

B+树
- 每一个索引在InnDB里面对应一颗B+树。
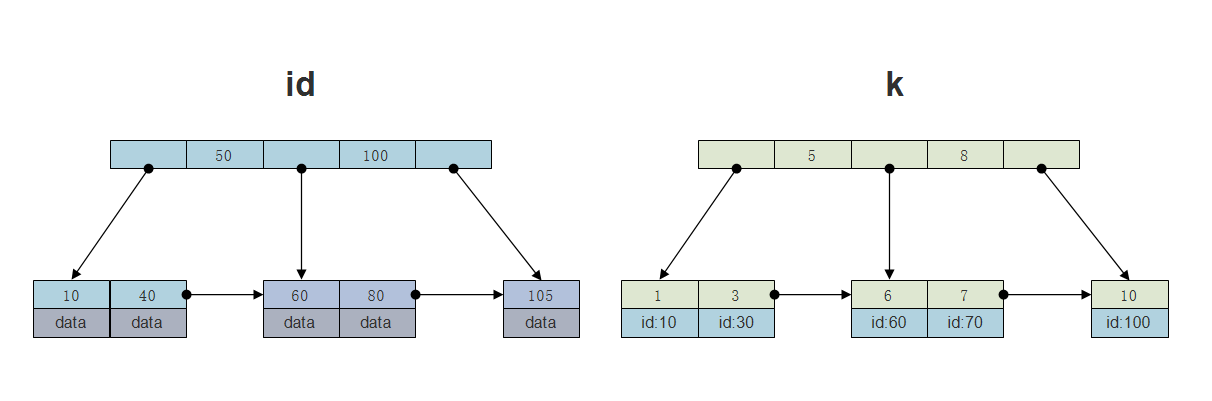
- 场景:表t有主键列为id,字段k,在k上建立索引。
索引类型
- 主键索引:也称为聚簇索引(clustered index),叶子节点存储的是整行数据。
- 普通索引:也称为二级索引(secondary index),叶子节点存储的是主键的值。
索引维护
- 页分裂:当一个数据页满插入数据时,根据B+树的算法会新增一个数据页,然后挪动部分数据到新的数据页。性能和数据页的利用率会受到影响。
- 页合并:当相邻两个数据页删除部分数据,利用率很低时,会将这两个数据页合并。
主键的选择
- 自增主键
- 插入新数据可以不指定id的值,系统会获取当前id最大值+1作为插入数据的id值。
- 由于每次是追加操作,不需要挪动数据,即不会触发页分裂。
- 从性能的考虑,一般情况下使用自增主键。
- 适合使用业务字段做主键的条件
- 查询业务只需要一个索引
- 索引必须是唯一索引
覆盖索引
回表:需要从k索引树回到id索引树的过程。
- 如果一个索引包含所有需要查询的字段的值,称为覆盖索引。
- 场景:表t有主键id,字段name, age,在name上建立索引。
- select id from t where name = '小明',name索引树可以得到id的值,不需要回表,属于覆盖索引。
- select name, age from t where name='小明',age的结果需要回到id索引树搜索,不属于覆盖索引,可通过创建索引(name, age)优化。(name, age)就是联合索引。
- explain结果集的Extra列可以检查是否用到覆盖索引。

最左前缀原则
- 最左前缀可以是联合索引的最左N个字段,也可以是字符串索引的最左M个字符。
- 联合索引字段顺序选择
- 通过调整顺序,可以少维护一个索引,这个顺序优先考虑采用。如果有了(name, age)联合索引,一般不需要再单独为name建立索引了。
索引下推
- MySQL5.6引入了索引下推优化(index condition pushdown)
- 可以在普通索引树遍历的时候,对索引的字段先做判断,直接过滤不满足条件的记录,减少了回表次数。
- 场景:select * from users where name = 'jack' and age=10,联合索引(name, age)
- 无索引下推:普通索引树搜索到的每条记录都需要回到主键索引树,并不会在普通索引树过滤age条件不满足的记录。
- 索引下推:普通索引树搜索到的每条记录都会过滤age条件不满足的记录,再回到主键索引树取数据。
字符串加索引的方式
完整索引
- 优点
- 可以减少扫描索引树的次数和回表次数。
- 缺点
- 可能会造成空间占用过大。
前缀索引
- 优点
- 可以节省空间。如果定义好长度(预估好前缀的区分度),可以减少额外的查询成本。
- 缺点
- 可能会造成额外的扫描次数和回表次数。
- 无法使用覆盖索引。
- 不支持范围查询。
倒序存储 + 前缀索引
- 在字符串前缀的区分度不够的场景可以考虑使用。
hash字段索引
- 表增加一个int类型字段存储某字符串的hash值。
- 优点
- 减少存储的空间。
- 缺点
- 额外的存储和计算消耗。
- 不支持范围查询。
根据实际的业务场景选择合适的字符串加索引的方式。
参考
极客时间《MySQL实战45讲》
