

- python版本2.x和python3.x
- 文件申明和字符编码
# !usr/bin/env python # ! -*- coding: utf-8 -*- - 判断语句
# 以下采用python3的写法 import getpass name = input("请输入用户名:") # 可见的密码输入 pwd = input("请输入密码:") # 不可见的密码输入 pwd = getpass.getpass("请输入密码:") if name == "xinmin" and pwd = "123": print("yes") else: print("no")- tips:and 关键字表示并且,or表示或者, 多条件时用
if-elif-else表示
- tips:and 关键字表示并且,or表示或者, 多条件时用
- while循环
# 从1显示到10 start = 1 flag = True while flag: print(start) if start = 10: flag = False strat += 1 print("end")- tips:注意此处True与False首字母均是大写
# 从1显示到10 start = 1 flag = True while flag: print(start) if start = 10: break strat += 1 print("end")- tips:break关键字可以跳出循环,不再执行下面的代码;continue关键字,下面的代码不执行,又重新开始循环。
# 从1显示到10,不输出7 start = 1 flag = True while flag: if start == 7: start += 1 continue print(start) if start = 10: break strat += 1 print("end")- 编码与解码
# -*- coding:utf-8 -*- # python2.x中使用 temp = "张三" # 解码需要指定原来是什么编码 temp_unicode = temp.decode("utf-8") print(temp_unicode) # temp_gbk = temp_unicode.encode("gbk") # print(temp_gbk) # windows终端需要gbk - 算数运算符
+、-、*、/、%、**、//:加、减、乘、除、模(取余数)、幂、取整除- python3.x与python2.x的区别
- py2: 9/2 = 4 ,导入模块
form _future import division则可以解决 - py3:9/2 = 4.5
- py2: 9/2 = 4 ,导入模块
- 其他运算符
==、!=(<>)、>=、<=:关系运算符in、not in:成员运算符,返回true或false`and、or、not:逻辑运算符
- 新增的基本数据类型
- 列表:list
- 元组:tuple
- 查看对象的类,或对象所具备的功能
# 查看所具有的方法 temp = "xinmin" print(dir(temp)) # 查看具体的方法实现 help(type(temp)) - int 的内置方法常用
bit_length:获取数字表示成二进制的最短位数n = 4 ret = n.bit_length() print(ret) # 100 - 字符串(str)常用方法
- capitalize():首字母变大写
n = "xinmin" ret = n.capitalize() print(ret) # Xinmin - center():内容居中
n = "xinmin" # 居中两边用_填充 ret = n.center(20, '_') print(ret) # _______xinmin_______ - count():统计字母出现的次数
n = "xinmin" ret = n.count('i') print(ret) # 2 # 0-3位置中i出现的次数 res = n.count('i', 0, 3) print(res) # 1 - endswith():判断是否已某个字母结尾
n = "xinmin" ret = n.endswith('n') print(ret) # True # 获取0-4不包含4位置是否i结尾 res = n.count('i', 0, 4) print(res) # False - expandtabs():把tab间转换成空格键
n = "xinmin\t110" print(n) ret = n.expandtabs() print(n) - find():找对应的字母返回下标,包含多个时返回第一个的下标,没有找到返回-1
n = "xinmin" ret = n.find('i') print(n) # 1 - format():格式化字符串
s = "hello {0}, age {1}" new1 = s.format('xinmin', 19) print(new1) # hello xinmin, age 19 - index():同find(),没找到报错,所以选择用find()
- join():连接
