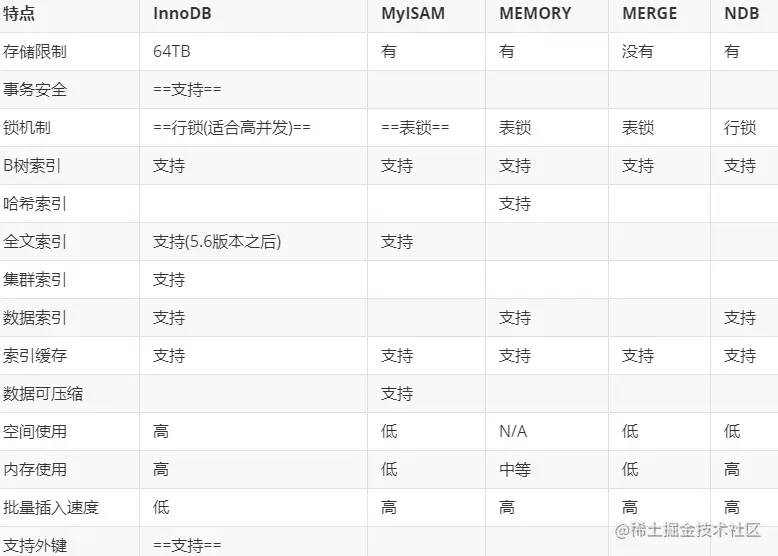
a.MySql存储引擎
b.索引
1.首先有很多的引擎
2.每种引擎支持的索引又不一样
3.需要了解的mysql的engine是innodb
4.innodb中需要了解的索引是btree索引 当然innodb还有全文索引
5.btree索引介绍开始
a.单列索引(主键索引,唯一索引,普通索引)和组合索引.
a.1单列索引:
一个索引只包含一个列,一个表可以有多个单列索引.
a.1.1普通索引:
CREATE INDEX account_Index ON `award`(`account`);
ALTER TABLE award ADD INDEX account_Index(`account`)
a.1.2唯一索引:
唯一索引,与普通索引类似,但是不同的是唯一索引要求所有的类的值是唯一的,这一点和
主键索引一样.但是他允许有空值,
CREATE UNIQUE INDEX account_UNIQUE_Index ON `ward`(`account`);
a.1.3主键索引:
主键索引,不允许有空值,(在B+TREE中的InnoDB引擎中,主键索引起到了至关重要的地位)
主键索引建立的规则是 int优于varchar
a.2组合索引(联合索引,组合索引):
切记:联合索引 ≠ 两个索引,它也是一个索引 可以理解为:单列索引,是一个特殊的联合索引
一个组合索引包含两个或两个以上的列,一个表中含有多个单列索引不代表是组合索引,通俗
一点讲组合索引是:包含多个字段但是只有索引名称
复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按
名字中有相同姓氏的人进行排序。如果您知道姓,电话簿将非常有用;如果您知道姓和,名
字电话簿则更为有用,但如果您只知道名不知道姓,电话簿将没有用处。
a.2.1普通索引:
CREATE INDEX nickname_account_createdTime_Index ON
`award`(`nickname`,`account`, `created_time`);
如果你建立了组合索引(nickname_account_createdTime_Index) 那么他实际包含的是3个
索引 (nickname) (nickname,account)(nickname,account,created_time)
a.3覆盖索引:尽量使用覆盖索引(只访问索引的查询(索引列完全包含查询列)),减少select * 。
联合索引的存在,就引出了覆盖索引的概念。
如果查询列可通过索引节点中的关键字直接返回,则该索引就称之为覆盖索引。覆盖索引的
出现,可减少数据库的 I/O 操作,将随机 I/O 变为 顺序 I/O,从而提高查询性能。
6.索引失效的情况
6.1:离散性差,离散性越高,选择性就会越好,查询效率显然也会越高,索引的存在也就起到了作用。
6.2:in 走索引,not in 索引失效;尽量使用复合索引,而少使用单列索引。
6.3: 当你使用group by 语句时他已经给你排序了。建议,当数据很大的时候,写group by时,
对数据的顺序不关心时,加上一个order by null减少排序的操作
7. 什么时候走单列索引,什么时候走联合索引,以及它们的关联区别,这位博主写的听清楚的。
请参考https:
1.一致性的理解
ACID里的AID都是数据库的特征,也就是依赖数据库的具体实现.而唯独这个C,实际
上它依赖于应用层,也就是依赖于开发者.这里的一致性是指系统从一个正确的状
态,迁移到另一个正确的状态.什么叫正确的状态呢?就是当前的状态满足预定的约
束就叫做正确的状态.而事务具备ACID里C的特性是说通过事务的AID来保证我们的
一致性.
