主键策略
一、插入操作
1. 进行测试
0. 测试类
@SpringBootTest
public class CRUDTest {
@Autowired
private UserMapper userMapper;
@Test
public void testInsert "Hello" );
user.setEmail("5556666@qq.com" );
user.setAge(18);
//返回值:受影响的行数
int result = userMapper.insert(user);
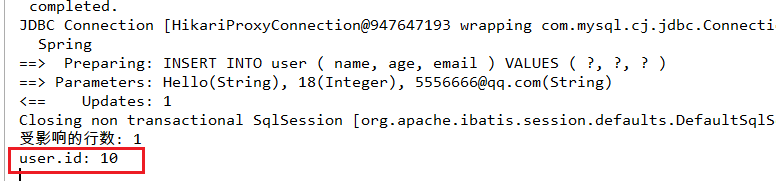
System.out.println("受影响的行数: " +result);
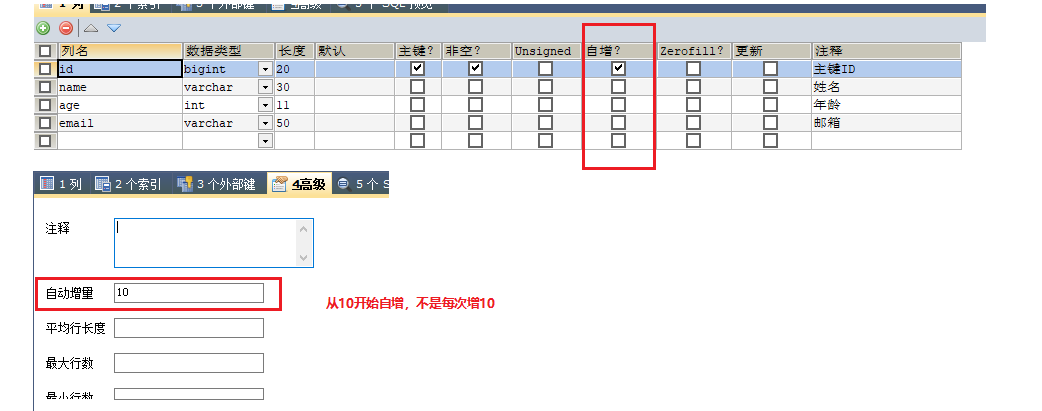
//我们建表时没有给ID设置自增:看一下插入时会不会自己生成,生成的话是几?
System.out.println("user.id: " + user.getId());
}
}
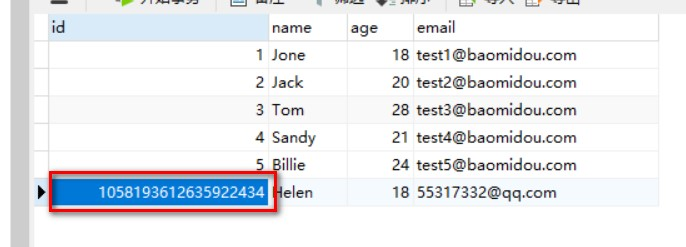
1. 看一下控制台打印的结果:
为我们自动生成一个Long类型的主键id。
2. 看一下数据库:
数据库插入id值默认为:全局唯一id
2. 主键策略
为什么会插入这样的一个id呢?
1. 我们在创建表时,特意没有利用数据库的主键策略。
我们没有用mysql的主键自增+1的策略。
2. Mybatis_plus帮我进行了主键的生成策略
我们没有在建表时选择主键生成策略,也没有在插入时传入id参数,那么主键哪来的呢?
那么一定是Mybatis_plus帮我进行了主键的生成策略。
3. Mybatis_plus为什么要帮我生成这样的一个主键呢?
这个id的生成规律和遵循原则:
4. 这个生成的主键:全局唯一id
和分布式有关系,在分布式的项目中,在互联网的项目中,数据量特别大,用户规模特别大,并发访问量
特别大。这是互联网分布式项目的一个主要特征。
在这种互联网分布式项目中,我们对数据库的设计也会有一些策略。
很典型的一个减轻数据库压力的这样一个策略就是分库分表策略。
二、数据库分库分表策略
背景
随着业务规模的不断扩大,需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量。
数据库的扩展方式(优化)主要包括:业务分库、主从复制,数据库分表。
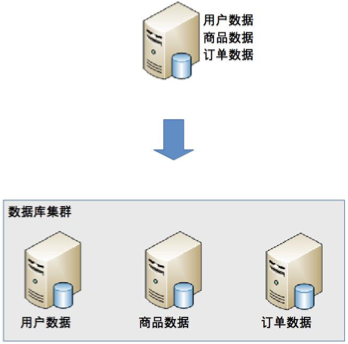
1、业务分库
1. 业务分库:
业务分库指的是按照业务模块将数据分散到不同的数据库服务器。
例如,一个简单的电商网站,包括用户、商品、订单三个业务模块,我们可以将用户数据、商品数据、
订单数据分开放到三台不同的数据库服务器上,而不是将所有数据都放在一台数据库服务器上。
这样的就变成了3个数据库同时承担压力,系统的吞吐量自然就提高了。
2. 新的问题:
虽然业务分库能够分散存储和访问压力,但同时也带来了新的问题,接下来我进行详细分析。
join 操作问题
业务分库后,原本在同一个数据库中的表分散到不同数据库中,导致无法使用 SQL 的 join 查询。
无法使用一条SQL语句关联在不同服务器中的两个表,要用Java代码。
事务问题
以前在同一个数据库的表,我想要做原子性操作的话,把它们放到一个事务中就可以了。
原本在同一个数据库中不同的表可以在同一个事务中修改,业务分库后,表分散到不同的数据库中,
无法通过事务统一修改。
虽然可以通过分布式的事务实现,但是显然没有数据库自带的事务方便,性能也不高,一致性也不强。
成本问题
业务分库同时也带来了成本的代价,本来 1 台服务器搞定的事情,现在要 3 台,如果考虑备份,
那就是 2 台变成了 6 台。
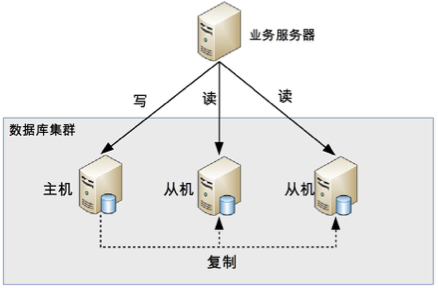
2、主从复制和读写分离
数据库分库一般涉及到主从复制:
读写分离的基本原理是将数据库读写操作分散到不同的节点上。读写分离的基本实现是:
数据库服务器搭建主从集群,一主一从、一主多从都可以。
数据库主机主要负责读写操作,从机只负责读操作。
业务服务器将写操作发给数据库主机,将读操作发给数据库从机。
这就要求主机和从机的数据要保持实时的一致性。
数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据。
业务服务器:不是数据库,运行微服务的服务器。
需要注意的是,这里用的是“主从集群”,而不是“主备集群”。
“从机”的“从”可以理解为“仆从”,仆从是要帮主人干活的,“从机”是需要提供读数据的功能的;
而“备机”一般被认为仅仅提供备份功能,不提供访问功能。
所以使用“主从”还是“主备”,是要看场景的,这两个词并不是完全等同。
3、数据库分表:重点
