

概述
我们还是说InnoDB引擎,我们知道InnoDB 引擎有个buffer pool用于存放数据页,索引页等数据。但内存是有限的,如果内存使用完了,InnoDB是怎么处理的呢?我们知道LRU(Least recently used 最近最少使用 )算法是经典的淘汰算法,我们画下LRU的示例图
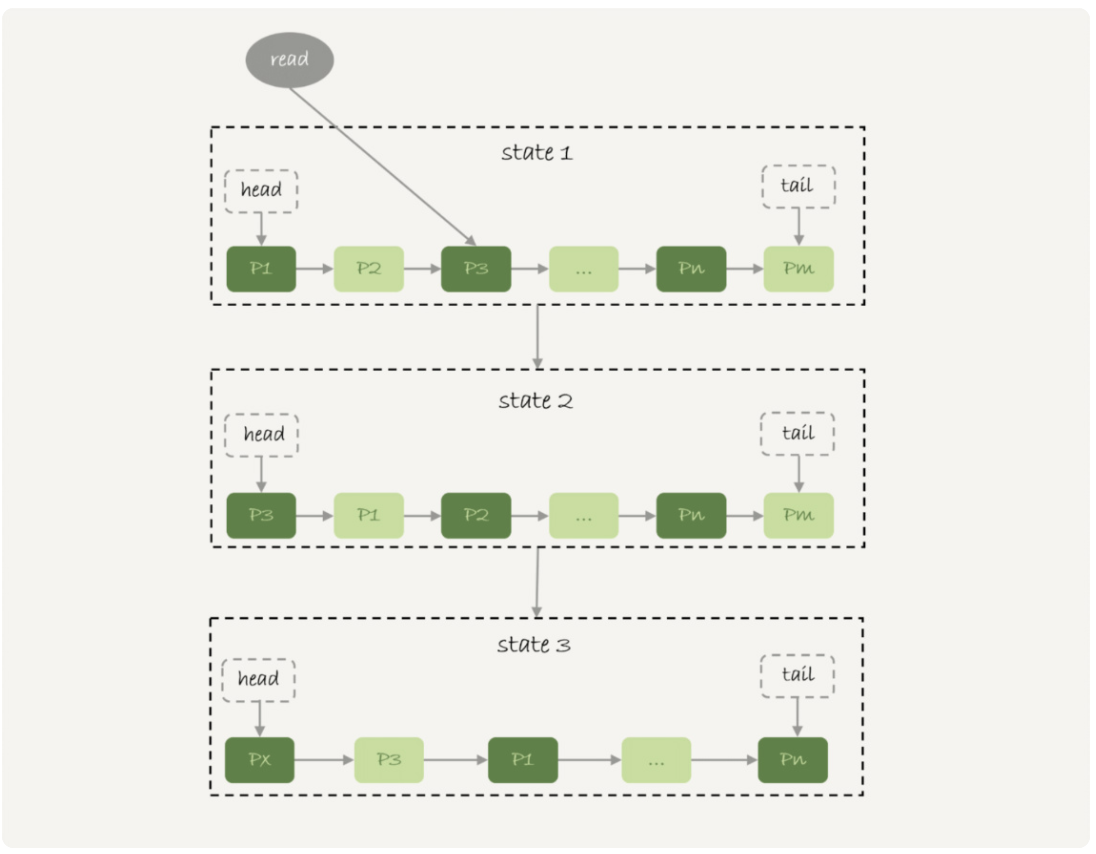
基本的LRU算法有什么问题?
如果使用基本LRU算法,当有一个大表(几十G)进行全表扫描时,是不是把内存中全部缓存的数据淘汰了,我们知道在机械硬盘时代,读内存比读磁盘快一万倍,这时如果进行其他表的查询必须读取磁盘,速度就会很慢,非常影响mysql的性能。(正常我们线上如果想保证mysql有比较好的性能,内存命中率应该在90%以上)
解决办法
为了解决基本LRU算法的问题,InnoDB 使用了优化后的LRU算法,该算法使用分区域存放。
InnoDB中的LRU算法
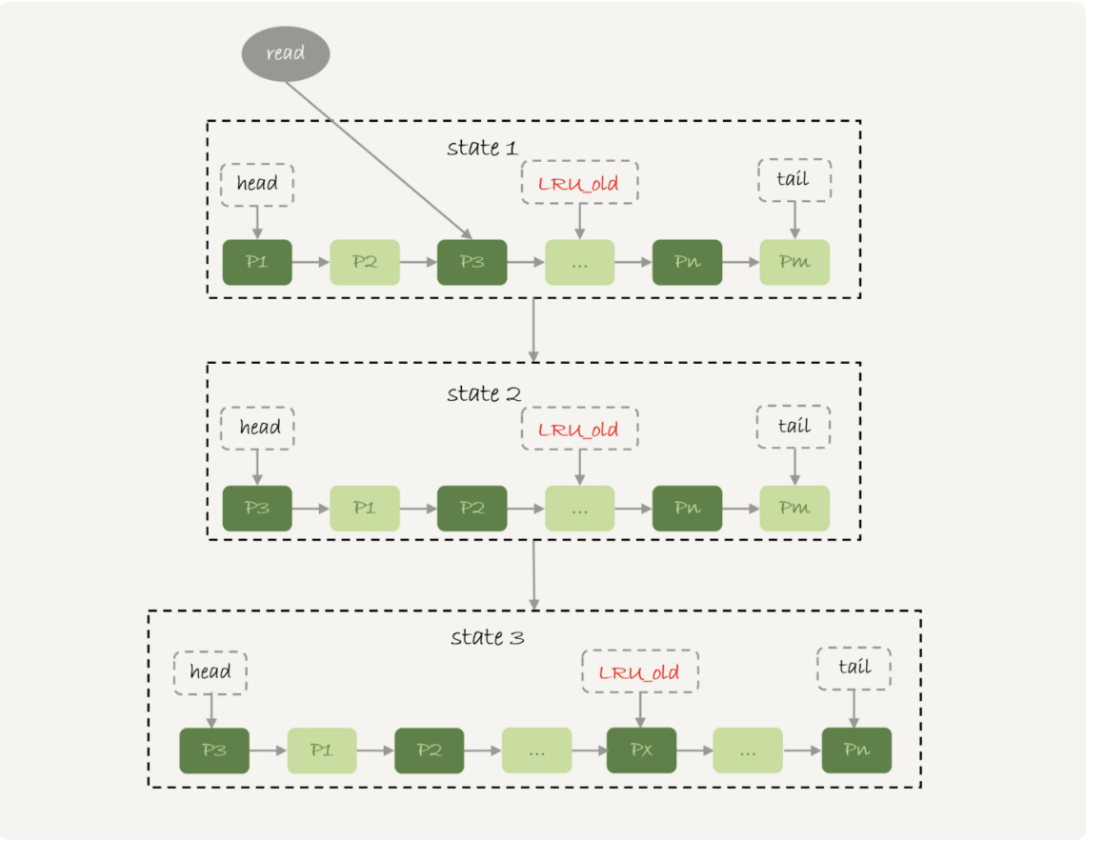
从磁盘中新读入的数据页先放在old区的表头,并且在1秒钟内(可以用innodb_old_blocks_time配置),再次读取也还是放在old区,只有存活超过1秒后,再次读取才会移动到young区域的表头。
所以即使是全表扫描,也只会影响old区域,从而保证InnoDB有较高的内存命中率
参考资料
- 高性能Mysql
- MySQL实战45讲
