

主要内容
1. ElasticSearch
1. 概述
我们的应用经常需要添加检索功能,开源的ElasticSearch是目前全文搜索引擎的首选。
他可以快速的存储、搜索和分析海量数据。Spring Boot通过整合Spring Data ElasticSearch
为我们提供了非常便捷的检索功能支持;
Elasticsearch是一个分布式搜索服务,提供Restful API,底层基于Lucene,采用多shard(分片)的方式
保证数据安全,并且提供自动resharding的功能,github等大型的站点也是采用了ElasticSearch作为其搜索服务。
2. 安装ElasticSearch
docker pull elasticsearch
注意: elasticsearch是用Java写的,初始默认堆内存2G的内存,而我的虚拟机只设置了1G。
docker run -e ES_JAVA_OPTS-"-Xms256m -Xmx256m" -d -p 9200:9200 -p 9300:9300 --name elasticS01 5acf0e8da90b
-e 限制内存
在分布式项目中,ElasticSearch各个节点之间的通信用的是9300端口
进行web/外部通信使用9200端口
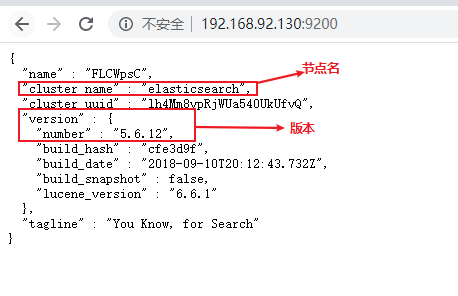
测试一下安装:
发送请求:http://192.168.92.130:9200/
3. 快速入门
3.1 概述
1. 概述
Elasticsearch 是 面向文档 的,意味着它存储整个对象或 文档。
我们对文档进行索引、检索、排序和过滤,而不是对行列数据。
Elasticsearch 使用 JavaScript Object Notation(或者 JSON)作为文档的序列化格式。
下面这个 JSON 文档代表了一个 user 对象:
{
"email": "john@smith.com",
"first_name": "John",
"last_name": "Smith",
"info": {
"bio": "Eco-warrior and defender of the weak",
"age": 25,
"interests": [ "dolphins", "whales" ]
},
"join_date": "2014/05/01"
}
3.2 相关概念
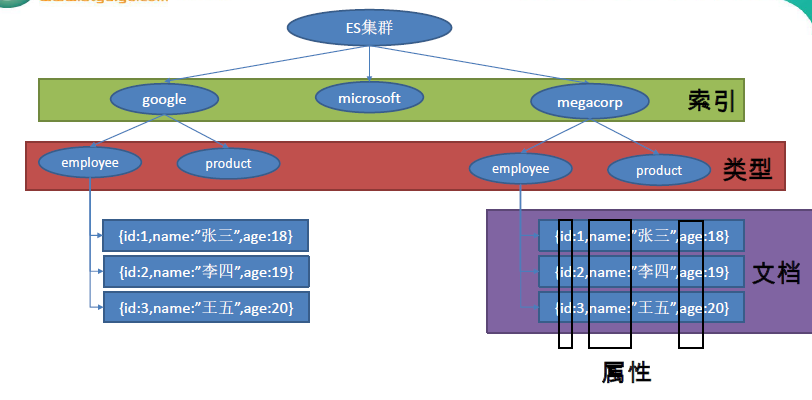
以员工文档的形式存储为例:
一个文档代表一个员工数据。存储数据到ElasticSearch 的行为叫做索引(动词),但在索引一个文档之前,
需要确定将文档存储在哪里。
一个ElasticSearch 集群可以包含多个索引(名词),相应的每个索引可以包含多个类型。
这些不同的类型存储着多个文档,每个文档又有多个属性。
类似关系:
–索引-数据库
–类型-表
–文档-表中的记录
–属性-列
分析图:
例子:对于员工目录,我们将做如下操作
每个员工索引(动词)一个文档,文档包含该员工的所有信息。
每个文档都将是 employee 类型(表) 。
该类型位于 索引 megacorp(库) 内。
该索引(库)保存在我们的 Elasticsearch 集群中。

3.3 索引(动词)员工文档
1. 我们用Postman给ElasticSerach发送请求,索引(动词,PUT)几个员工文档
PUT http://192.168.92.130:9200/megacorp/employee/1
PUT http://192.168.92.130:9200/megacorp/employee/2
PUT http://192.168.92.130:9200/megacorp/employee/3

发送成功,获得响应

PUT也有更新文档的功能

PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
PUT /megacorp/employee/2
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
PUT /megacorp/employee/3
{
"first_name" : "Douglas",
"last_name" : "Fir",
"age" : 35,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}
2. 检索(获取GET)文档
GET http://192.168.92.130:9200/megacorp/employee/1
GET http://192.168.92.130:9200/megacorp/employee/2
GET http://192.168.92.130:9200/megacorp/employee/3