将不同业务数据分散存储到不同的数据库服务器,能够支撑百万甚至千万用户规模的业务,但如果业务继续发展,
同一业务的单表数据也会达到单台数据库服务器的处理瓶颈。
例如,淘宝的几亿用户数据,如果全部存放在一台数据库服务器的一张表中,肯定是无法满足性能要求的,
此时就需要对单表数据进行拆分。
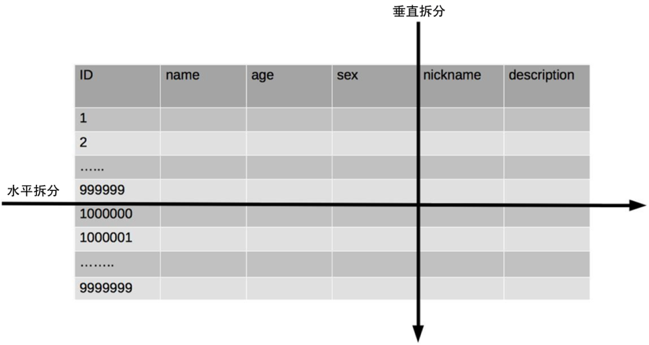
单表数据拆分有两种方式:垂直分表和水平分表。示意图如下:
单表进行切分后,是否要将切分后的多个表分散在不同的数据库服务器中,可以根据实际的切分效果来确定。
如果性能能够满足业务要求,是可以不拆分到多台数据库服务器的,毕竟我们在上面业务分库的内容看到业务
分库也会引入很多复杂性的问题。
分表能够有效地分散存储压力和带来性能提升,但和分库一样,也会引入各种复杂性:
1. 垂直分表:
垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。
例如,前面示意图中的 nickname 和 description 字段,假设我们是一个婚恋网站,用户在筛选其他
用户的时候,主要是用 age 和 sex 两个字段进行查询,而 nickname 和 description 两个字段主要
用于展示,一般不会在业务查询中用到。
description 本身又比较长,因此我们可以将这两个字段独立到另外一张表中,这样在查询 age 和 sex
时,就能带来一定的性能提升。
2. 水平分表:
水平分表适合表行数特别大的表,有的公司要求单表行数超过 5000 万就必须进行分表,这个数字可以作为
参考,但并不是绝对标准,关键还是要看表的访问性能。
对于一些比较复杂的表,可能超过 1000 万就要分表了;
而对于一些简单的表,即使存储数据超过 1 亿行,也可以不分表。
但不管怎样,当看到表的数据量达到千万级别时,作为架构师就要警觉起来,因为这很可能是架构的性能
瓶颈或者隐患。
考虑到分库带来的join 操作问题,事务问题,成本问题,如果一个数据库通过水平分表就能解决性能的
问题了,那么就不要分库。
如果水平分完表之后,一个数据库仍然满足不了性能要求,那么就要把新的表分到不同的数据库中。
3、id生成策略
水平分表相比垂直分表,会引入更多的复杂性,例如数据id:
几个解决策略:
1. 主键自增:
以最常见的用户 ID 为例,可以按照 1000000 的范围大小进行分段,
1 ~ 999999 放到表 1中,1000000 ~ 1999999 放到表2中,以此类推。
显然分段后,没法用单表的auto_increasement策略,这就势必需要业务层的介入。
复杂点:分段大小的选取:
分段太小会导致切分后子表数量过多,增加维护复杂度;
分段太大可能会导致单表依然存在性能问题,一般建议分段大小在 100 万至 2000 万之间,具体需要根据业务选取合适的分段大小。
优点:可以随着数据的增加平滑地扩充新的表。
例如,现在的用户是 100 万,如果增加到 1000 万,只需要增加新的表就可以了,原有的数据不需要动。
一般100万条以下不分表。
缺点:分布不均匀,假如按照 1000 万来进行分表,有可能某个分段实际存储的数据量只有 1000 多条,
而另外一个分段实际存储的数据量有 900 多万条。
这就可能会造成服务器的浪费。
2. Hash策略:
同样以用户 ID 为例,假如我们一开始就规划了 10 个数据库表,路由算法可以简单地用 user_id % 10
的值来表示数据所属的数据库表编号,ID 为 985 的用户放到编号为 5 的子表中,ID 为 10086 的用户
放到编号为 6 的字表中。
复杂点:初始表数量的选取。
表数量太多维护比较麻烦,表数量太少又可能导致单表性能存在问题。
优点:表分布比较均匀。
解决了自增策略的缺点。
缺点:扩充新的表很麻烦,所有数据都要重新分布。
因为事先规划好了表数量和路由算法。
这正是自增策略的优点。
所以主键自增策略的优点平滑地扩充新表是hash策略的缺点,主键自增策略的缺点分布不均匀是hasg策略的
优点。
也即,这两种策略都不能满足我们水平分表的要求。
引入分布式ID生成器:雪花算法,snow flake
3. 分布式ID生成器:雪花算法snow flake
分布式ID生成器有很多算法实现,只不过现在最流行的是雪花算法。
雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同表的主键的不重复性,以及相同表的
主键的有序性。
注意:生成的id是增长的,但不是+1递增,是按照时间的自增生成。
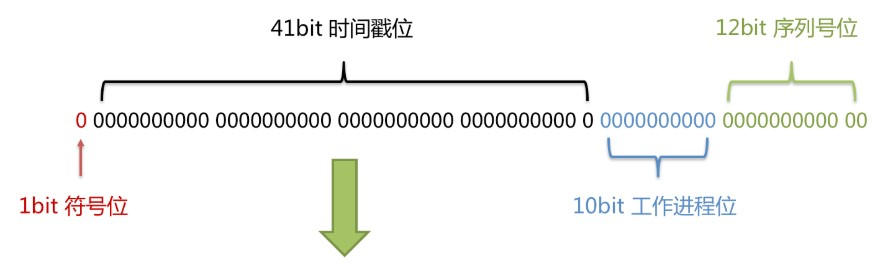
核心思想:
长度共64bit(一个long型)。
首先是一个符号位,1bit标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0
