

大家好,我是 yes。
这是我的第三篇Kafka源码分析文章,前两篇讲了日志段的读写和二分算法在kafka索引上的应用
今天来讲讲 Kafka Broker端处理请求的全流程,剖析下底层的网络通信是如何实现的、Reactor在kafka上的应用。
再说说社区为何在2.3版本将请求类型划分成两大类,又是如何实现两类请求处理的优先级。 #叨叨 不过在进入今天主题之前我想先叨叨几句,就源码这个事儿,不同人有不同的看法。
有些人听到源码这两个词就被吓到了,这么多代码怎么看。奔进去就像无头苍蝇,一路断点跟下来,跳来跳去,算了拜拜了您嘞。
而有些人觉得源码有啥用,看了和没看一样,看了也用不上。
其实上面两种想法我都有过,哈哈哈。那为什么我会开始看Kafka源码呢?
其实就是我有个同事在自学go,然后想用go写个消息队列,在画架构图的时候就来问我,这消息队列好像有点东西啊,消息收发,元数据管理,消息如何持久一堆问题过来,我直呼顶不住。
这市面上Kafka、RocketMQ都是现成的方案,于是乎我就看起了源码。
所以促使我看源码的初始动力,竟然是为了在同事前面装逼!!
我是先看了RocketMQ,因为毕竟是Java写的,而Kafka Broker都是scala写的。
梳理了一波RocketMQ之后,我又想看看Kafka是怎么做的,于是乎我又看起了Kafka。
在源码分析之前我先总结性的说了说Kafka底层的通信模型。应对面试官询问Kafka请求全过程已经够了。
Reactor模式
在扯到Kafka之前我们先来说说Reactor模式,基本上只要是底层的高性能网络通信就离不开Reactor模式。像Netty、Redis都是使用Reactor模式。
像我们以前刚学网络编程的时候以下代码可是非常的熟悉,新来一个请求,要么在当前线程直接处理了,要么新起一个线程处理。

在早期这样的编程是没问题的,但是随着互联网的快速发展,单线程处理不过来,也不能充分的利用计算机资源。
而每个请求都新起一个线程去处理,资源的要求就太高了,并且创建线程也是一个重操作。
说到这有人想到了,那搞个线程池不就完事了嘛,还要啥Reactor。
池化技术确实能缓解资源的问题,但是池子是有限的,池子里的一个线程不还是得候着某个连接,等待指示嘛。现在的互联网时代早已突破C10K了。
