

一、XOR逻辑回归
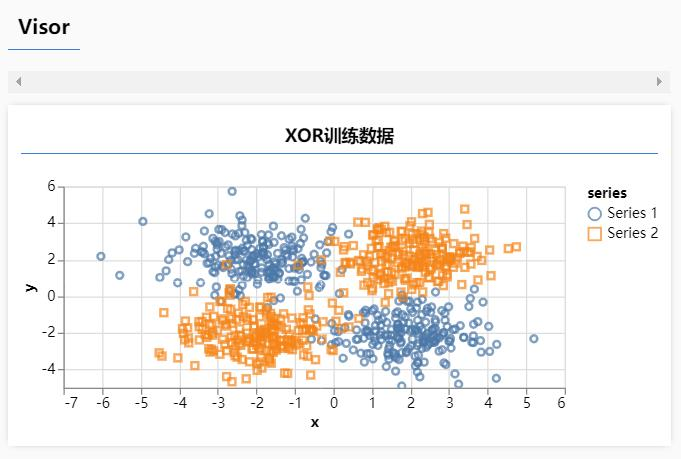
XOR表示抑或。两个数相同,得到的是0,两个数不同,得到的是1。 如下图所示,当点的x和y坐标都为正的时候,是黄色的点。当点的x和y坐标一个为正,一个为负的时候,是蓝色的点。这就是一个XOR问题。

如果一个数据集是呈线性分布的时候,那它就可以一条线画出来。显然,图中这个问题不是线性问题。
通过Playground,即playground.tensorflow.org/,来学习一下多层神经网络。这个网站实际上也是基于TensorFlow.js实现的,用TensorFlow.js实现的好处是可以充分利用浏览器用户端的资源进行训练,而不用像Python实现那样大量消耗网站服务器的计算资源。
下面我们简单介绍一下Playground。

上图中:
刷新按钮是重置数据集;
开始按钮是开始训练;
下一步按钮是手工单步训练;
Epoch是训练的轮数;
Learning rate是学习率;
Activation是激活函数;
Regularization是正则化;
Regularization rate是正则化率;
Problem type是问题类别,如回归问题,分类问题。
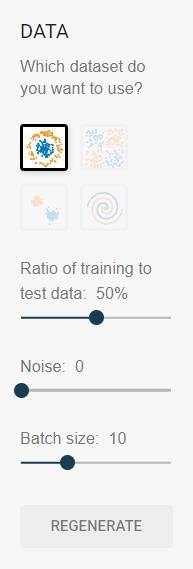
上图中是数据集的选择和数据集的参数设置。其中:
Ratio of training to test data是训练集的比例; Noise是噪音,指的是这个数据集有多少干扰因素; Bach size前面学习过。
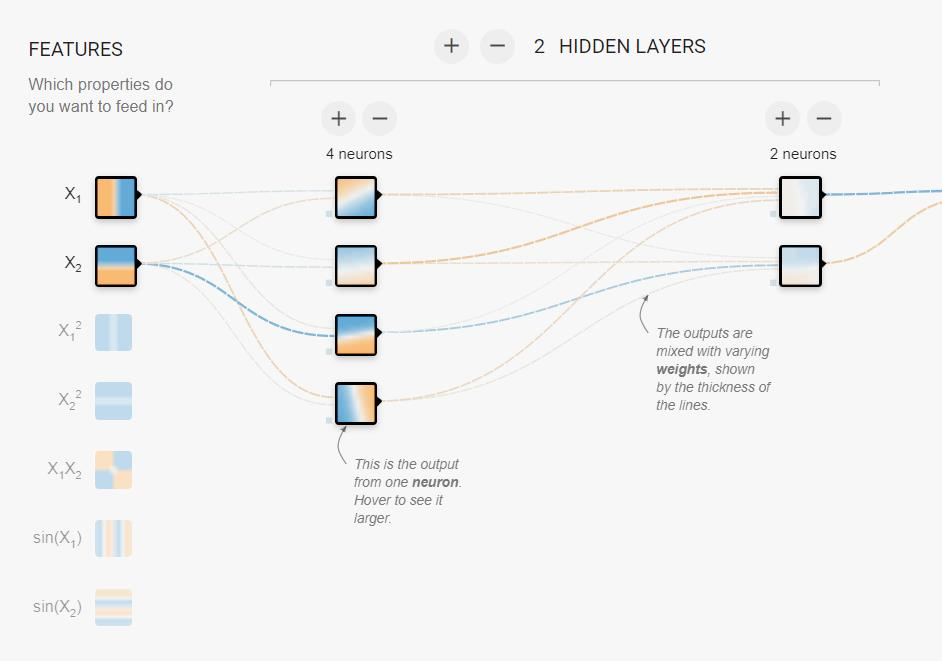
Feature是特征; Hidden layers是隐藏层; neurons是神经元。
有时候,隐藏层层数过少或神经元个数过少导致损失降不下来时,可以通过增加层数和增加神经元个数让损失降下来。
如下图所示是一个Playground调整层数和神经元个数拟合的结果:
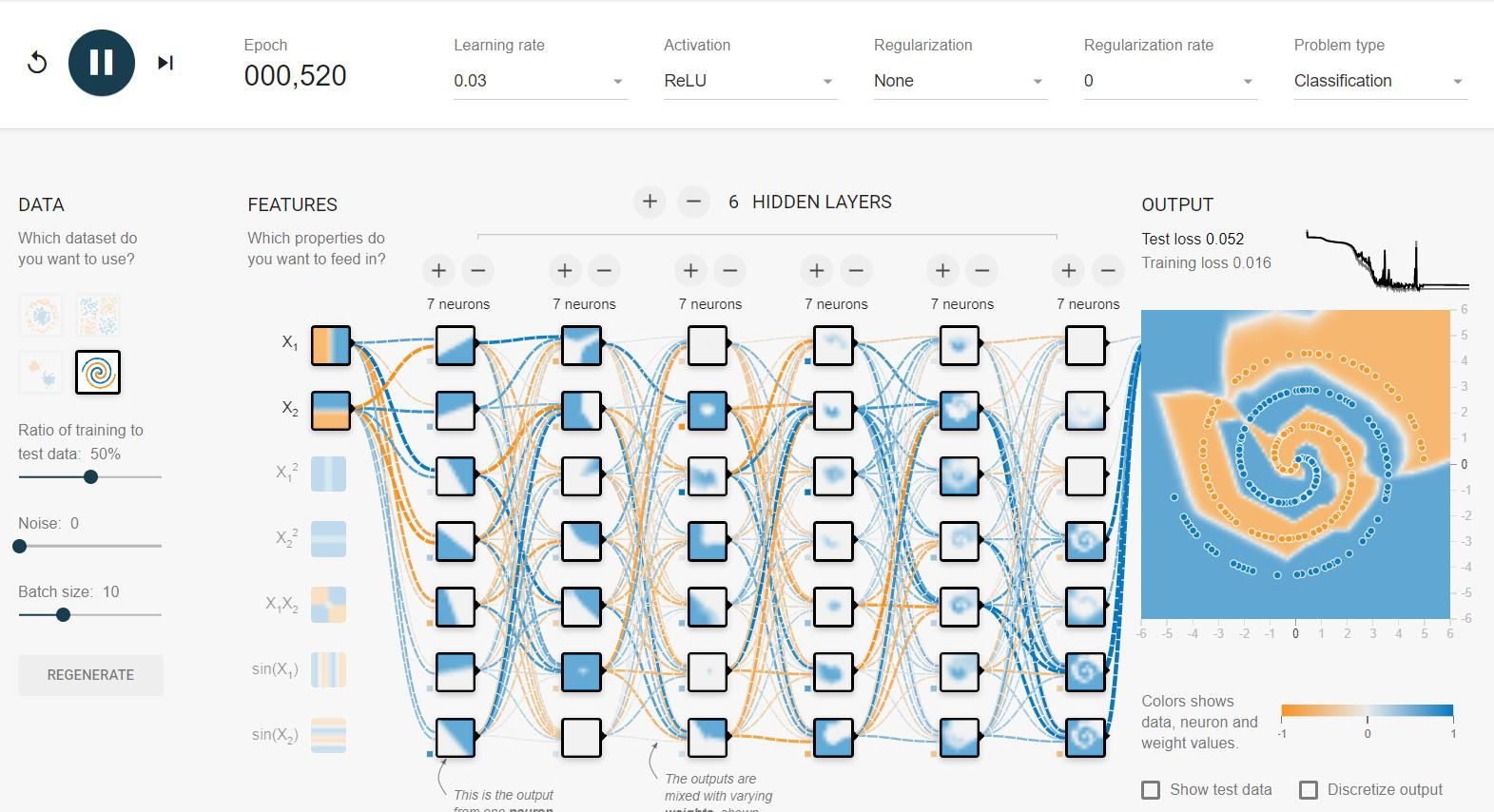
操作步骤:
1)加载XOR数据集
2)定义模型结构:多层神经网络
3)训练模型并预测
二、加载XOR数据集
1、使用脚本生成XOR数据集
src\xor\data.js
export function getData(numSamples) {
let points = [];
function genGauss(cx, cy, label) {
for (let i = 0; i < numSamples / 2; i++) {
let x = normalRandom(cx);
let y = normalRandom(cy);
points.push({x, y, label});
}
}
genGauss(2, 2, 0);
genGauss(-2, -2, 0);
genGauss(-2, 2, 1);
genGauss(2, -2, 1);
return points;
}
/**
* random generator
*
* @param {number} [mean=0]
* @param {number} [variance=1]
* @returns
*/
function normalRandom(mean = 0, variance = 1) {
let v1, v2, s;
do {
v1 = 2 * Math.random() - 1;
v2 = 2 * Math.random() - 1;
s = v1 * v1 + v2 * v2;
} while (s > 1);
let result = Math.sqrt(-2 * Math.log(s) / s) * v1;
return mean + Math.sqrt(variance) * result;
}
2、可视化XOR数据集