,负数是1,所以id一般是正数,最高位是0。
41bit时间截(毫秒级),存储的是时间截的差值(当前时间截 - 开始时间截),结果约等于69.73年。
在70年内,id一般都不会重复。
10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID,可以部署在1024个节点)。
12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID)。
优点:整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞,并且效率较高。
三、Mybatis_Plus的主键策略
1、ASSIGN_ID
MyBatis-Plus默认的主键策略是:ASSIGN_ID (使用了雪花算法)
默认使用的就是这个主键生成策略:所以可以不加这个注解
@TableId(type = IdType.ASSIGN_ID)
private String id;
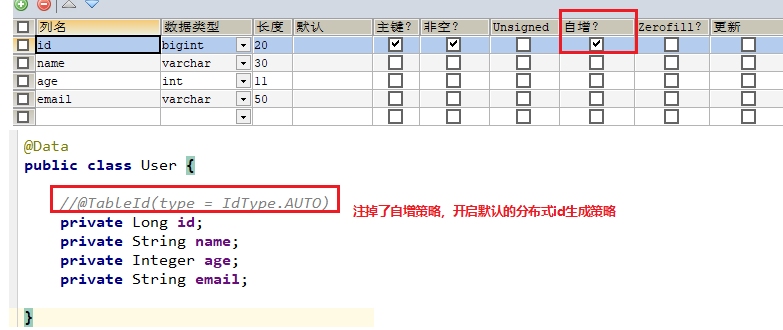
2、AUTO 自增策略
首先需要在创建数据表的时候设置支持主键自增
实体字段中配置 @TableId(type = IdType.AUTO)
@Data
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String name;
private Integer age;
private String email;
}
测试:testInsert()
3. 我选择默认的分布式id生成策略,同时开启mysql表的主键自增策略会怎样?
还是使用的分布式id生成策略,因为测试方法中没有传id值,但是Mybatis_plus生成了一个Id
传入的sql语气中。
所以如果传id值的话,就不用mysql的主键自增策略。
要想影响所有实体的配置,可以设置全局主键配置
4. 想给每一个entity类的id都设置一个主键生成策略:
mybatis-plus.global-config.db-config.id-type=auto
一般是不想用默认的分布式id生成策略时,才会开启此属性。
默认的都是type = IdType.ASSIGN_ID:分布式id生成策略。
自动填充和乐观锁
一、更新操作
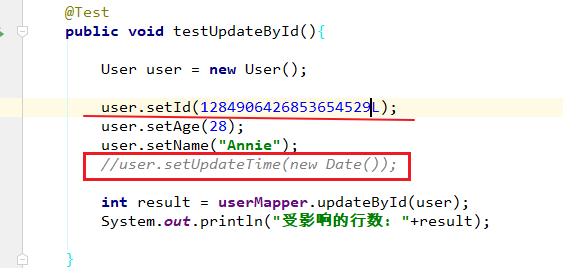
@Test
public void testUpdateById "Anni" );
int result = userMapper.updateById(user);
System.out.println("受影响的行数: " +result);
}
注意:update时生成的sql自动是动态sql:UPDATE user SET name=?, age=? WHERE id=?
userMapper.updateById(user):
其中id拼接在where后面,根据实体类的id找到对应表中的数据,比较哪些字段不同,然后进行修改。
所以age和name拼接在set后面。
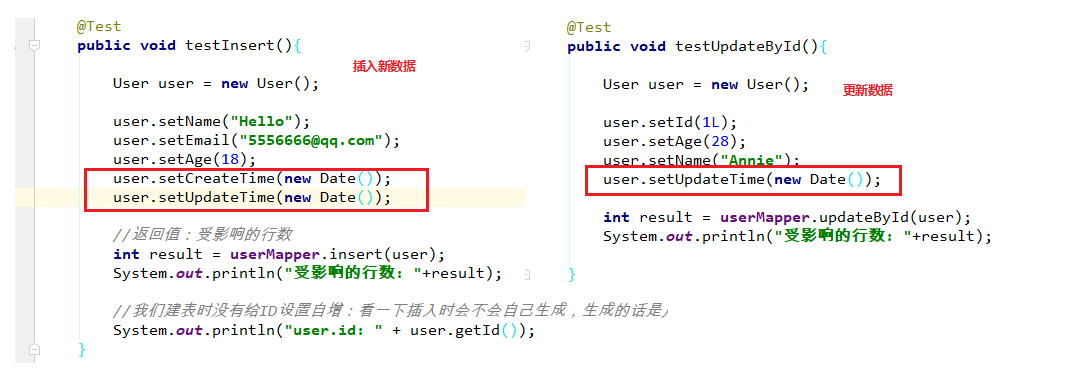
二、自动填充
需求描述:
项目中经常会遇到一些数据,每次都使用相同的方式填充,例如记录的创建时间,更新时间等。
我们可以使用MyBatis Plus的自动填充功能,完成这些字段的赋值工作。
1. 数据填充引入
Alibaba的Java开发规范:
要求数据库表里面除了id还必须有这两个dattime类型的字段:create_time、update_time
1. 想一下这两个字段我们每次更新的时候要不要都维护呢?
数据一更新:就要修改update_time
数据已创建:新增create_time和update_time
2. mybatis_plus会自动的对这样的一个编码风格进行映射
数据库字段:-
实体类:驼峰命名法
3. 有没有什么方法能帮我们做这些?
数据一更新:就要修改update_time
数据已创建:新增create_time和update_time
4. 数据库给这两个字段设置默认值:
当时数据库不止一种,当涉及到数据库迁移时,会非常麻烦,要再次重新设置默认值。
因为各个数据库的语法是不一样的。
所以一般不会采用数据库级别的手段来做,一般在业务层来实现。
5. 但是每次都在业务层做又太麻烦:
每次一个更新都要涉及到这两个字段的更新或新建代码,太麻烦。
6. Mybatis_plus给我们提供了一个插件:自动填充插件
我们可以不用再业务层写代码,自动的把这些你想自动填充的数据字段填充进去。
2. 添加自动填充注解
如何将create_time和update做一个自动的填充呢?