# list集合,元组也支持 li = ("xin", "min") li = ["xin","min"] # 字符串以下划线连接 s = "_".join(li) print(s) # xin_min - lstrip():去左边空格
- rstrip():去右边空格
- strip():去左右两边空格
- partition():替换
s = "xinmin is NB" ret = s.partition('is') print(ret) # ('xinmin ', 'is', ' NB') 元组类型 - replace():替换
- swapcase():大写变小写,小写变大写
- upper():小写变大写
- capitalize():首字母变大写
- str的索引与切片
s = "xinmin" # 索引 print(s[0]) # x print(s[1]) # i print(s[2]) # n # 长度 ret = len(s) print(ret) # 6 # 切片 0=< 0,1,2,3 <= 4 print(s[0:4]) # xinm # for循环,break,continue仍适用 for item in s: print(item) # while 循环 start = 0 while start < len(s) temp = s[start] print(temp) start += 1 - list 列表
- 创建列表
name_list = ['zhangsan', 'lisi', 'wangwu'] print(name_list) # 索引 print(name_list[0]) # 切片 print(name_list[0:2]) # len 2<=x<3 print(name_list[2:len(name_list)]) # ['wangwu'] # for 循环 for i in name_list: print(i) - 内置方法
- append:追加
name_list = ['zhangsan', 'lisi', 'wangwu'] name_list.append('seven') name_list.append('seven') name_list.append('seven') print(name_list) print(name_list.count('seven')) # 3 count统计元素出现次数 - extend:扩展
temp = [111, 22, 33] name_list.extend(temp) # ['zhangsan', 'lisi', 'wangwu', 'seven', 'seven', 'seven', 111, 22, 33] print(name_list) - index:获取索引
print(name_list.index('wangwu')) # 2 - insert:插入
name_list.insert(1, ' NB') print(name_list) - pop:移除尾部的元素(并拿到尾部元素可赋值给其它变量)
# 拿到尾部的33赋值给a1 a1 = name_list.pop() print(a1) # 33 - remove:移除某个元素(只移除从左边找到的第一个,移除多个需要多次执行)
- sort:排序
del name_list(1):删除索引为1的元素del name_list(1:3):删除索引为1到3的元素(1<=x<3)
- append:追加
- 创建列表
- tuple元组
- 基本用法与list一样,但是不能修改
name_tuple = ('zhangsan', 'lisi') # 索引 print(name_tuple[0]) # 切片 print(name_tuple[0:1]) # len print(name_tuple[len(name_tuple)-1]) # for 循环 for i in name_tuple: print(i) - 其它用法
del name_tuple[0]:不支持- count:计算元素出现的个数
print(name_tuple.count('lisi')) # 1 - index:获取指定元素的索引位置
print(name_tuple.index('zhangsan')) # 0
- 基本用法与list一样,但是不能修改
- dict字典:每个元素都是键值对
- 基本用法
user_info = { "name": "zhangsan", "age": 19, "gender": "M" } # 索引 print(user_info["name"]) # zhangsan # 无切片 # for循环,默认输出key for i in user_info: print(i) # 获取所有的 key print(user_info.keys()) # dict_keys(['name', 'age', 'gender']) # 获取所有的value print(user_info.values()) # dict_values(['zhangsan', 18, 'M']) # 获取所有的键值对 print(user_info.items()) # dict_items([('name', 'zhangsan'), ('age', 18), ('gender', 'M')]) # 获取所有的key for i in user_info.keys(): print(i) # 获取所有的value for i in user_info.values(): print(i) # 获取所有的键值对 for (k, v) in user_info.items(): print(k) print(v) - 其它用法