因此引入的IO多路复用,由一个线程来监视一堆连接,同步等待一个或多个IO事件的到来,然后将事件分发给对应的Handler处理,这就叫Reactor模式。
网络通信模型的发展如下
单线程 => 多线程 => 线程池 => Reactor模型
Kafka所采用的Reactor模型如下
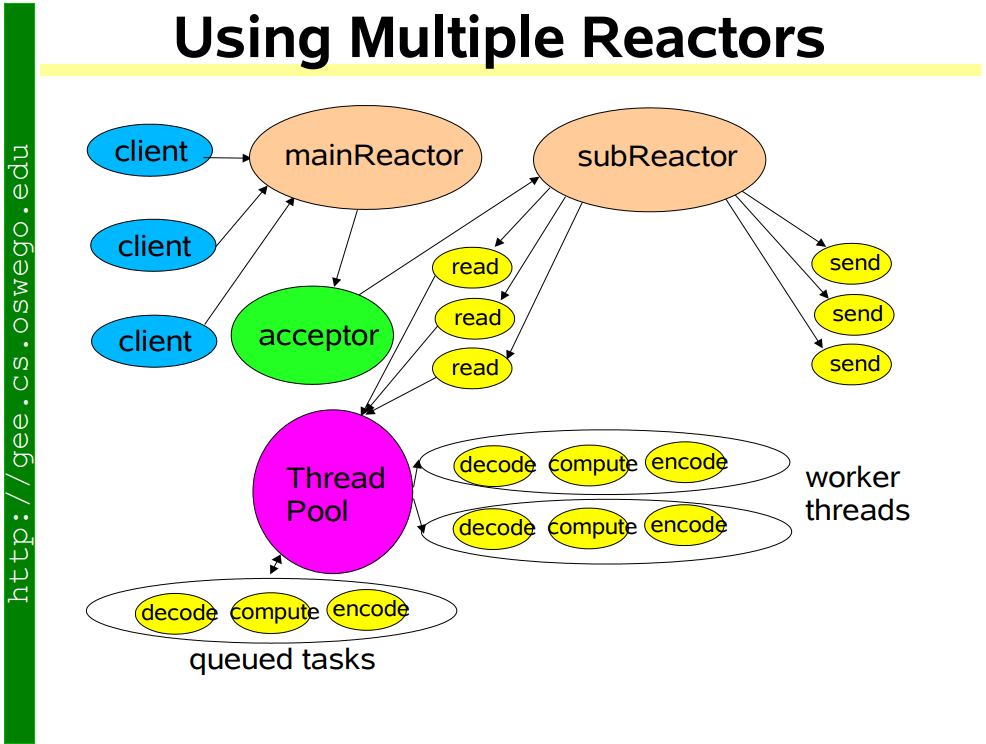
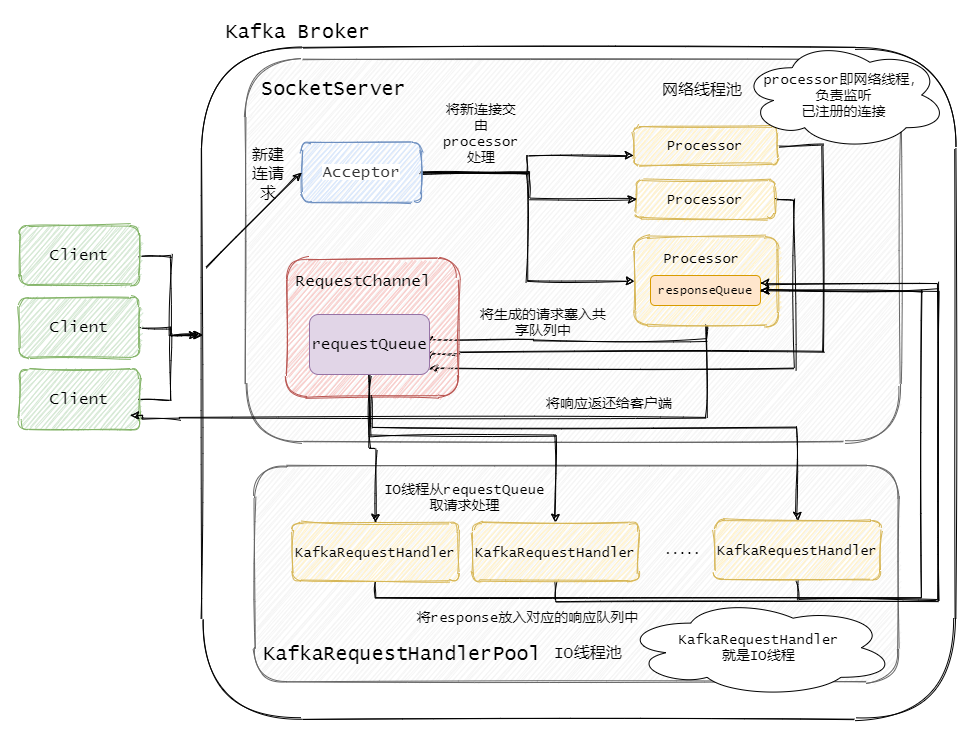
Kafka Broker 网络通信模型
简单来说就是,Broker 中有个Acceptor(mainReactor)监听新连接的到来,与新连接建连之后轮询选择一个Processor(subReactor)管理这个连接。
而Processor会监听其管理的连接,当事件到达之后,读取封装成Request,并将Request放入共享请求队列中。
然后IO线程池不断的从该队列中取出请求,执行真正的处理。处理完之后将响应发送到对应的Processor的响应队列中,然后由Processor将Response返还给客户端。
每个listener只有一个Acceptor线程,因为它只是作为新连接建连再分发,没有过多的逻辑,很轻量,一个足矣。