1. 实体类修改:添加自动填充注解
为你要自动填充的个字段:添加自动填充注解
@TableField(fill = FieldFill.INSERT)
@TableField(fill = FieldFill.INSERT_UPDATE)
@TableField(fill = FieldFill.INSERT)
private Date createTime;
插入的时候进行自动注入。
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updateTime;
插入和更新的时候都进行自动注入。
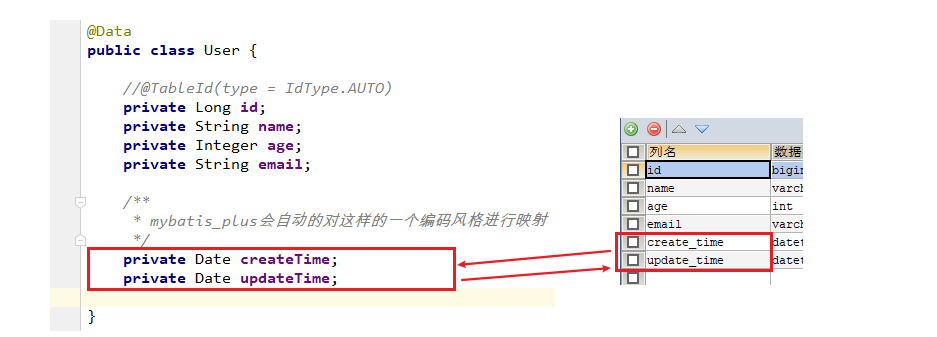
@Data
public class User {
//@TableId(type = IdType.AUTO)
private Long id;
private String name;
private Integer age;
private String email;
/**
* mybatis_plus会自动的对这样的一个编码风格进行映射
* 实体类:驼峰,数据库短横线 : -
*/
//添加自动填充注解
@TableField(fill = FieldFill.INSERT)
private Date createTime;
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updateTime;
}
3. 实现元对象处理器接口
mybatis_plus的底层代码会自动将要操作的元数据对象传递进来,然后对其createTime字段进行自动注入。
@Component //它要被Spring的上下文自动的调用:注入IOC中
public class MyMetaObjectHandler implements MetaObjectHandler {//实现元对象处理器接口
/**
* 增加的时候自动注入
* @param metaObject:元数据对象,被操作的实体类。
*
* mybatis_plus的底层代码会自动将操作的元数据对象传递进来,然后对createTime进行自动注入
*/
public void insertFill(MetaObject metaObject) {
System.out.println("insertFill......插入时自动注入" );
this.setFieldValByName("createTime" , new Date(), metaObject);
this.setFieldValByName("updateTime" , new Date(), metaObject);
}
/**
* 更新的时候自动注入
* @param metaObject
*/
public void updateFill(MetaObject metaObject) {
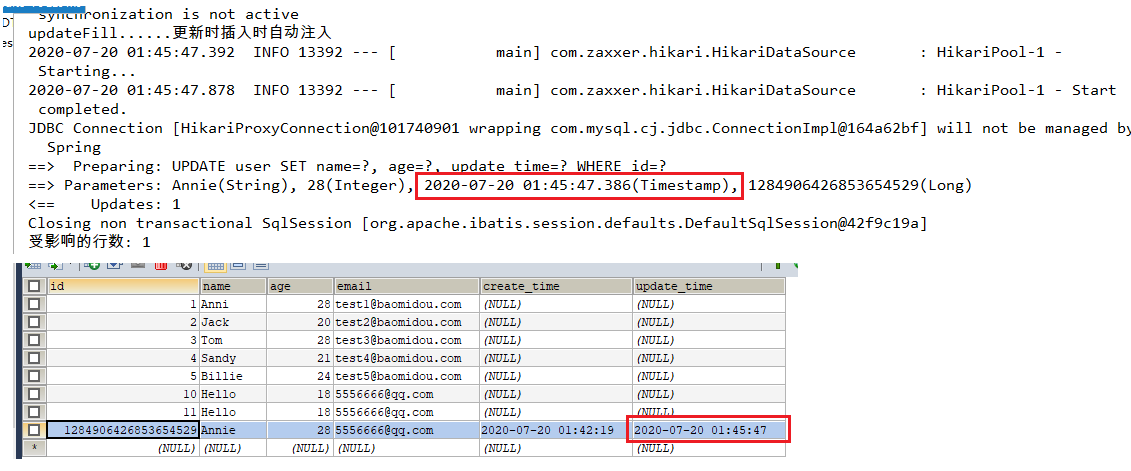
System.out.println("updateFill......更新时插入时自动注入" );
this.setFieldValByName("updateTime" , new Date(), metaObject);
}
}
分析一下代码:
1. 参数:MetaObject metaObject
元数据对象,属于被操作的实体类。
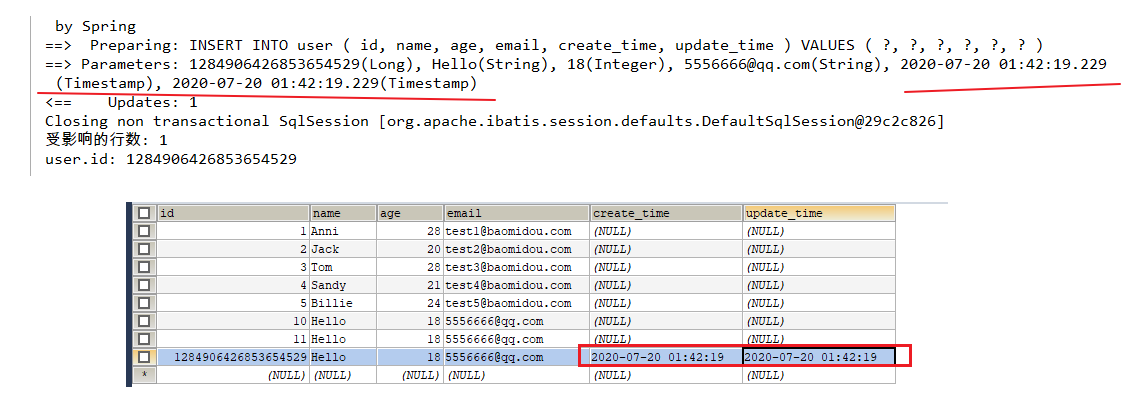
2. this.setFieldValByName("createTime", new Date(), metaObject);
this.setFieldValByName("updateTime", new Date(), metaObject);
插入时更新createTime字段和updateTime字段
mybatis_plus的底层代码会自动将要操作的元数据对象传递进来,然后对其createTime字段进行自动注入。
3. this.setFieldValByName("updateTime", new Date(), metaObject);
更新操作是时更新updateTime字段。
测试:插入一条数据
测试成功:
测试更新:
测试成功:
三、乐观锁
1、场景
一件商品,成本价是80元,售价是100元。老板先是通知小李,说你去把商品价格增加50元。小李正在玩游戏,
耽搁了一个小时。正好一个小时后,老板觉得商品价格增加到150元,价格太高,可能会影响销量。又通知小王,
你把商品价格降低30元。
此时,小李和小王同时操作商品后台系统。小李操作的时候,系统先取出商品价格100元;小王也在操作,取出
的商品价格也是100元。小李将价格加了50元,并将100+50=150元存入了数据库;小王将商品减了30元,并将
100-30=70元存入了数据库。是的,如果没有锁,小李的操作就完全被小王的覆盖了。
