

今天和大家一起看下Mysql的常见优化手段,本文将从三个方面讲述优化。一:配置上优化,二:表设计优化, 三:查询优化。 Mysql相关文章是一系列的整理,还是建议大家花点时间,看下我之前写的文章,了解一些上下文。
配置优化
-
innodb_buffer_pool_size: 设置buffer pool的大小,一般设置可用内存的70~80%
-
innodb_log_file_size: 设置redo log 单个文件大小,可以设置1G
-
innodb_io_capacity:全力刷脏页速度。设置为磁盘的IOPS。
-
innodb_flush_log_at_trx_commit:redo log fsync设置, 设为2
-
sync_binlog:binlog fsync 设置 ,设为 100~1000
注: 后面这两个设为非双1,是有损的,一般情况下建议设为双1,特殊情况下才会改这两个
对上面几个配置稍作说明,buffer_pool_size, 我们知道是设置buffer pool大小的,而buffer pool是内存缓冲里面关键中的关键,里面存放了数据页,索引页等信息,能否避免随机访问磁盘就看能否命中buffer pool里的数据了。而innodb_log_file_size是设置redo log单个文件大小,我们前面说过mysql WAL技术就是先写的redo log和bin log,如果redo log文件太小就会经常执行刷盘操作,系统会经常发生抖动(即有时sql突然执行的很慢)。看了高性能Mysql配置章节的同学知道,几十页的介绍以后,给了建议就是buffer pool size和innodb log file size两个优化就能解决大多数场景的配置优化了。
再看innodb_io_capacity 为什么要改这个设置呢?这个是告诉Innodb 系统最大的IO速度是多少,也就是如果全力刷脏页能刷多快,InnoDB会根据这个值和脏页比例算出一个合适的值,按一定的速度刷脏页(简单理解为这个值越大刷脏页的速度越大),现在大部分都是使用SSD了,随机IO速度是机械硬盘的几倍甚至几十倍,所以再使用默认值(200)就明显拖慢InnoDB刷脏页的速度了。