Processor 在Kafka中称之为网络线程,默认网络线程池有3个线程,对应的参数是num.network.threads。并且可以根据实际的业务动态增减。
还有个 IO 线程池,即KafkaRequestHandlerPool,执行真正的处理,对应的参数是num.io.threads,默认值是 8。IO线程处理完之后会将Response放入对应的Processor中,由Processor将响应返还给客户端。
可以看到网络线程和IO线程之间利用的经典的生产者 - 消费者模式,不论是用于处理Request的共享请求队列,还是IO处理完返回的Response。
这样的好处是什么?生产者和消费者之间解耦了,可以对生产者或者消费者做独立的变更和扩展。并且可以平衡两者的处理能力,例如消费不过来了,我多加些IO线程。
如果你看过其他中间件源码,你会发现生产者-消费者模式真的是太常见了,所以面试题经常会有手写一波生产者-消费者。
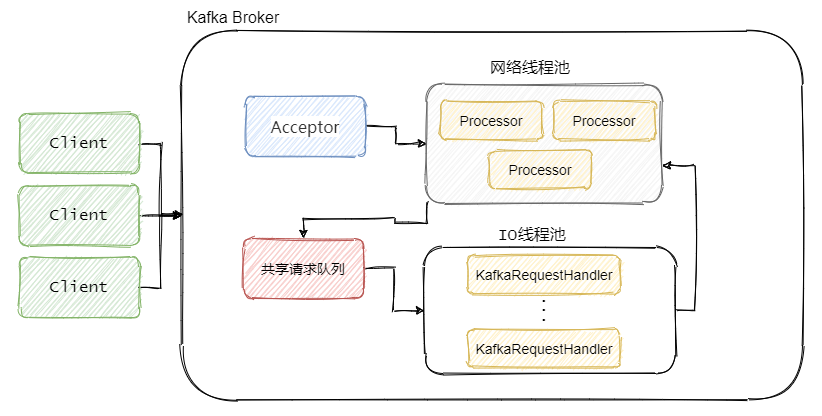
源码级别剖析网络通信模型
Kafka 网络通信组件主要由两大部分构成:SocketServer 和 KafkaRequestHandlerPool。