现在商品价格是70元,比成本价还低10元。几分钟后,这个商品很快出售了1千多件商品,老板亏1多万。
2、乐观锁与悲观锁
上面的故事,如果是乐观锁,小王保存价格前,会检查下价格是否被人修改过了。如果被修改过了,则重新
取出的被修改后的价格,150元,这样他会将120元存入数据库。
------检查数据的版本。
如果是悲观锁,小李取出数据后,小王只能等小李操作完之后,才能对价格进行操作,也会保证最终的价格是120元。
3、模拟修改冲突
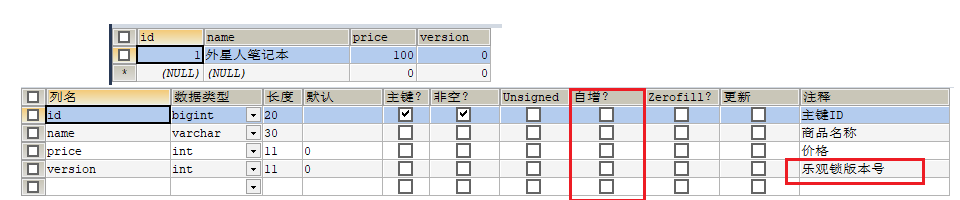
1. 数据库中增加商品表
CREATE TABLE product
(
id BIGINT(20) NOT NULL COMMENT '主键ID' ,
NAME VARCHAR(30) NULL DEFAULT NULL COMMENT '商品名称' ,
price INT(11) DEFAULT 0 COMMENT '价格' ,
VERSION INT(11) DEFAULT 0 COMMENT '乐观锁版本号' ,
PRIMARY KEY (id)
);
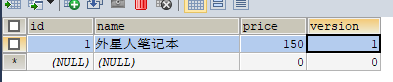
INSERT INTO product (id, NAME, price) VALUES (1, '外星人笔记本' , 100);
2. 实体类
@Data
public class Product {
private Long id;
private String name;
private Integer price;
private Integer version;
}
3. Mapper 持久层
@Repository
//继承了BaseMapper<Product>之后,ProductMapper就有了基本的增删改查的功能了。
public interface ProductMapper extends BaseMapper<Product> {
}
4. 测试方法
都是在原价格100的基础上进行修改,然后覆盖。
/**
* 测试锁:并发编程Concurrent
*/
@Test
public void testConcurrentUpdate "小李取出的价格:" +p1.getPrice());
//2. 小王获取数据
Product p2 = productMapper.selectById(1L);
System.out.println("小王取出的价格:" +p2.getPrice());
//3. 小李加了50元,存入数据库
p1.setPrice(p1.getPrice() + 50);
productMapper.updateById(p1);
//4. 小王减了30元,存入数据库
p2.setPrice(p2.getPrice() - 30);
productMapper.updateById(p2);
//5. 最后的结果,用户看到的商品价格
Product p3 = productMapper.selectById(1L);
System.out.println("商品的最终价格: " + p3.getPrice());
}
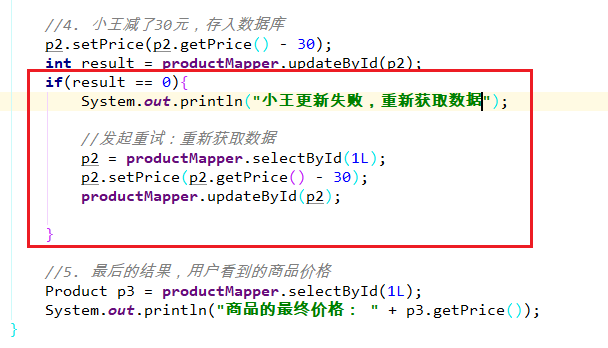
4、解决修改冲突
乐观锁:
无论是谁在更新数据之前,都要先对数据进行检查。如果数据的版本是对的话,才能对数据进行更新。
1. 解决思想
每一次获取数据的时候,都要把当前数据的版本号拿出来,取数据时要带着版本号。
每一次更新数据的时候时,除了要指定更新的是哪条记录外,还要指定更新的数据的当前版本。
比如说取出数据时版本是0,那么更新时必须其版本是0才对它进行更新,同时修改版本+1。
要保证:保存修改过的数据时,数据库中还有修改前的数据,这样才能覆盖。
2. 取出记录时,获取当前version
SELECT id,`name`,price,`version` FROM product WHERE id=1
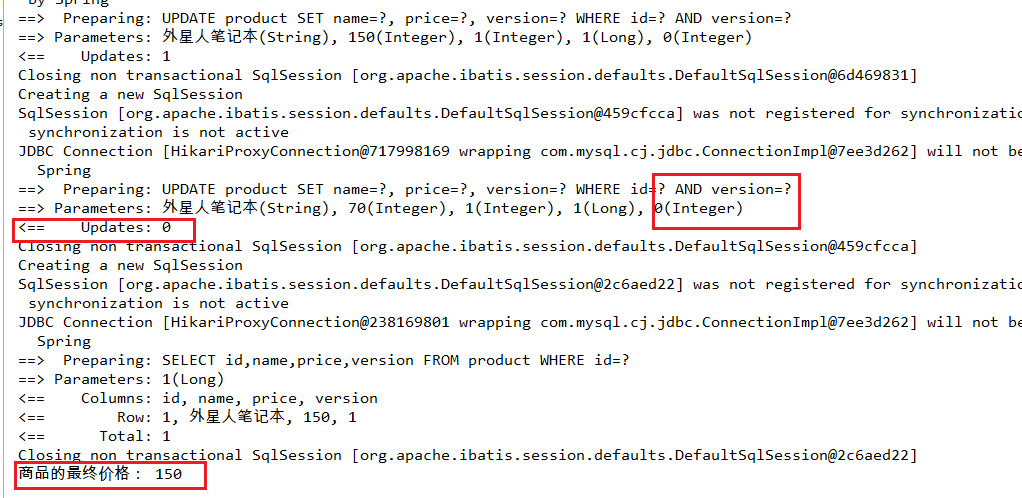
3. 更新时,version + 1,如果where语句中的version版本不对,则更新失败
UPDATE product SET price=price+50, `version`=`version` + 1 WHERE id=1 AND `version`=0
4. 分析
那么小王是后改数据的,在更新时就找不到version=0的数据了,就无法更新。
说明该数据已经被修改过了,要再修改后的数据基础上做操作。
5、乐观锁实现流程
1. 修改实体类
添加 @Version 注解
@Data
public class Product {
private Long id;
private String name;
private Integer price;
@Version
private Integer version;
}
2. 添加一个乐观锁插件
@EnableTransactionManagement // 事务处理