再看后面两个设置,innodb_flush_log_at_trx_commit 和 sync_binlog 设置redo log和bin log的fsync(即真正写磁盘)时机,当设为非1时,并不会每次都执行写磁盘操作,性能会有很大提升,但缺点就是可能丢数据。具体原因可以看看我之前写的Mysql 日志,这里就略过了。
表设计优化
-
不要有太多的索引。
我们知道索引在更新时需要维护,影响更新的速度,且索引占用内存和磁盘 -
理解索引最左前缀原则,精简索引。
如(a, b, ab) 可以精简成 b, ab -
索引字段要区分度很高且越短越好。
如ID 使用int
如我们公司的邮箱都是XXX@YYY.com,所以精简为只使用邮箱前缀做索引区分度一样,且更短
查询优化
查询优化的秘诀就是减少扫描行数。
-
添加索引,或者sql只查需要的字段,减少带宽压力 这两个是我们最常用的优化
-
选错索引的优化:优化器是估算的扫描行数,所以当有多个索引选择时,可能会选错,导致查询很慢。
analyze table t;// 修正索引信息
force index();//强制使用某个索引
删掉被错选的索引 -
优化排序:将排序改成联合索引。 如select id, name, age from student where name = 'cc' order by age; //可以建立(name, age)索引,因为索引本身就是由低到高排序的。
-
修改索引,使用覆盖索引。覆盖索引避免了回表查询的过程,可以很好的提升性能。
联合查询优化
可能有些同学被资深的同事教育,不要使用join 语句,那么是不是不能使用join语句呢?我们一起来看看mysql中join语句执行的算法。

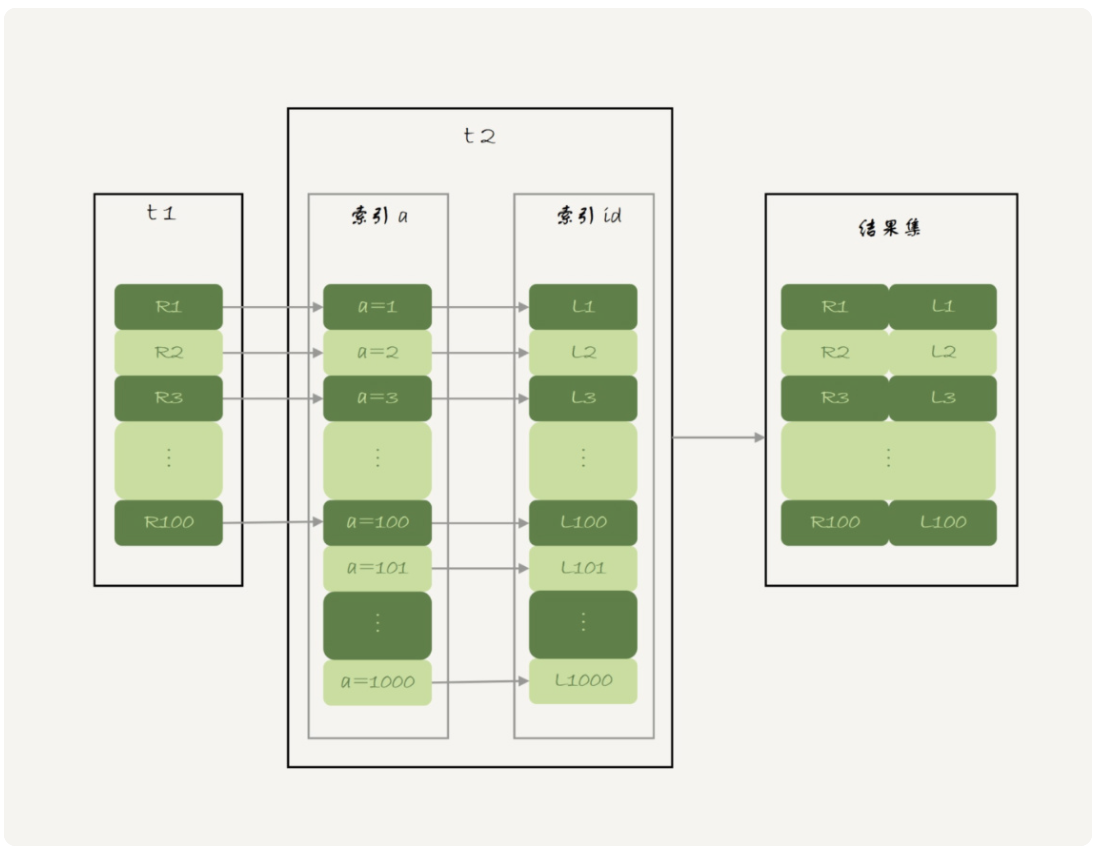
- 从表 t1 中读入一行数据 R;
- 从数据行 R 中,取出 a 字段到表 t2 里去查找;
- 取出表 t2 中满足条件的行,跟 R 组成一行,作为结果集的一部分;
- 重复执行步骤 1 到 3,直到表 t1 的末尾循环结束。
假设t1,t2都是100行数据,这个过程中对驱动表 t1 做了全表扫描,需要扫描 100 行;而对于每一行 R,根据 a 字段去表 t2 查找,走的是树搜索过程。由于我们构造的数据都是一一对应的,因此每次的搜索过程都只扫描一行,也是总共扫描 100 行;所以,整个执行流程,总扫描行数是 200。