- clear:清除所有内容
user_info.clear() print(user_info) # {} - get:根据key获取值,如果key不存在,可指定一个默认值
val = user_info.get('age') print(val) # 19 val2 = user_info.get('age2', '20') print(val2) # 20 # 索引也可取值,不存在时报错,推荐使用get - has_key:python3中没有了,检测字典中指定的key是否存在
# 可用关键字in来解决 ret = 'age' in user_info.keys() print(ret) - update:更新
test = { "a1": 123, "a2": 456 } # 追加到尾部 user_info.update(test) print(user_info) - pop:删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出, 否则,返回default值
test = { "a1": 123, "a2": 456 } ret = test.pop('a1') print(ret) # 123 - popitem:随机返回并删除字典中的一对键和值
test = { "a1": 123, "a2": 456 } ret = test.popitem() print(ret) # ('a2', 456) print(test) # {'a1': 123} del test['a1']:删除指定索引的键值对
- clear:清除所有内容
- 基本用法
- 其他功能
-
enumerate:自动生成一列,默认0自增1
li = ["电脑", "鼠标垫", "U盘", "键盘"] for key,item in enumerate(li, 1): print(key,item) inp = input("请输入商品:") # 默认输入的是str,int()强制装换 print(li[int(inp)-1]) -
range:py2.7用来获取指定范围的数,range(0,100000),xrange,用来获取指定范围的数,xrange,循环时才创建,py3中range相当于xrange
print(range(1,10)) # range(1, 10) for i in range(1,10, 2): print(i) # 1 3 5 7 9 -
内容补充
- int:
n1 = 123:根据int类,创建了一个对象(找__init__方法执行)n2 = int(123):根据int类,创建了一个对象n1 = 123,n2 = 123:在Python内部进行了优化,-5~257之间,相同的数使用同一块内存- 用int,32位机器范围:
-2**31~2**31,64位范围:-2**63~2**63 - long长整型,根据内存可无限大
- str
- s1 = "xinmin":根据str类,创建一个对象
- s2 = str(xinmin):根据str类,创建一个对象
- 常用方法(特有的)
# 两端去空格 s1.strip() # 还有rstrip() 、lstrip() s = "xinmin " news = s.strip() # 会生成新的字符串,原来的空格还存在 # 以···开头 s1.startwith() # 还有endwith() # 找子序列 (一个字符或多个字符) s1.find() # 将字符串中某个子序列替换成指定值 s1.replace() # 变大写 s1.upper() # 是···吗? s1.isalpha() - 公共方法
# 索引,只能取1个元素 s1 = 'xinmin' print(s1[2]) # n # 切片,可以取多个 print(s1[2:3]) # n # for python3.5 ===> 字符 # len python3.5 ===> 字符 - UTF-8编码,一个汉字3个字节,一个字节8位
- GBK编码,一个汉字2个字节
- bytes():把字符串转换成字节
name = "张三" for i in name: print(i) bytes_list = bytes(i, encoding='utf-8') print(bytes_list) # 默认每个字节用16进制表示 for b in bytes_list: print(b) # 默认每一个字节都是10进制表示 # 结果如下: """ 张 b'\xe5\xbc\xa0' 229 188 160 三 b'\xe4\xb8\x89' 228 184 137 """ - 补充