@Configuration
@MapperScan("com.atguigu.mybatis_plus.mapper" ) //把关于mybatis_plus都放到这里:扫描mapper文件
public class MybatisPlusConfig {
/**
* 添加一个乐观锁插件
* @return
*/
@Bean
public OptimisticLockerInterceptor optimisticLockerInterceptor return new OptimisticLockerInterceptor();
}
}
写了一个MybatisPlus的配置了:MybatisPlusConfig,那我们就把MybatisPlus的所有配置都放到
这里:
将之前写在主启动类上的@MapperScan("com.atguigu.mybatis_plus.mapper")放到这里。
3. 测试
1. 将数据修改回去
2. 测试方法没变
/**
* 测试锁:并发编程Concurrent
*/
@Test
public void testConcurrentUpdate "小李取出的价格:" +p1.getPrice());
//2. 小王获取数据
Product p2 = productMapper.selectById(1L);
System.out.println("小王取出的价格:" +p2.getPrice());
//3. 小李加了50元,存入数据库
p1.setPrice(p1.getPrice() + 50);
productMapper.updateById(p1);
//4. 小王减了30元,存入数据库
p2.setPrice(p2.getPrice() - 30);
productMapper.updateById(p2);
//5. 最后的结果,用户看到的商品价格
Product p3 = productMapper.selectById(1L);
System.out.println("商品的最终价格: " + p3.getPrice());
}
3. 分析一下:
我们给Version字段加了@Version注解,并且添加一个乐观锁插件。
此时小李获取数据时,会获取数据版本,保存数据时会比较版本,发现版本一致,可以报存并且更新版本。
小王获取数据会获取数据版本为0,保存数据时会比较版本发现版本变成了1,保存失败。
最后价格是150。
4. 修改一下测试类:实现老板的预期的效果,价格120
5. 测试:
此时数据version版本号变成了2
6. 用乐观锁解决了并发问题
CRUD接口--查询和分页
1. Mybatis_Plus的简单查询
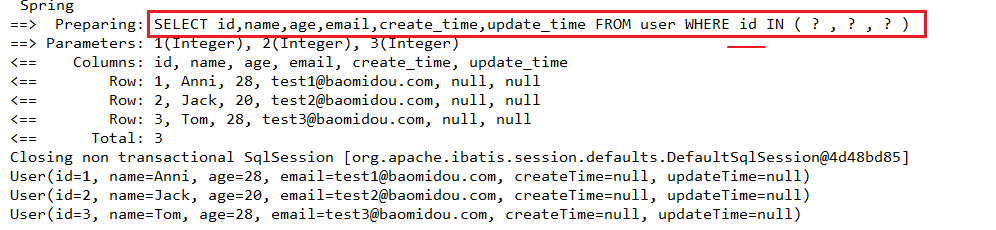
1. 通过多个id批量查询
1. 测试批量查询
/**
* 测试批量查询
*/
@Test
public void testSelectBatchIds 2. Mybatis_Plus生成的SQL:where in
SELECT id,name,age,email,create_time,update_time FROM user WHERE id IN ( ? , ? , ? )
2. 简单的条件查询
1. 测试简单的条件查询
/**
* 测试简单的条件查询:条件放到map中
*/
@Test
public void testSelectByMap "name" , "Helen" );
map.put("age" , 18);
userMapper.selectByMap(map);
}
2. Mybatis_Plus生成的SQL:
map中的每一个键值对元素,都是一个条件。
所有的条件用and连接。
SELECT id,name,age,email,create_time,update_time FROM user WHERE name = ? AND age = ?
注意:
map中的key对应数据库中的列名。如:数据库user_id,实体类是userId,这时map的key需要填写user_id。
2. Mybatis_Plus的分页查询
MyBatis Plus自带分页插件,只要简单的配置即可实现分页功能
2.1 简单的分页查询
1. 在MybatisPlusConfig 配置类中 添加一个分页插件
/**
* 添加一个分页插件
*/
@Bean
public PaginationInterceptor paginationInterceptor return new PaginationInterceptor();
}
2. 测试方法
/**
* 测试分页
*/
@Test
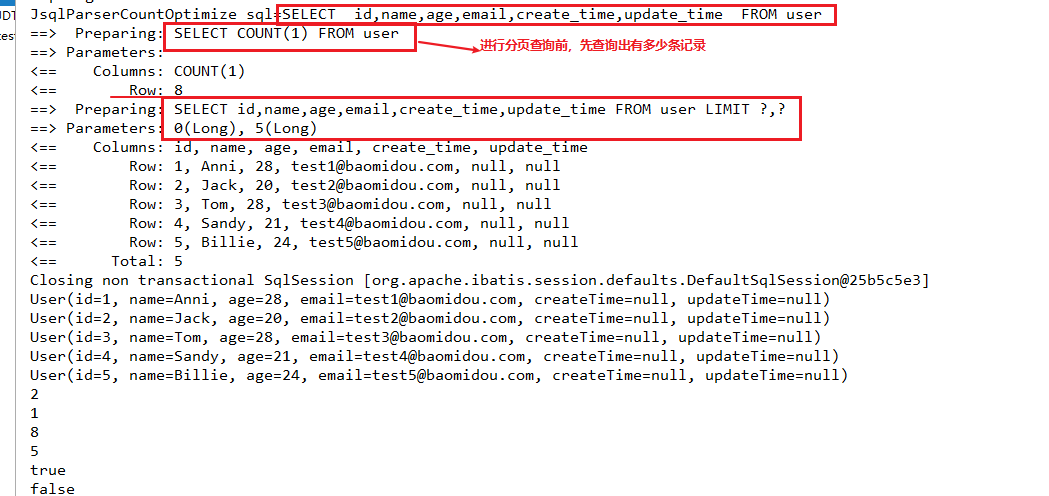
public void testSelectPage 3. 分析一下相关方法:
new Page<>(1, 5):
实例化一个Page对象,里面只有当前页1,和每页显示记录5.