src\xor\index.js
import * as tfvis from '@tensorflow/tfjs-vis';
import { getData } from './data';
window.onload = () => {
const data = getData(400);
tfvis.render.scatterplot(
{name: 'XOR训练数据'},
{
values: [
data.filter(p => p.label === 1),
data.filter(p => p.label === 0)
]
}
)
}
三、定义模型结构:多层神经网络
操作步骤:
1)初始化一个神经网络模型;
2)为神经网络模型添加两个层;
3)设计层的神经元个数、inputShape、激活函数。
代码如下:
const model = tf.sequential(); // 初始化一个sequential模型
model.add(tf.layers.dense({
units: 4, // 神经元个数
inputShape: [2], // 第一层需要设置inputShape,后面的层就不需要了,会自动设定(因为下一层的输入就是上一层的输出,比如,这里的这一层是4个神经元,那么下一层的inputShape其实可以自动得到,就是[4],所以,下一层就不需要再指明inputShape了)。这里我们设置inputShape为2,即长度为2的一维数组,因为我们这里的特征个数是2。
activation: 'relu', // 设一个激活函数,实现非线性的变化,我们这里任意选了一个非线性的relu
}));
// 接下来我们设置输出层
model.add(tf.layers.dense({
units: 1, // 输出层的神经元个数是1,因为我们只需要输出一个概率
activation: 'sigmoid', // 因为输出层需要输出一个[0,1]之间的概率,所以这里activation只能设置成sigmoid
}));
四、训练模型并预测
操作步骤:
训练模型并可视化训练过程
编写前端界面并预测。
1、训练模型并可视化训练过程
model.compile({
loss: tf.losses.logLoss, // 损失函数这里也用logLoss,因为它本质上也是一个逻辑回归
optimizer: tf.train.adam(0.1), // 优化器使用adam,并且设置学习率为0.1
});
2、训练模型并可视化训练过程
model.compile({
loss: tf.losses.logLoss, // 损失函数这里也用logLoss,因为它本质上也是一个逻辑回归
optimizer: tf.train.adam(0.1), // 优化器使用adam,并且设置学习率为0.1
});
const inputs = tf.tensor(data.map(p => [p.x, p.y]));
const labels = tf.tensor(data.map(p => p.label));
// 进行训练
await model.fit(inputs, labels, {
epochs: 10,
// 可视化训练过程
callbacks: tfvis.show.fitCallbacks({
name: '训练效果'
}, // 图表的标题
['loss'] // 度量单位,只看损失
)
});
3、编写前端界面并预测
完整的代码如下:
src\xor\index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script src="index.js"></script>
<form action="" onsubmit="predict(this); return false;">
x: <input type="text" name="x">