而如果拆成单表查询,每次再根据t1查的结果去t2表里查询,将结果集合并并返回,也是扫描200行,而且还多了100次sql交互,所以当被驱动表关联字段走索引时,用join语句更好。
我们再看看当被驱动表没有索引时,如果使用简单的按照上面的算法,因为没有索引,每一行记录R到t2表中都要进行全表扫描,扫描行数就是100*100,一百万次显然时间复杂度太大。mysql使用了一种优化算法,Block Nested-Loop Join算法,简称BNL算法。 假设被驱动表t2上没有可用的索引,算法的流程是这样的:
- 把表 t1 的数据读入线程内存 join_buffer 中,由于我们这个语句中写的是 select *,因此是把整个表 t1 放入了内存;
- 扫描表 t2,把表 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回。
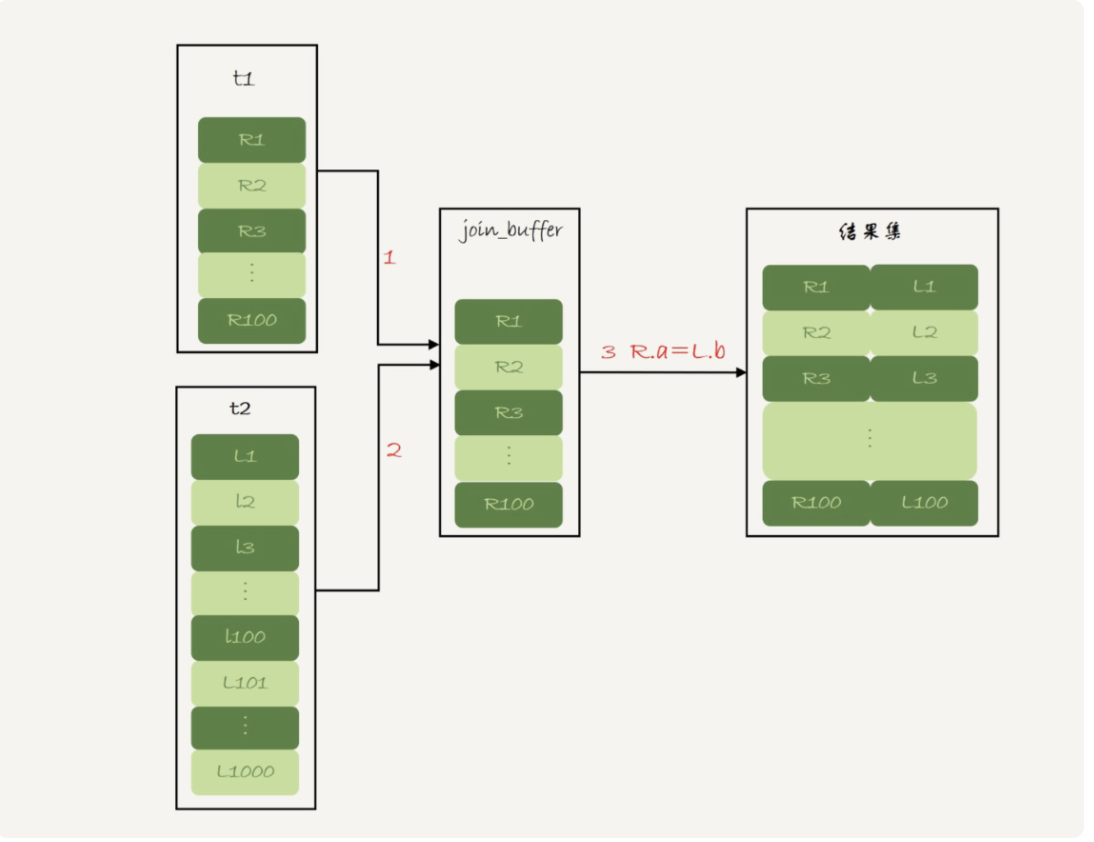

如果是这样那和分开单表查效率应该不会差别太大啊,但是当t1表太大,join buffer放不下时,就会分多次放入,这个时候t2表也会扫描多次,所以建议当被驱动表关联字段没有索引时,不要使用join 语句。
总结:join语句的优化是被驱动表关联字段使用索引。
group by 优化
如下面这条sql id按10取模后分组,统计数量

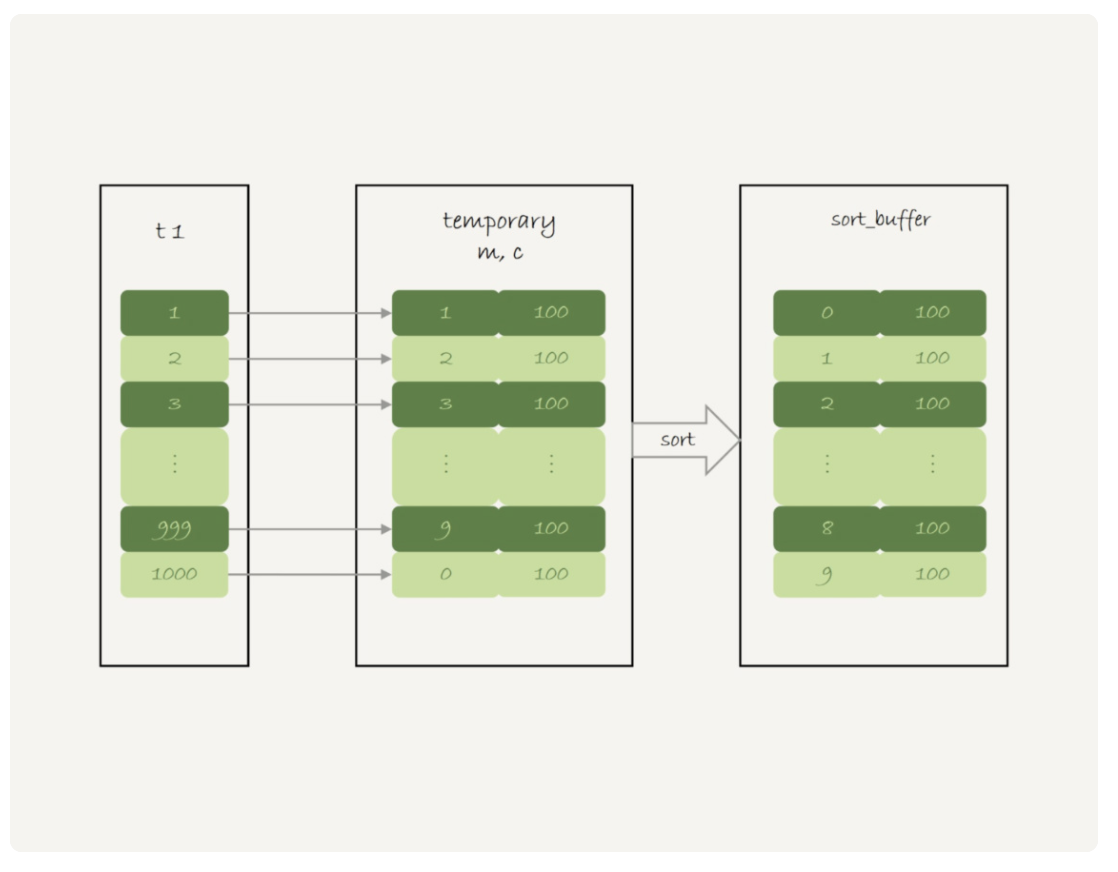
语句的执行流程是这样的:
- 创建内存临时表,表里有两个字段 m 和 c,主键是 m;
- 扫描表 t1 的索引 a,依次取出叶子节点上的 id 值,计算 id%10 的结果,记为 x;
- 如果临时表中没有主键为 x 的行,就插入一个记录 (x,1);如果表中有主键为 x 的行,就将 x 这一行的 c 值加 1;
- 遍历完成后,再根据字段 m 做排序,得到结果集返回给客户端。
这个流程的执行图如下:
- 当不需要排序时可以使用order by null告诉优化去不需要排序(mysql 8.0以后的版本内部已经做了这个优化)
- 将group by字段建立索引(就是因为要暂存数据所以才使用临时表,当对group by 字段建立索引后,mysql扫描索引过程中就能得到0有多少个,1有多少个,就不需要临时表暂存结果了)