userMapper.selectPage(page, null):
根据page对象,每页显示记录5,就可以得到一个包含所有分页信息的Page对象。
比如:
System.out.println(pageParam.getPages());//总页数
System.out.println(pageParam.getCurrent());//总记录数
System.out.println(pageParam.getTotal());//当前页码
System.out.println(pageParam.getSize());//每页记录数
System.out.println(pageParam.hasNext());//是否有下一页
System.out.println(pageParam.hasPrevious());//是否有上一页
4. 自动生成的SQL
分页查询前会先查询出总记录数:
SELECT COUNT(1) FROM user
SELECT id,name,age,email,create_time,update_time FROM user LIMIT ?,?
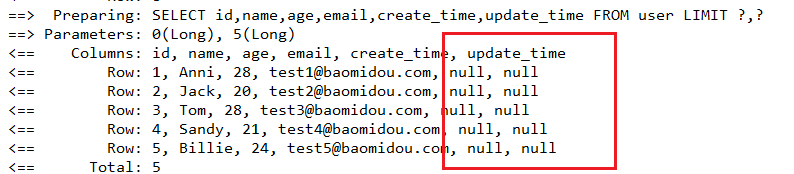
2.2 返回查询指定的列
userMapper.selectMapsPage(page, queryWrapper);
1. 我们上面测试的分页查询:将所有的列都查询了除了,如果指向返回指定的列该怎么操作?
而且有很多null列
2. New一个条件构造器:queryWapper()
测试方法:
/**
* 测试分页:只返回指定的列
* 分页查询我们的map结果集合
*/
@Test
public void testSelectMapsPage "id" , "name" );
Page<Map<String, Object>> page = new Page<>(1, 5);
Page<Map<String, Object>> pageParam = userMapper.selectMapsPage(page, queryWrapper);
List<Map<String, Object>> records = pageParam.getRecords();
records.forEach(System.out::println);
System.out.println(pageParam.getPages());//总页数
System.out.println(pageParam.getCurrent());//总记录数
System.out.println(pageParam.getTotal());//当前页码
System.out.println(pageParam.getSize());//每页记录数
System.out.println(pageParam.hasNext());//是否有下一页
System.out.println(pageParam.hasPrevious());//是否有上一页
}
分析一下:
1. queryWrapper.select("id", "name");
将我们的条件:分页查询时只显示指定的两列"id", "name",放到条件构造器中
2. Page<Map<String, Object>> 泛型是map<String, Object>,那么显然不止可以是User的分页信息对象。
3. 根据条件构造器queryWrapper,返回指定的列
userMapper.selectMapsPage(page, queryWrapper).getRecords();
删除和逻辑删除
1. 根据id删除记录
1. 测试方法
/**
* 根据id删除对应记录
*/
@Test
public void testDeleteById "删除了" + result + "行" );
}
2. 结果
2. 批量删除
1. 测试方法
/**
* 测试批量删除
*/
@Test
public void testDeleteBatchIds "删除了" + result + "行" );
}
2. 结果:DELETE FROM user WHERE id IN ( ? , ? , ? )
3. 根据条件删除
条件放到map中:deleteByMap(map);
1. 测试方法
/**
* 根据map中指定的条件删除
*/
@Test
public void testDeleteByMap "name" , "Sandy" );
map.put("age" , 21);
int result = userMapper.deleteByMap(map);
System.out.println("删除了" +result+"行" );
}
2. 结果:DELETE FROM user WHERE name = ? AND age = ?
