素的个数和数组的长度是一致的;
-
分析归并排序的时间复杂度的关键是:需要知道完成一次归并操作这样递归处理的树形结构,有多少层。即这样一分为二的处理,多少次以后使得分完以后的元素只剩下一个。
事实上,这件事情等价于求解序列
的长度。我们可以从这个序列的末尾向开头看,从 开始,每次乘以
,执行多少次乘以
倍的操作,可以到
?假设设每一次乘以
的次数为
,则
,依据对数的定义得到
。
在这里,为了方便说明,我们选取了一个 的整数幂长度的数组进行说明。如果数组的长度是
或者
等非
的整数幂长度,递归结构的层数就是以
为底
的对数向上取整。
综上所述,每一层处理 个元素,一共有
层(符号
和
表示向上取整),因此归并排序的时间复杂度是
。
空间复杂度:
归并需要 这么多的辅助空间,递归调用的深度是
,因此空间复杂度是
(计算复杂度的时候,两个加法项,保留最大的那个项)。
友情提示:对于算法的时间复杂度和空间复杂度,作为工程师只需要知道一个大概的、感性的结果就好了。由于我们不是写学术著作,也不是写科研论文,对于一些非常细节的地方,我们并没有花过多的篇幅去介绍它。对于「归并排序」时间复杂度的详细推导感兴趣的朋友,可以参考一些经典的算法教程进行学习。
归并排序的代码编写
下面我们来看一下归并排序的代码实现,从之前的动画演示中,我们看到,归并排序其实是一次又一次,对数组的不同子区间递归进行排序的过程。
因此我们需要设计一个私有函数,表示我们针对这个数组的子区间进行排序。为此我们将这个私有函数定义为 mergeSort(int[] arr, int left, int right),参数有:
- 输入数组;
- 两个变量
left和right,表示针对这个数组的子区间[left, right],这个范围是左闭右闭的,进行一次排序。
下面我们来看一下这个私有函数应该怎么写。
- 既然是一个递归函数,首先要写递归终止条件(这一点非常重要),否则这个函数就会无休止的进行下去;
- 这个递归终止条件在之前的动画演示中,相信大家都已经看到了,在这个数组中只剩下一个元素的时候,我们就认为这个数组已经有序,此时不再继续划分,这个道理其实也很自然,就
if (left == right) {
return;
}
如果区间的长度严格大于 或者说至少有
个的时候,需要这个区间从中间将它一分为二。
int mid = (left + right) / 2;
我们先写出代码的框架。写归并排序的代码的时候,由于用到了递归,因此我们要定义清楚递归函数的语意。
Java 代码:
public class MergeSort {
public void sort(int[] arr) {
int len = arr.length;
mergeSort(arr, 0, len - 1);
}
/**
* 对数组 nums 在区间 [left..right] 内进行归并排序
*
* @param nums
* @param left 左边界,可以取到
* @param right 右边界,可以取到
*/
private void mergeSort(int[] nums, int left, int right) {
if (left == right) {
return;
}
int mid = left + (right - left) / 2;
mergeSort(nums, left, mid);
mergeSort(nums, mid + 1, right);
mergeOfTwoArray(nums, left, mid, right);
}
}
在这里我对 mid 的定义是第 1 部分的最后一个元素的下标,然后针对
- 数组
[left.. mid ]递归调用一次; - 数组
[mid + 1..right]递归调用一次。
下面就是归并的过程,我们将归并的过程定义为:对数组 [left..right] 进行归并,并且上面递归函数返回以后,mid 是两个有序子区间中第 1 个子区间的末尾,我把这个信息传递到这个方法中。
归并过程的代码:
- 实现这个函数,我们就得需要一个和子区间长度相等的辅助数组,为此,我们需要新建一个数组,由于将排序的结果需要直接体现在原始数组上,因此我们采取的策略是先把这个子区间里所有的元素复制出来,通过比较以后,再赋值回去;
- 此时子区间的长度是
right – left + 1; - 和之前的演示动画一样,我们用
i和j分别表示当前子区间第 1 个部分的第 1 个元素的索引和第 2 个部分的第 1 个元素的索引;
用下标 k 表示马上要赋值回去的那个下标的位置:
总共要赋值数组长度这么多次,我们每次从 temp 数组中比较,赋值回 arr 数组中,每次比较的时候,都看 i 和 j 指向的元素哪一个更小;
因此,首先是 temp[i] <= temp[j],第 1 个部分先被选出,因此
arr[left + i] = temp[i];
i++;
注意:这里需要写 = ,意味着 i 和 j 指向的元素的值相等的时候,我优先选取 i 指向的那个元素,这样就能能保证归并排序是一个稳定排序。否则的话,相等的元素,在排序之后,后面的就元素就会跑到前面,就破坏了稳定性。
这里其实代码还没有写完,对于数组而言,数组下标是否越界这件事情很重要。所以在这两行代码之前,应该先判断,i 和 j 各自扫描完了的情况,那么就是:
-
如果