##SocketServer
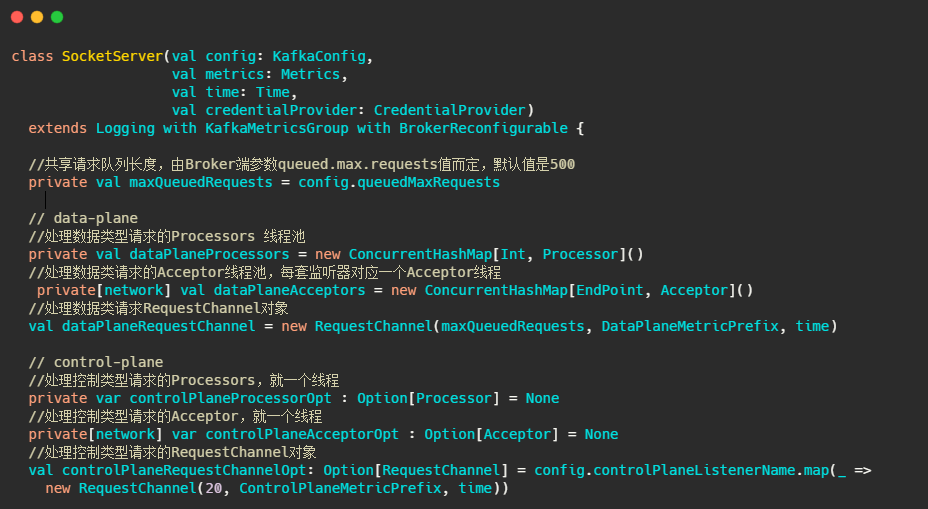
SocketServer旗下管理着,Acceptor 线程、Processor 线程和 RequestChannel等对象。
data-plane和control-plane稍后再做分析,先看看RequestChannel是什么。
RequestChannel
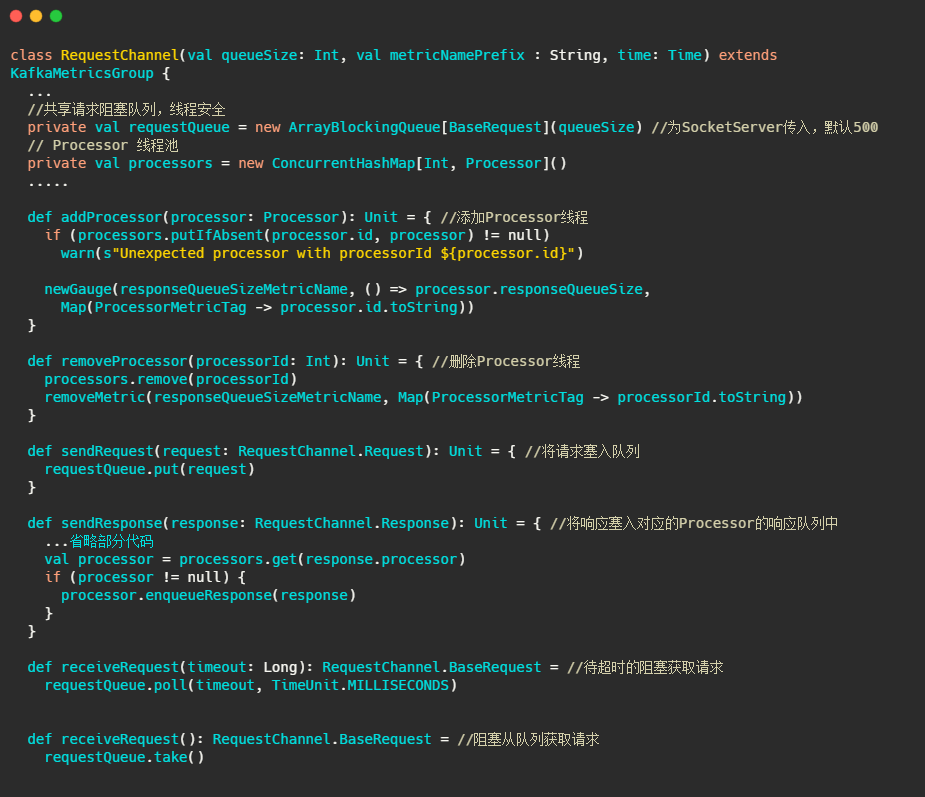
Processor和作为传输Request和Response的中转站。
##Acceptor
接下来我们再看看Acceptor
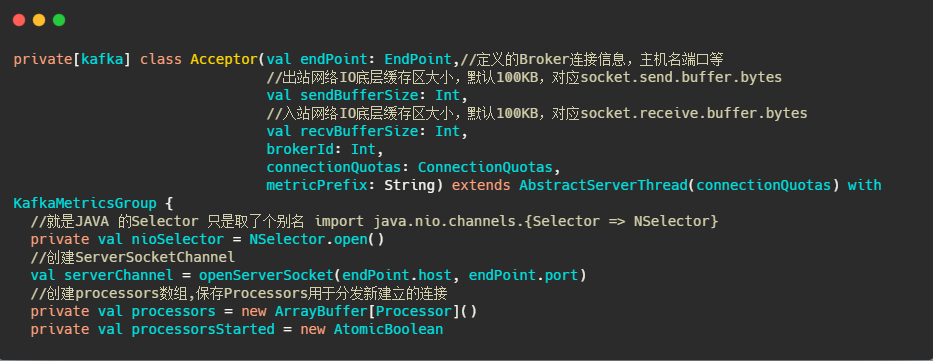
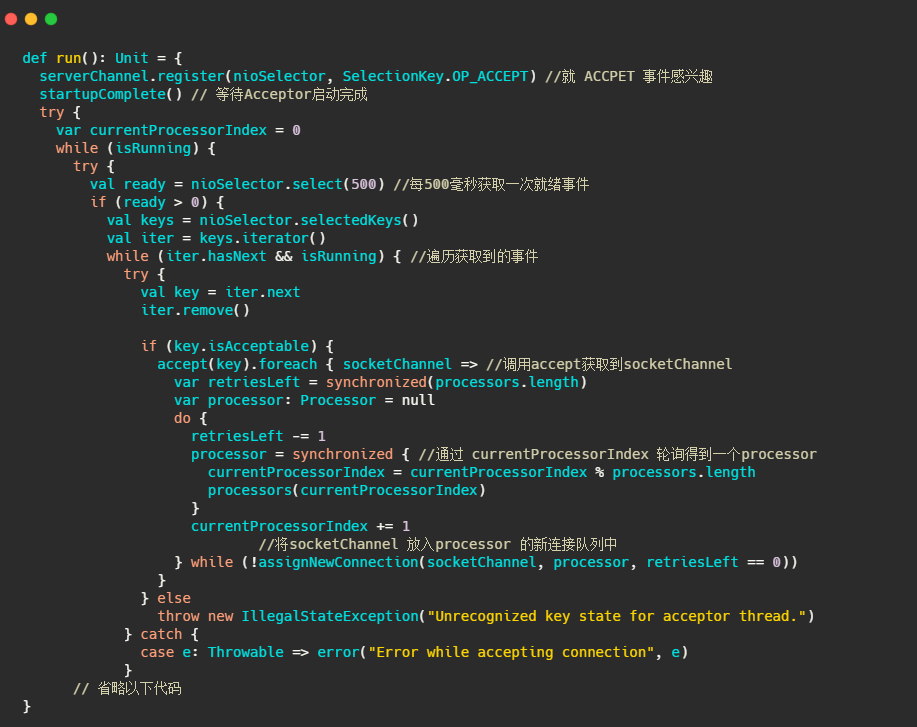
可以看到它继承了AbstractServerThread,接下来再看看它run些啥
accept(key) 做了啥
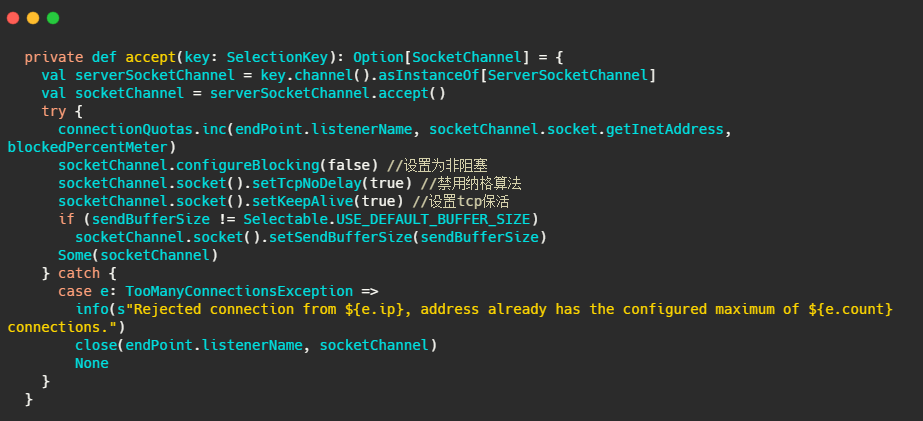