4. 逻辑删除
1. 物理删除和逻辑删除
物理删除:真实删除,将对应数据从数据库中删除,之后查询不到此条被删除数据
逻辑删除:假删除,将对应数据中代表是否被删除字段状态修改为“被删除状态”,之后在数据库中
仍旧能看到此条数据记录
逻辑删除的使用场景:
可以进行数据恢复。
有关联数据,不便删除。
2. 逻辑删除实现流程
1. 添加deleted字段
ALTER TABLE `user` ADD COLUMN `deleted` BOOLEAN DEFAULT FALSE;
mysql数据库中没有真正的BOOLEAN类型:
它的tinyint类型就代表boolean类型,长度为1,默认值false用0表示。
2. 添加deleted 字段,并加上 @TableLogic 注解
我们想的是,删除时只改变deleted字段的值即可,即是一个update操作。
而且这个过程不需要我们自己做,Mybatis_Plus帮我们做了这些。
注意是Integer类型,数据库中是tinyint类型
@TableLogic //注意是Integer类型,数据库中是tinyint类型
private Integer deleted;
3. 测试方法
/**
* 测试逻辑删除
*/
@Test
public void testLogicDeleteById "删除了" + result + "行" );
}
4. 结果
测试方法是delete方法:userMapper.deleteById(1L);
但是实际上是一个update方法:UPDATE user SET deleted=1 WHERE id=? AND deleted=0
Mybatis做了优化:不仅仅是id=1,还必须是deleted=0
5. 我们还要实现查询的时候查询不到deleted=1的记录
@TableLogic //注意是Integer类型,数据库中是tinyint类型
private Integer deleted;
注意:
@TableLogic 这个注解会让我们进行查询的时候,过滤掉deleted=1的值。
会把deleted当作逻辑列处理,会在查询时加上:WHERE deleted=0条件
1. 简单的查询
@Test
void testLogicSelectList 2. 结果:自动过滤掉deleted=1的值
SELECT id,name,age,email,deleted,create_time,update_time FROM user WHERE deleted=0
6. 逻辑删除中的可选配置
约定成俗的规定:默认情况下也是逻辑列:没删是0,删了是1
mybatis-plus.global-config.db-config.logic-delete-value=1
mybatis-plus.global-config.db-config.logic-not-delete-value=0
条件构造器
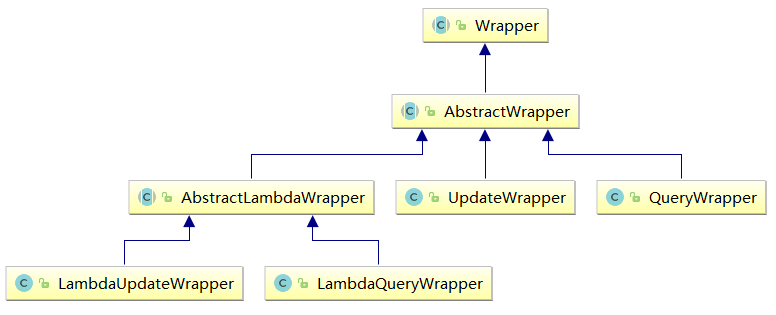
1. wapper介绍
体系:
Wrapper : 条件构造抽象类,最顶端父类
AbstractWrapper : 用于查询条件封装,生成 sql 的 where 条件
QueryWrapper : 查询select条件封装
UpdateWrapper : Update 条件封装
AbstractLambdaWrapper : 使用Lambda 语法
LambdaQueryWrapper :用于Lambda语法使用的查询Wrapper
LambdaUpdateWrapper : Lambda 更新封装Wrapper
2. 测试用例
1. 将条件封装到 QueryWrapper 中,根据QueryWrapper进行查询
queryWrapper封装多个查询对象,且返回值是自己
queryWrapper.
ge("age", 28).
isNotNull("email").
isNotNull("name");
生成的SQL:
UPDATE user SET deleted=1 WHERE deleted=0 AND (age >= ? AND email IS NOT NULL AND name IS NOT NULL)
@Test
public void testDelete "age" , 28).
isNotNull("email" ).
isNotNull("name" );
int result = userMapper.delete(queryWrapper);
System.out.println("删除了" +result+"行" );
}
2. selectOne方法
@Test
public void testSelectOne "age" , 28);
User user = userMapper.selectOne(queryWrapper);
System.out.println(user);
}
注意:selectOne方法()返回的是一条实体记录,当出现多余时会报错。
可以应用在:验证登录信息场景。
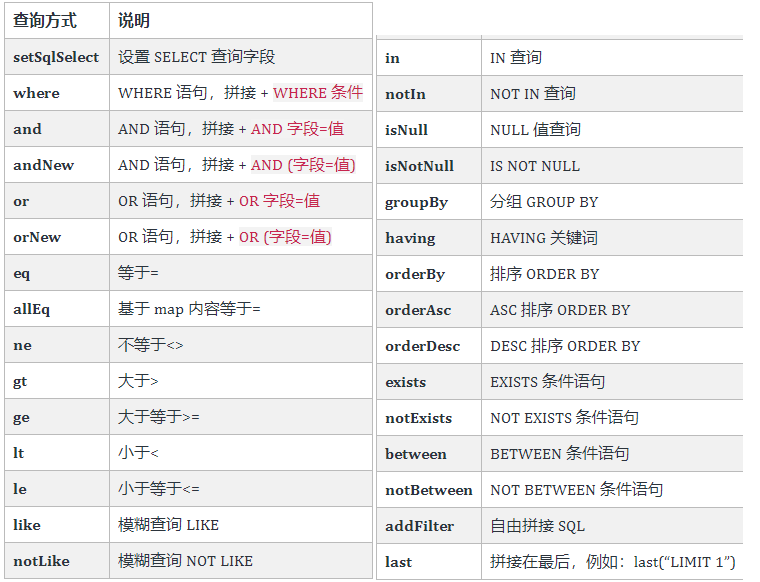
2.1 in、notIn、inSql、notinSql、exists、notExists
in、notIn:
notIn("age",{1,2,3})--->age not in (1,2,3)
notIn("age", 1, 2, 3)--->age not in (1,2,3)
inSql、notinSql:可以实现子查询
例: inSql("age", "1,2,3,4,5,6")--->age in (1,2,3,4,5,6)
例: inSql("id", "select id from table where id < 3")--->
id in (select id from table where id < 3)
@Test
public void testSelectObjs "id" , 1, 2, 3);
queryWrapper.inSql("id" , "select id from user where id <= 3" );
List<Object> objects = userMapper.selectObjs(queryWrapper);//返回值是Object列表
objects.forEach(System.out::println);
}
2.2 or、and
注意:这里使用的是 UpdateWrapper
不调用or则默认为使用 and 连
@Test
public void testUpdate1 "Andy" );
//修改条件
UpdateWrapper<User> userUpdateWrapper = new UpdateWrapper<>();
userUpdateWrapper
.like("name" , "h" )
.or()
.between("age" , 20, 30);
int result = userMapper.update(user, userUpdateWrapper);
System.out.println(result);
}
2.3 lambda表达式
lambda表达式内的逻辑优先运算
@Test
public void testUpdate2 "Andy" );
//修改条件
UpdateWrapper<User> userUpdateWrapper = new UpdateWrapper<>();
userUpdateWrapper
.like("name" , "n" )
.or(i -> i.like("name" , "a" ).eq("age" , 20));
int result = userMapper.update(user, userUpdateWrapper);
System.out.println(result);
}
2.4 orderBy、orderByDesc、orderByAsc
@Test
public void testSelectListOrderBy "age" , "id" );
List<User> users = userMapper.selectList(queryWrapper);
users.forEach(System.out::println);
}
2.5 set、setSql
最终的sql会合并 user.setAge(),以及 userUpdateWrapper.set() 和 setSql() 中 的字段
@Test
public void testUpdateSet "name" , "h" )
.set("name" , "Peter" )//除了可以查询还可以使用set 设置修改的字段
.setSql(" email = '123@qq.com'" );//可以有子查询
int result = userMapper.update(user, userUpdateWrapper);
}
2.6 查询条件和说明