

对于一个从java转golang的开发者而言,数组和切片是最容易弄晕的地方。往往傻傻的分不清数组和切片的区别。
其实这两个数据结构从底层的实现来说并没有什么差异,只是数组是不可变化的(这里不可变化并不是说其是常量),而切片是可变的。
-
数组
-
数组的声明
数组的声明格式中必须指定数组的长度,而且指定之后长度就不可以变化,而且不能像java中一样数组的长度使用一个变量填充
声明的格式是:
var identifier [len]type例如:
var arr1 [5]int以为数组是一种值类型,除了这种声明方式以外还可以使用new()函数来声明
var arr1 = new([5]int) 。 -
数组的内存结构
数组在内存的结构是:
有一点要注意的是,在go中如果声明一个数组的时候没有给他初始化,那么他会将每个元素都初始化为零,此时如果打印arr1 其值为[0,0,0,0,0]
因为数组是值类型,所以在使用数组作为函数的参数的时候,函数会拷贝整个数组生成一个副本。所以如果为了效率考虑,可以传递数组的地址,或者直接使用切片作为参数。
-
数组的循环方式
数组循环的方式有两种,第一种是for循环,
for i:=0; i < len(arr1); i++{ arr1[i] = ... }第二种是for-range循环
// index为数组的索引,value为索引对应的值 for index,value:= range arr1 { ... } -
数组初始化
第一种:
var arrAge = [5]int{18, 20, 15, 22, 16}第二种:
var arrLazy = [...]int{5, 6, 7, 8, 22}... 可同样可以忽略,从技术上说它们其实变化成了切片。 第三种: key: value
var arrKeyValue = [5]string{3: "Chris", 4: "Ron"}这种赋值方法直接指定了数组所在的索引,所以只有索引 3 和 4 被赋予实际的值,其他元素都被设置为空的字符串,所以输出结果为:
Person at 0 is Person at 1 is Person at 2 is Person at 3 is Chris Person at 4 is Ron
-
-
切片
- 切片是数组的一个引用,因此切片是引用类型,在进行传递时,遵守引用类型的传递机制。
- 切片的使用和数组类似,遍历切片,访问切片的元素和求切片的长度
len(slice)都是一样。 - 切片的长度是可以变化的。因此是一个动态变化的数组。
-
创建切片
-
普通声明不初始化
声明切片的格式是: var slice []type (不需要说明长度)。 一个切片在未初始化之前默认为 nil,长度为 0,此时的切片虽然声明但是不可使用
-
使用make初始化
// 初始化一个长度为5容量为5的切片 [0,0,0,0,0] var slice = make([]int,5,5) // 初始化一个长度为5容量为5的切片 [0,0,0,0,0] var slice = make([]int,5) -
使用数组或者切片初始化一个切片
var arr = [5]int{1,2,3,4,5} // 初始化一个切片,切片的值从数组的下标1开始到2结束(不包括2) var slice = arr[1:2] // 从数组下标n开始到m结束(不包括m),也可以使用切片赋值切片 var slice = arr[n,m] -
切片的遍历
切片的遍历和数组一致
-
切片的内存模型
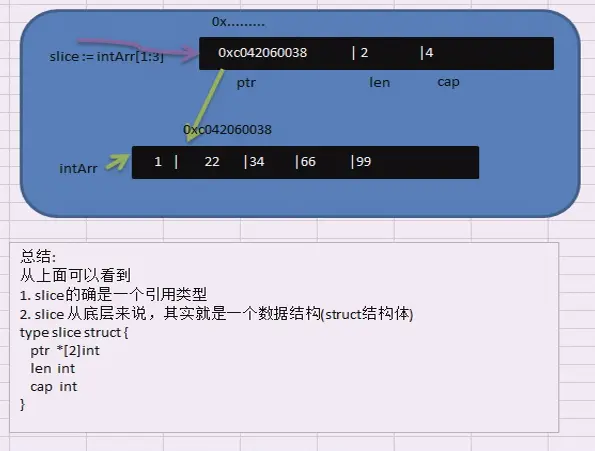
-
切片的扩容、拷贝和删除
切片增加内容有点像Java中的ArrayList,ArrayList使用他本身的add方法进行增加,而切片则是使用一个函数叫做append。
var slice = make([]int,5,5) // 向切片中添加一个10 slice = append(slice,10)当添加的长度超过容量的时候,那么这个时候切片就要开始扩容了,这个扩容的方法是append自带的一种检查扩容机制,就像List的add方法中检查grow一样
那么切片是怎么扩容的呢?
- 首先,需要判断新申请的容量是否大于2倍旧的容量,如果大于,则最终容量就是新申请的容量
- 否则判断,切片的长度是否小于1024,小于则最终容量就是旧容量的两倍;否则最终容量在旧容量的基础上循环增加原来的1/4,直到最终容量大于等于新申请的容量
- 如果最终容量计算值溢出,则最终容量就是新申请的容量
需要注意的是,切片扩容会根据切片元素中的不容类型做不容的处理,而且每次切片扩容之后其实是产生一个新的切片,将旧有的切片复制到新的中这种处理和ArrayList的扩容方式是一样的
如下,这是源码中有关扩容策略的一部分源码,此处只包含了见到那的扩容策略,源码中还包含了其他的处理,源码位置:src/runtime/slice.go
newcap := old.cap doublecap := newcap + newcap if cap > doublecap { newcap = cap } else { if old.len < 1024 { newcap = doublecap } else { // Check 0 < newcap to detect overflow // and prevent an infinite loop. for 0 < newcap && newcap < cap { newcap += newcap / 4 } // Set newcap to the requested cap when // the newcap calculation overflowed. if newcap <= 0 { newcap = cap } } }拷贝一个切片到另外一个切片可以使用copy()函数,copy函数将返回成功复制的元素的个数,等于两个slice中较小的长度,所以我们不用担心覆盖会超出目标切片的范围。
slice1:=[]int{1,2,3,4,5} slice2:=[]int{5,4,3} //只会复制slice1的前3个元素到slice2中 copy(slice2,slice1) //只会复制slice2的3个元素到slice1的前3个位置 copy(slice1,slice2)copy函数的第一个参数是要复制的目标切片,第二个参数是源切片,两个slice可以共享同一个底层数组,甚至有重叠也没有问题。
切片没有删除方法,所以如果想要删除切片就需要使用我们上面说的使用数组或者切片初始化一个切片
-
-
new()和make()的区别
看起来二者没有什么区别,都在堆上分配内存,但是它们的行为不同,适用于不同的类型。 new(T) 为每个新的类型T分配一片内存,初始化为 0 并且返回类型为*T的内存地址。这种方法 返回一 个指向类型为 T,值为 0 的地址的指针,它适用于值类型如数组和结构体。 make(T) 返回一个类型为 T 的初始值,它只适用于3种内建的引用类型:切片、map 和 channel。
所以new()只是开辟了一个内存,如果不是基本类型那么这个类型并不能直接使用;而make()会初开辟一个内存并初始化。