i来到了第 2 部分的第 1 个元素;我们就一直把j指向的元素从前向后依次赋值; -
如果
j来到了第 2 部分的最后一个元素的后面,我们就一直把i指向的元素从前向后依次赋值。
这 4 种情况在一次赋值中会且只会执行一个分支,经过这样的一次循环,归并就完成了。
完整代码如下:
Java 代码:
public class Solution {
public int[] sortArray(int[] nums) {
int len = nums.length;
mergeSort(nums, 0, len - 1);
return nums;
}
/**
* 对数组 nums 的子区间 [left..right] 进行归并排序
*
* @param nums
* @param left
* @param right
*/
private void mergeSort(int[] nums, int left, int right) {
if (left == right) {
return;
}
int mid = left + (right - left) / 2;
mergeSort(nums, left, mid);
mergeSort(nums, mid + 1, right);
mergeOfTwoSortedArray(nums, left, mid, right);
}
/**
* 合并两个有序数组:先把值复制到临时数组,再合并回去
*
* @param nums
* @param left
* @param mid [left, mid] 有序,[mid + 1, right] 有序
* @param right
*/
private void mergeOfTwoSortedArray(int[] nums, int left, int mid, int right) {
// 每做一次合并,都 new 数组用于归并,开销大
int len = right - left + 1;
int[] temp = new int[len];
for (int i = 0; i < len; i++) {
temp[i] = nums[left + i];
}
// i 和 j 分别指向前有序数组和后有序数组的起始位置
int i = 0;
int j = mid - left + 1;
for (int k = 0; k < len; k++) {
// 先写 i 和 j 越界的情况
if (i == mid + 1 - left) {
nums[left + k] = temp[j];
j++;
} else if (j == right + 1 - left) {
nums[left + k] = temp[i];
i++;
} else if (temp[i] <= temp[j]) {
// 注意:这里必须写成 <=,否则归并排序就成了非稳定的排序
nums[left + k] = temp[i];
i++;
} else {
nums[left + k] = temp[j];
j++;
}
}
}
}
到此为止,归并排序的代码就写完了。(复杂度分析前文已经叙述了,在这里就不赘述了。)
归并排序体现的算法思想:分而治之(Divide and Conquer)
归并排序使用的思想是一个非常经典且常用的算法思想:分而治之。
- 分解(Divide):将原问题划分为一些子问题,子问题的形式与原问题相同,只是规模更小;
- 解决(Conquer):递归地求解出子问题。如果子问题的规模足够小,则停止递归,直接求解;
- 合并(Combine):将子问题的解组合成原始问题的解。
古时候「曹冲称象」的故事,和现如今大数据 Map Reduce 的思想都是分而治之思想的应用。
友情提示:对于归并排序的执行流程,看完以上的介绍如果还不太清晰的朋友。我们的建议是:使用一个小规模的测试用例,算法是如何执行的,请一定在纸上,模拟出来。
下面我们介绍在程序中打印的方式,可视化程序的执行流程。理解递归函数的执行流程,由于递归方法是自己调用自己,因此,递归调用的参数和递归调用的深度是很重要的,我们在程序中需要特别关注。
Java 代码:
import java.util.Arrays;
public class Solution {
public int[] sortArray(int[] nums) {
int len = nums.length;
mergeSort(nums, 0, len - 1, 0);
return nums;
}
private void mergeSort(int[] nums, int left, int right, int depthForDebug) {
System.out.println(" ".repeat(depthForDebug) + "divide (" + left + ", " + right + ")");
if (left == right) {
return;
}
int mid = left + (right - left) / 2;
mergeSort(nums, left, mid, depthForDebug + 1);
mergeSort(nums, mid + 1, right, depthForDebug + 1);