y: <input type="text" name="y">
<button type="submit">提交</button>
</form>
</body>
</html>
src\xor\index.js
import * as tf from '@tensorflow/tfjs';
import * as tfvis from '@tensorflow/tfjs-vis';
import {
getData
} from './data';
window.onload = async () => {
const data = getData(400);
tfvis.render.scatterplot({
name: 'XOR训练数据'
}, {
values: [
data.filter(p => p.label === 1),
data.filter(p => p.label === 0)
]
});
const model = tf.sequential(); // 初始化一个sequential模型
model.add(tf.layers.dense({
units: 4, // 神经元个数
inputShape: [2], // 第一层需要设置inputShape,后面的层就不需要了,会自动设定(因为下一层的输入就是上一层的输出,比如,这里的这一层是4个神经元,那么下一层的inputShape其实可以自动得到,就是[4],所以,下一层就不需要再指明inputShape了)。这里我们设置inputShape为2,即长度为2的一维数组,因为我们这里的特征个数是2。
activation: 'relu', // 设一个激活函数,实现非线性的变化,我们这里任意选了一个非线性的relu
}));
// 接下来我们设置输出层
model.add(tf.layers.dense({
units: 1, // 输出层的神经元个数是1,因为我们只需要输出一个概率
activation: 'sigmoid', // 因为输出层需要输出一个[0,1]之间的概率,所以这里activation只能设置成sigmoid
}));
model.compile({
loss: tf.losses.logLoss, // 损失函数这里也用logLoss,因为它本质上也是一个逻辑回归
optimizer: tf.train.adam(0.1), // 优化器使用adam,并且设置学习率为0.1
});
const inputs = tf.tensor(data.map(p => [p.x, p.y]));
const labels = tf.tensor(data.map(p => p.label));
// 进行训练
await model.fit(inputs, labels, {
epochs: 10,
// 可视化训练过程
callbacks: tfvis.show.fitCallbacks({
name: '训练效果'
}, // 图表的标题
['loss'] // 度量单位,只看损失
)
});
window.predict = async (form) => {
const pred = await model.predict(tf.tensor([
[+form.x.value, +form.y.value]
]));
alert(`预测结果:${pred.dataSync()[0]}`);
};
}
最后,我们验证一下预测结果:
输入x:2,y:2,得到“预测结果:0.0029660461004823446”;
输入x:-2,y:-2,得到“预测结果:0.00246746395714581”;
输入x:-2,y:2,得到“预测结果:0.9977003931999207”;
输入x:2,y:-2,得到“预测结果:0.9853619337081909”。
