

刚挂到arxiv的的短文,文章针对ReID提出了自适应的L2正则化。通过引入可训练的标量正则化因子,和hard sigmoid函数,自适应的随着训练调整L2正则化,使模型表现得到提高,并在MSMT17数据集中达到了SOTA。
源码(截止我读论文为止还未公布):
论文一览:

痛点
当前作者认为对L2正则化的研究虽然有,但是还不算多,特别是很多问题理所当然拿来使用,并没有多加描述。而且这些L2正则化的方式通常是利用人工选定的正则化因子,这些因子作为一个常数在整个训练过程中保持不变。而本文的提出的L2正则化目的就是优化传统L2正则化的瓶颈,在整个训练过程中将其自适应的更新。该方法能够对神经网络的参数施加约束,并在优化过程中对目标函数增加惩罚。
模型
设神经网络有N组参数:
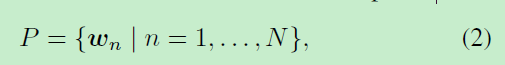
P包含所有可训练参数
传统的L2正则化作为惩罚项可以表示为:
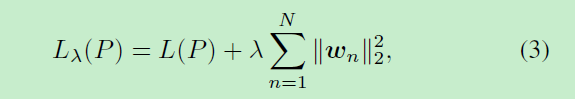
其中为更新的目标函数,λ为正则化强度。
作者为每一组参数都提供了专门的系数
,作者将它们视为可学习的参数,并从数据本身中通过训练找到合适的值。但是对
不加任何限制是不行的,为了防止
降为负数,导致模型崩溃,文章还施加了hard sigmoid函数,其定义为:
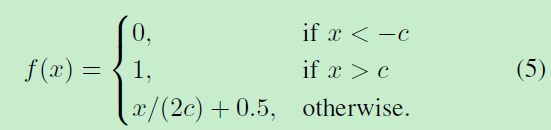
c在本文取2.5,通过对原始参数应用hard sigmoid函数来获得正则化因子,

加上幅值A有:

那么整个完整式子为:
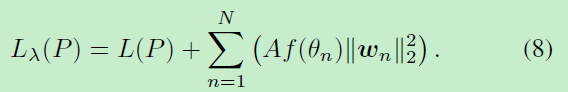
实验
使用的数据集一览:
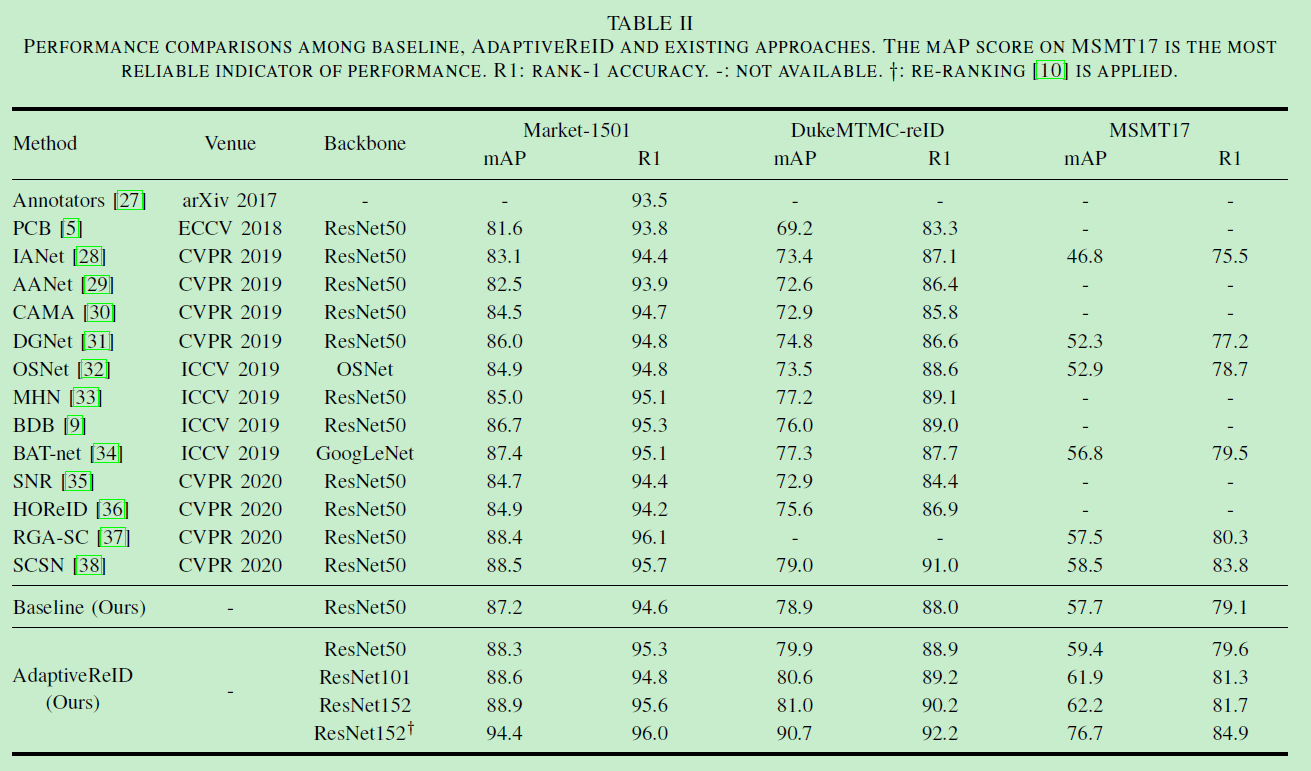
在MSMT17数据集的SOTA对比:
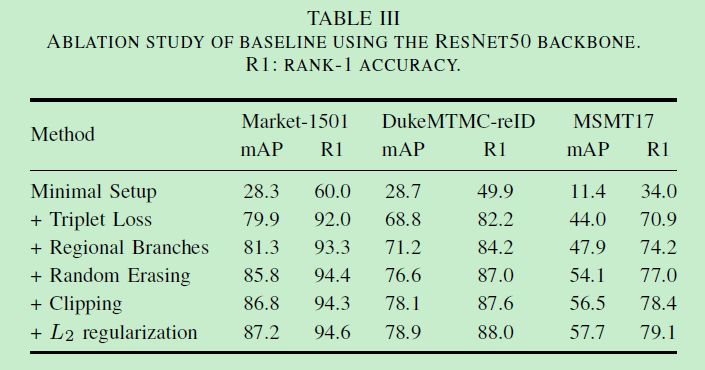
对其他常用提点trick的兼容性分离实验:
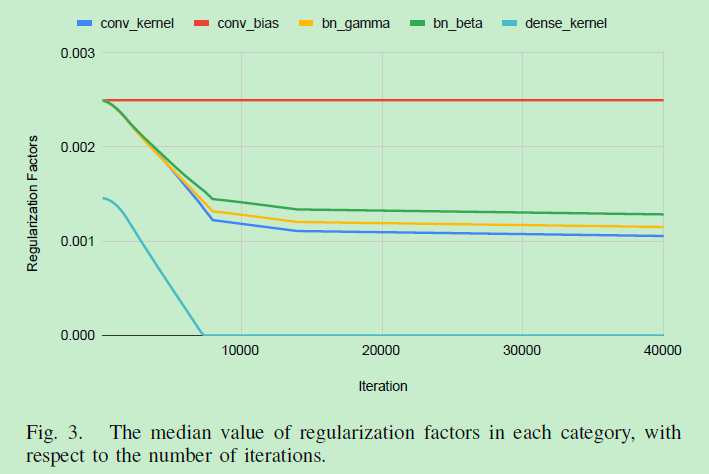
随着迭代数变化正则化因子的中位数变化:
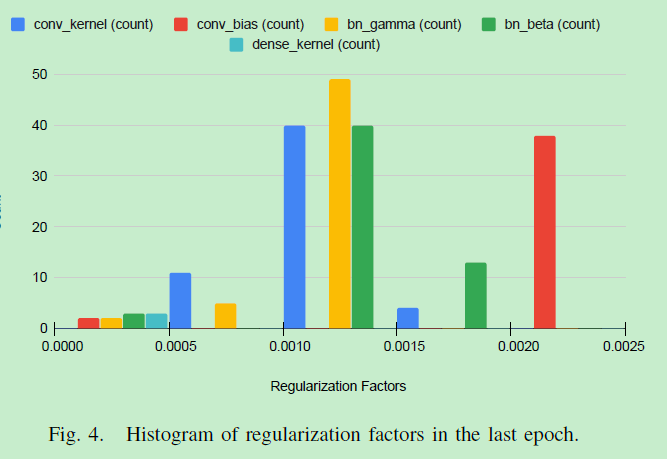
最后一个epoch的正则化因子直方图
3个数据集上的rank可视化:

绿框是正确分类的,红框是错误分类的。可以看到即使在MSMT17数据这种光照变化较大的情况下,文章模型也可以检索正确的匹配项。
参考文献
[1] Ni X, Fang L, Huttunen H. AdaptiveReID: Adaptive L2 Regularization in Person Re-Identification[J]. arXiv preprint arXiv:2007.07875, 2020.