https://www.zhihu.com/question/31346392引用知乎文章
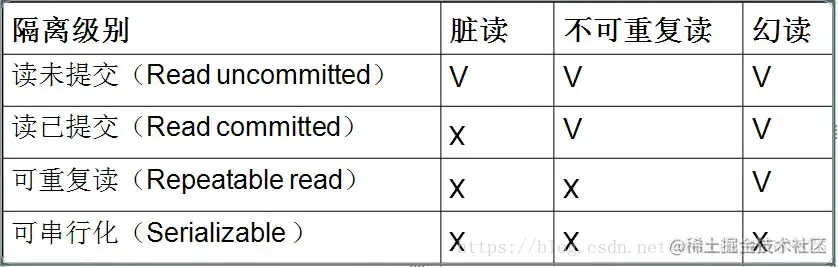
2.脏读 不可重复读 幻读
转至
https:
3.不可重复读和幻读的区别
不可重复读是指读取了已经提交的事务的修改数据,幻读是指读到了其他事务已
经提交的新增和删除数据,对于这两种问题的解决采用不同的方法,防止读到更
改的数据,只需对操作的数据添加行级锁,防止操作中数据的变化;而防止幻读
到新增或删除数据,往往需要添加表级锁,将整张表锁定,防止新增和删除数据
4.事务隔离级别
直接使用锁机制管理是很复杂的,基于锁机制,数据库为用户提供了事务隔离级
别只要设置了事务隔离级别,数据库会分析事务的sql语句自动选择合适的锁事务
隔离级别对应的解决问题,不同的事务隔离级别的执行效率是不一样的,选择合
适自己的就好
原子性是通过undolog、一致性是终极目标、隔离性是通过锁和mvcc、持久性是通过redolog
6.redis实现一小时内用户最多只能登陆5次
使用list 数据
7. 三范式
数据往往种类繁多,而且每种数据之间又互相关联,因此,在设计数据库时,
所需要满足的范式越多,那表的层次及结构也就越复杂,最终造成数据的处理
困难。这样,还不如不满足这些范式呢。所以在使用范式的时候也要细细斟酌
,是否一定要使用该范式,必须根据实际情况做出选择。一般情况下,我们使
用前三个范式已经够用了,不再使用更多范式,就能完成对数据的优化,达到
最优效果。
8.char和varchar
char的长度是不可变的,而varchar的长度是可变的,也就是说,定义一个
char[10]和varchar[10],如果存进去的是‘csdn’,那么char所占的长度
依然为10,除了字符‘csdn’外,后面跟六个空格,而varchar就立马把长度变
为4了,取数据的时候,char类型的要用trim()去掉多余的空格,而varchar是不需要的。
尽管如此,char的存取速度还是要比varchar要快得多,因为其长度固定,方
便程序的存储与查找;但是char也为此付出的是空间的代价,因为其长度固定
,所以难免会有多余的空格占位符占据空间,可谓是以空间换取时间效率,而
varchar是以空间效率为首位的。
一般用 char 类型的 存放 固定的数据 如 身份证号(18) 电话号 性别
用varchar 存放可变的数据 这个就太多了 。。。。
9.mvcc和undo、redo

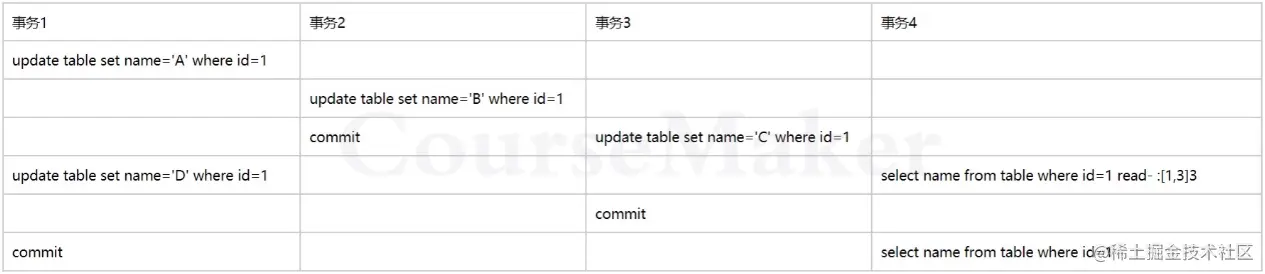
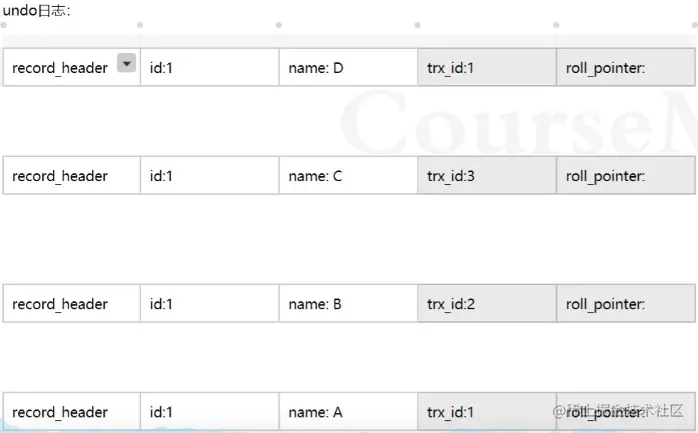
从最新一条记录开始查找:trx_id: 1-->trx_id:3-->trx_id:2-->trx_id:1