很简单,标准selector的处理,获取准备就绪事件,调用serverSocketChannel.accept()得到socketChannel,将socketChannel交给通过轮询选择出来的Processor,之后由它来处理IO事件。
##Processor
接下来我们再看看Processor,相对而言比Acceptor 复杂一些。
先来看看三个关键的成员

再来看看主要的处理逻辑。
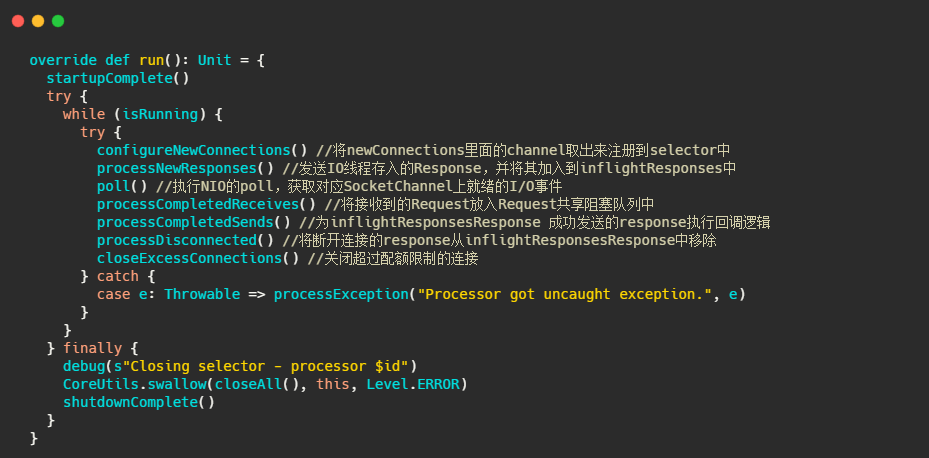
可以看到Processor主要是将底层读事件IO数据封装成Request存入队列中,然后将IO线程塞入的Response,返还给客户端,并处理Response 的回调逻辑。
#KafkaRequestHandlerPool
IO线程池,实际处理请求的线程。
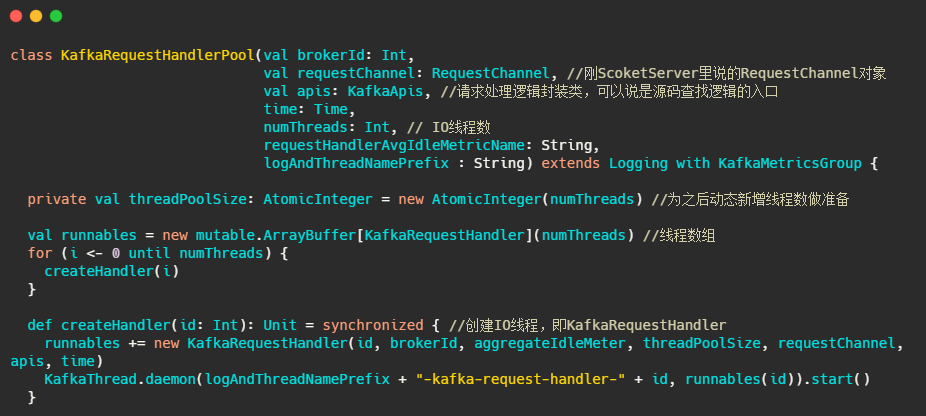
再来看看IO线程都干了些啥
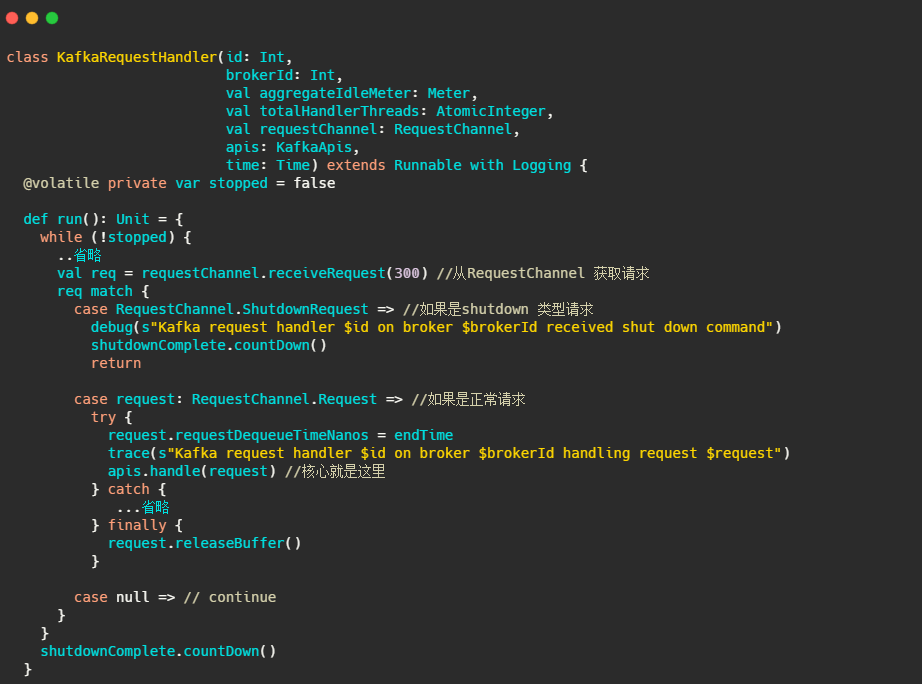
很简单,核心就是不断的从requestChannel拿请求,然后调用handle处理请求。