name = str("张三") # 1.创建字符串 n = str(m, encoding='utf-8') # 2.字节转换成字符串 m = bytes(name, encoding='utf-8') # 1.字符串转换成字节 x = bytes() # 2.创建空字节
-
- list:
- 可变的元素“集合”,列表
# 1.创建列表的两种方法 li = [11,22,33,44] li = list([11,22,33,44]) # 2.转换 name = "张三" l1 = list(name) print(l1) # ["张", "三"] # 元组转换成list t2 = ("zhangsan", "lisi", "wangwu") l2 = list(t2) print(l2) # 字典转换成list,默认转换Key, 还可以转换values,items dic = {"k1": "zhangsan", "k2": "lisi"} l3 = list(dic.items()) print(l3) # [('k1': 'zhangsan'), ('k2': 'lisi')] - 特有方法
li = list() # 追加 li.append() # 清除 li.clear() # 扩展,用另外一个可迭代的对象扩充自己 # 可迭代的有 str,list,dict,tuple li.extend() # 翻转,自己内部元素翻转 li.reverse() # 向指定的位置插入 li.insert(2, "X") - 公共方法
li = ["zs", "ls", "ww", "six", 123] # 索引 print(li[2]) # 'ww' # 切片 print(li[2:3]) # ["ww"] # for len
- tuple
- 创建和转换
t = (11,22,33) t = tuple((11,22,33)) t = tuple({}) # 可迭代的参数 字符串、列表、字典 - 特有方法
count index - 嵌套(元素不可修改)
t = (11,22,33) t = (11,22,["张三", {"k1": "v1"}]) t[2][1]['k1'] # 'v1' - 元组的特性,子元素不可被修改,子元素的子元素可以被修改
t = (11,22,["张三", {"k1": "v1"}]) t[2].append("xxxx") print(t)
- 创建和转换
- dict
- 创建
a = {"k1": 123} a = dict(k1=123, k2=456) li = [11,22,33] new_dict = dict(enumerate(li)) print(new_dict) - 特有方法
formkeys # 不常用 # 添加方式 a.update({"k2": 123}) a["k1"] = 123
- 创建
- set
- 不允许重复,无序的元素集合
# 创建 2 种方式 s = set() s = {11,22,33,44} # 转换 s = set([11,22,33,11,22]) # [11,22,33] # 添加一个元素 s = set() s.add(11) print(s) # {11} # 清空 s.clear() # difference找到不同的赋值给新的变量 s1 = {11,22,33} s2 = {22,55} ret = s1.difference(s2) #s1存在,s2不存在的 print(ret) # {11,33} # difference_update 找到不同的更新自己 res = s2.difference_update(s1) print(s2) # {55} print(res) # None # 移除 se = {11, 22, 33} discard(44) # 不报错 remove(44) # 报错 print(se) # 交集(不更新原来的) s1 = {11, 22, 33} s2 = {22, 92, "haha"} ret = s1.inrersection(s2) # intersection_update() 更新原来的 # 有交集False,无交集True # isdisjoint() 是否有交集 se = {11, 22, 33, 44} be = {11, 22} ret = se.issubset(be) #False 是否子序列 res = se.issupset(be) # True 是否父序列
- 不允许重复,无序的元素集合
- 三元运算
name = 值1 if 条件 else 值2:条件成立,为值1,条件不成为值2name = 'zs' if 1 == 1 else 'lisi' # zs
- 深浅拷贝
- 数字和字符串
数字与str的深浅拷贝内存地址与源数据都是一样(python内部的优化机制)
import copy n1 = 123 n2 = copy.copy(n1) print(id(n1)) print(id(n2)) - dict与list
深拷贝
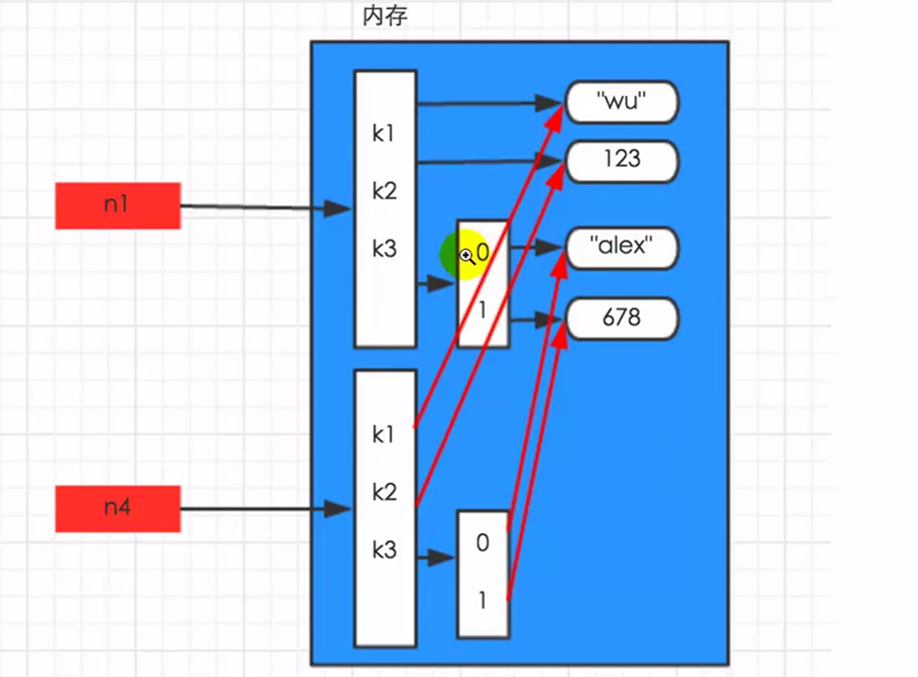
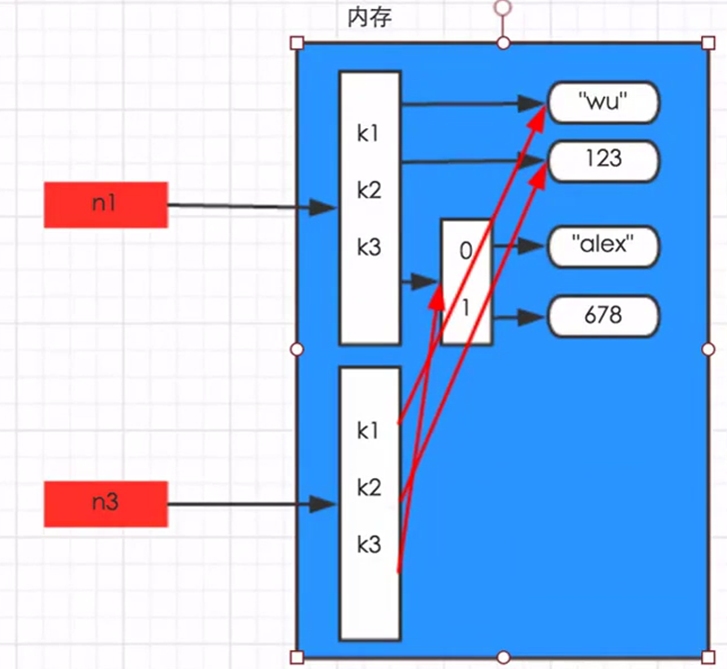
- 数字和字符串
数字与str的深浅拷贝内存地址与源数据都是一样(python内部的优化机制)