System.out.println(" ".repeat(depthForDebug) + "conquer (" + left + ", " + right + ")");
mergeOfTwoSortedArray(nums, left, mid, right);
}
private void mergeOfTwoSortedArray(int[] nums, int left, int mid, int right) {
int len = right - left + 1;
int[] temp = new int[len];
for (int i = 0; i < len; i++) {
temp[i] = nums[left + i];
}
int i = 0;
int j = mid - left + 1;
for (int k = 0; k < len; k++) {
if (i == mid + 1 - left) {
nums[left + k] = temp[j];
j++;
} else if (j == right + 1 - left) {
nums[left + k] = temp[i];
i++;
} else if (temp[i] <= temp[j]) {
nums[left + k] = temp[i];
i++;
} else {
nums[left + k] = temp[j];
j++;
}
}
}
public static void main(String[] args) {
Solution solution = new Solution();
int[] nums = {8, 7, 6, 5, 4, 3, 2, 1};
int[] res = solution.sortArray(nums);
System.out.println(Arrays.toString(res));
}
}
打印输出:
divide (0, 7)
divide (0, 3)
divide (0, 1)
divide (0, 0)
divide (1, 1)
conquer (0, 1)
divide (2, 3)
divide (2, 2)
divide (3, 3)
conquer (2, 3)
conquer (0, 3)
divide (4, 7)
divide (4, 5)
divide (4, 4)
divide (5, 5)
conquer (4, 5)
divide (6, 7)
divide (6, 6)
divide (7, 7)
conquer (6, 7)
conquer (4, 7)
conquer (0, 7)
[1, 2, 3, 4, 5, 6, 7, 8]
理解递归函数
相比较于分治思想,我更想和大家讨论一下递归这个话题。这是我们第一次接触递归,这个在算法领域几处随处可见的,你说它是算法思想也好,你说它是编码技巧也好,在一开始总是那么不好理解。
-
递归是一种自上而下思考问题的方式;
-
递归是自己调用自己,但是参数的规模不一样,每一次的递归调用一定会朝着数据规模更小的方向发展,因此递归终止条件很重要;
-
递归函数的调用过程是:后调用的方法先执行,因此之前调用的函数的相关信息需要保存起来,保存这些信息的数据结构就是「栈」。「栈」这个数据结构我们放在以后介绍。
友情提示:递归函数的编写和理解需要有一定的练习,不必着急一下子弄懂这个概念。先模仿,通过调试去理解递归函数的调用过程,再尝试理解是我们推荐的做法。
编写递归函数,通常要遵守下面的编写模式:
- 先写递归终止条件;
- 再假定小规模的问题已经解决(是通过递归解决的);
- 最后处理小规模问题已经解决的情况下,与当前问题之间的逻辑联系。
递归函数方法调用的特点是这样的:后调用的先返回,这就有点像你在做一件事情,突然有个紧急的事情加个塞插进来了,原来你要做的事情就得先暂停一下,你得先把这个后进来的事情处理完,原来你要做的事情才能借着往下做。
在更底层函数返回以后,我们可以做点事情,归并排序归并的过程就是在递归函数返回以后再做的。
友情提示:对于算法思想,需要大家在不断的学习和应用(目前来说就是刷题)中慢慢体会,如果一开始理解稍显吃力没有关系,有些时候,只是我们不太熟悉而已。
练习
- 完成「力扣」第 88 题:合并两个有序数组
说明:写好以后,不要忘记看一下别人的代码是如何实现的。
- 完成「力扣」第 189 题:189. 旋转数组
说明:原地归并排序和「旋转数组」的思想相同,但原地归并排序代码编写较为复杂,并且也不高效,不建议掌握原地归并排序。
- (选学)「自底向上」的「归并排序」
比较「自底向上」的归并排序和「自顶向下」的归并排序思想上的不同,我们可以把边界条件的判断交给递归,但是递归由于要使用系统栈,牺牲一些了空间。
友情提示:从原地归并排序和「自底向上」的归并排序,我们可以看到,节约空间的写法一般来说会稍微复杂一点,不过有些时候我们没有必要追求性能的极致,并且我们也说过,时间和空间绝大多数情况下不能同时最优,更多时候我们应该让时间复杂度最优。
- 使用「分治思想」完成下面两道问题:
-
「力扣」第 153 题:寻找旋转排序数组中的最小值
-
「力扣」第 154 题:154. 寻找旋转排序数组中的最小值 II
- 查阅资料学习「递归」与「分治思想」,了解「汉诺塔」程序。
这就是这一节的内容,下一节我们将学习归并排序的优化,感谢大家。