- 如果group by的字段不适合建索引,而返回结果又很大时,可以使用SQL_BIG_RESULT关键字让sql直接使用磁盘临时表(因为mysql的机制是先建立内存临时表,当发现结果太大内存临时表存不下时,会建磁盘临时表,直接使用SQL_BIG_RESULT可以避免这个重建过程)
错误使用sql优化
当sql语句显式或隐式的触发了索引字段使用函数,可能破坏索引值的有序性,优化器会放弃使用树搜索功能,下面我们就举几个例子,使用中是需要避免的。
- select count(*) from tradelog where month(t_modified)=7;//统计所有年份七月的数据
这个sql很容易看出问题,t_modified字段使用了函数,优化器会放弃使用树搜索功能 - select * from tradelog where tradeid=110717; //其中tradeid为varchar类型
这个sql有什么问题呢?其实这个sql触发了隐式的函数类型转换,该sql等价于select * from tradelog where CAST(tradid AS signed int) = 110717; 可以看到也使用了函数 - select d.* from tradelog l, trade_detail d where d.tradeid=l.tradeid and l.id=2; //tradelog表tradeid字段是utf8mb4,detail 表的tradeid字段是utf8
这个分析起来稍微难一些,我们解读下执行计划。
- 第 1 步,是根据 id 在 tradelog 表里找到R;
- 第 2 步,是R 中取出 tradeid 字段的值;
- 第 3 步,是根据 tradeid 值到 trade_detail 表中查找条件匹配的行。然后根据主键索引,一个一个地判断 tradeid 的值是否匹配。
但是字符集 utf8mb4 是 utf8 的超集,所以当这两个类型的字符串在做比较的时候,MySQL会先把 utf8 字符串转成 utf8mb4 字符集,再做比较,所以第三步应该等同于 select * from trade_detail where CONVERT(traideid USING utf8mb4)=R.tradeid.value; 也不能走索引
小结:
上面从三大方面总结了Mysql常见的优化方法,后面有新的再补充进去吧。
参考资料
高性能Mysql
Mysql实战45讲