handle方法是位于KafkaApis类中,可以理解为通过switch,根据请求头里面不同的apikey调用不同的handle来处理请求。
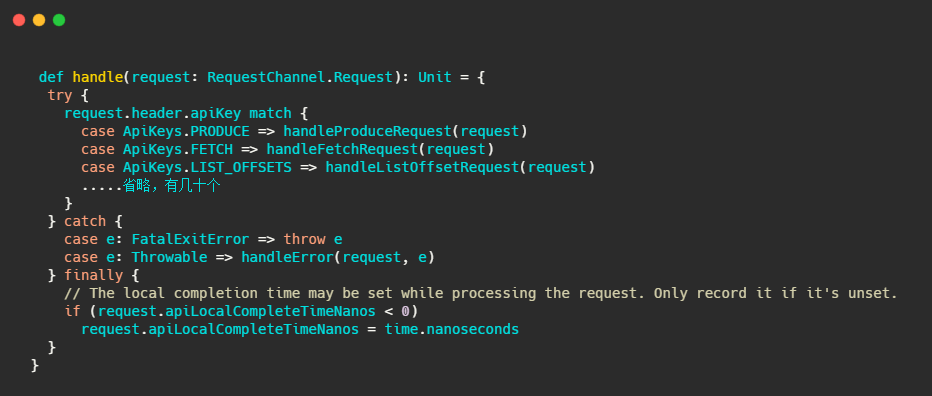
我们再举例看下较为简单的处理LIST_OFFSETS的过程,即handleListOffsetRequest,来完成一个请求的闭环。
我用红色箭头标示了调用链。表明处理完请求之后是塞给对应的Processor的。
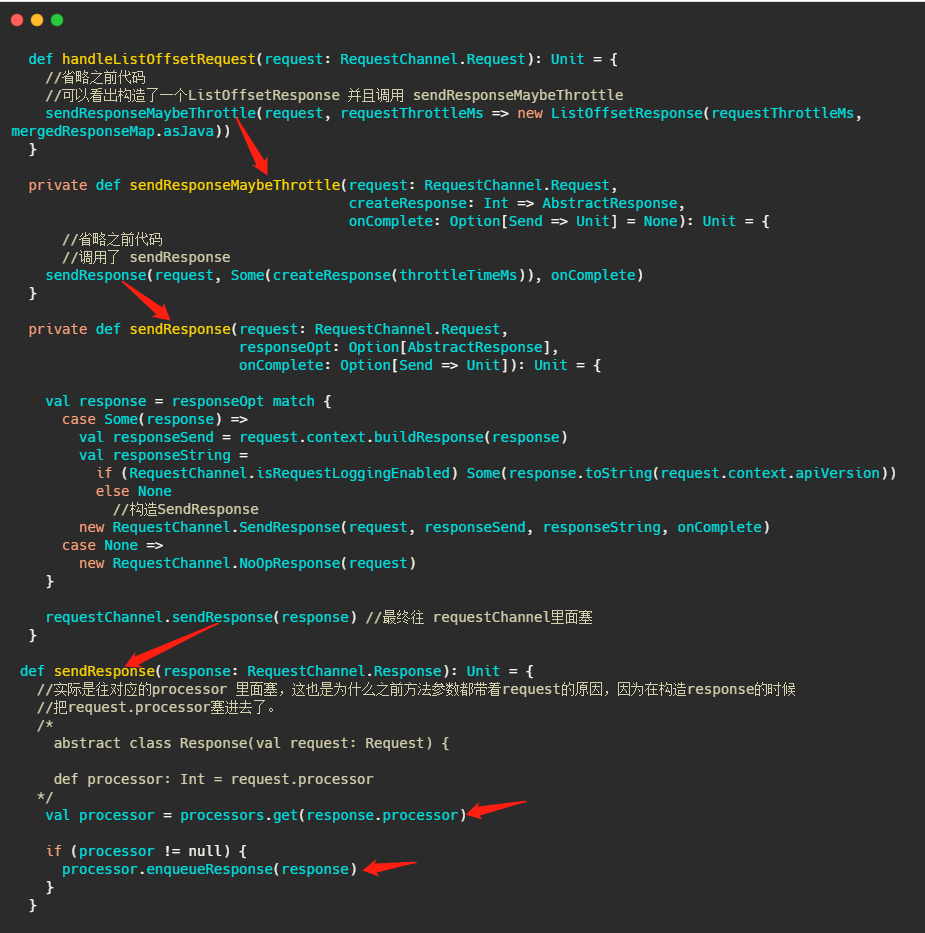
最后再来个更详细的总览图,把源码分析到的类基本上都对应的加上去了。
#请求处理优先级
上面提到的data-plane和control-plane是时候揭开面纱了。这两个对应的就是数据类请求和控制类请求。
为什么需要分两类请求呢?直接在请求里面用key标明请求是要读写数据啊还是更新元数据不就行了吗?
简单点的说比如我们想删除某个topic,我们肯定是想这个topic马上被删除的,而此时producer还一直往这个topic写数据,那这个情况可能是我们的删除请求排在第N个...等前面的写入请求处理好了才轮到删除的请求。实际上前面哪些往这个topic写入的请求都是没用的,平白的消耗资源。
再或者说进行Preferred Leader选举时候,producer将ack设置为all时候,老leader还在等着follower写完数据向他报告呢,谁知follower已经成为了新leader,而通知它leader已经变更的请求由于被一堆数据类型请求堵着呢,老leader就傻傻的在等着,直到超时。
就是为了解决这种情况,社区将请求分为两类。
那如何让控制类的请求优先被处理?优先队列?
社区采取的是两套Listener,即数据类型一个listener,控制类一个listener。
对应的就是我们上面讲的网络通信模型,在kafka中有两套! kafka通过两套监听变相的实现了请求优先级,毕竟数据类型请求肯定很多,控制类肯定少,这样看来控制类肯定比大部分数据类型先被处理!
迂回战术啊。
控制类的和数据类区别就在于,就一个Porcessor线程,并且请求队列写死的长度为20。
最后
看源码主要就是得耐心,耐心跟下去。然后再跳出来看。你会发现不过如此,哈哈哈。

我是yes,一个在互联网摸爬滚打且莫得感情的工具人。