4. HEAD方式:检查是否有这个文档

没有响应,当状态码是200即说明存在该文档。
没有该文档:404

5. DELETE方式:删除该文档
"result": "deleted",

删除之后:再发GET尝试
"found": false

3.4 测试更多的搜索功能
1. 直接指定到类型
一个 GET 相当简单,可以直接得到指定的文档。
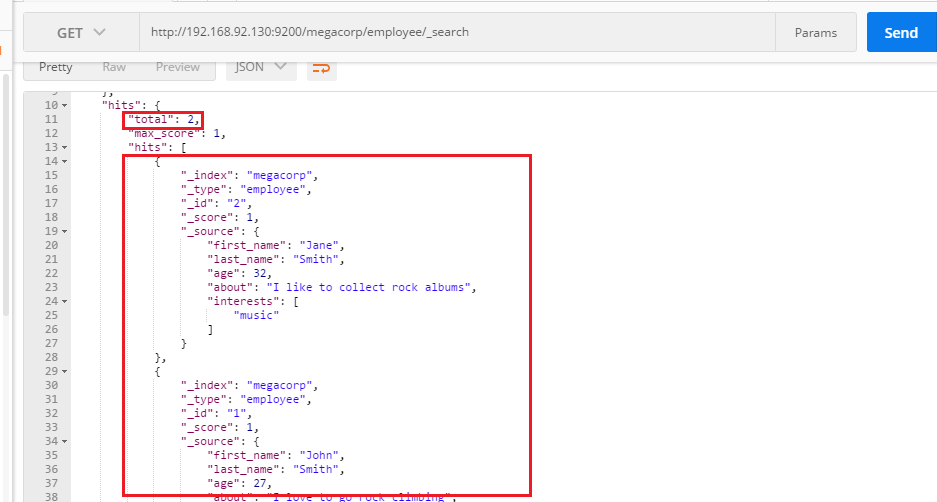
这次我们直接指定到类型:GET /megacorp/employee/_search
http://192.168.92.130:9200/megacorp/employee/_search
返回结果包括了所有二个文档,放在数组 hits 中。一个搜索默认返回十条结果。
{
"took": 226,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 1,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 1,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 27,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
}
]
}
}
2. 按照条件搜索
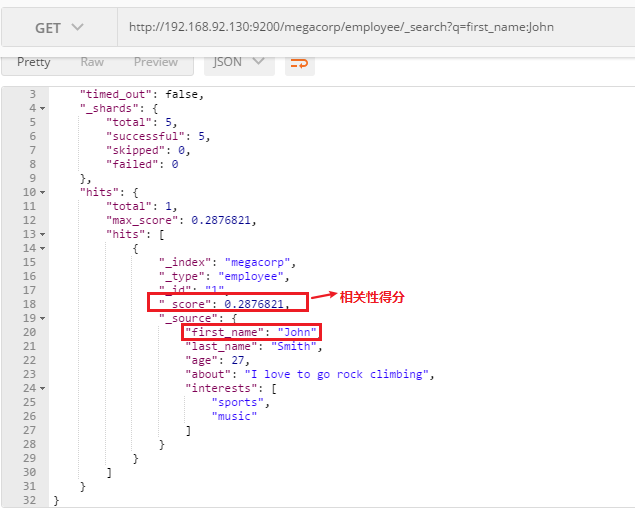
http://192.168.92.130:9200/megacorp/employee/_search?q=first_name:John
搜索first_name=John的文档
3. JSON形似的查询表达式
GET /megacorp/employee/_search
{
"query" : { //查询
"match" : { //规则
"last_name" : "Smith" //具体规则
}
}
}
注意:这是放到请求体中的,GET没有请求体,所以要发POST请求。

结果:

4. 更复杂的查询表达式
POST /megacorp/employee/_search
{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "smith"
}
},
"filter": {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
}
这部分是一个 range 过滤器 , 它能找到年龄大于 30 的文档,其中 gt 表示大于(great than)。
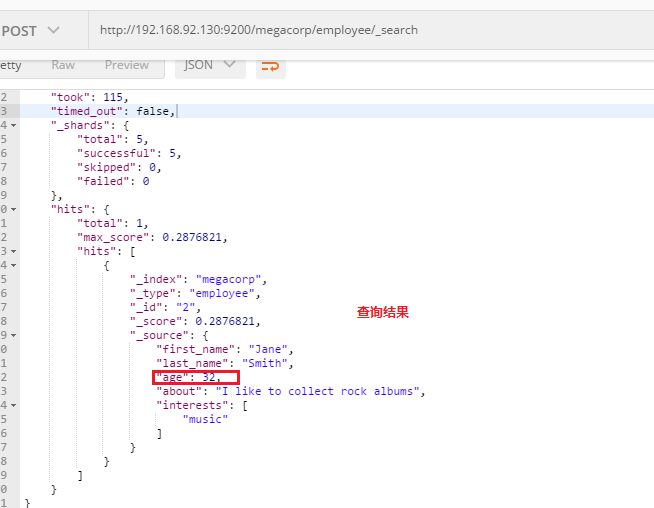
4. 全文搜索:部分匹配
查询员工文档的about属性是能部分匹配:rock climbing的
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}

结果:

5. 短语检索:完全匹配
POST /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}

结果:

6. 高亮搜索
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}

结果:

4. 整合ElasticSearch测试
1. 创建项目

2. 找到所有与ElasticSearch相关的自动配置
SpringBoot默认支持两种技术来和ES交互
1. SpringData ElasticSearch
帮我们自动配置了:
1. Client节点信息:clusterNodes, clusterName
2. ElasticTemplate:操作ElasticSearch
3. 编写一个ElasticsearchRepository的子接口来操作ES。
2. Rest客户端
默认不生效,需要导入rest的工具包
package org.elasticsearch.client;
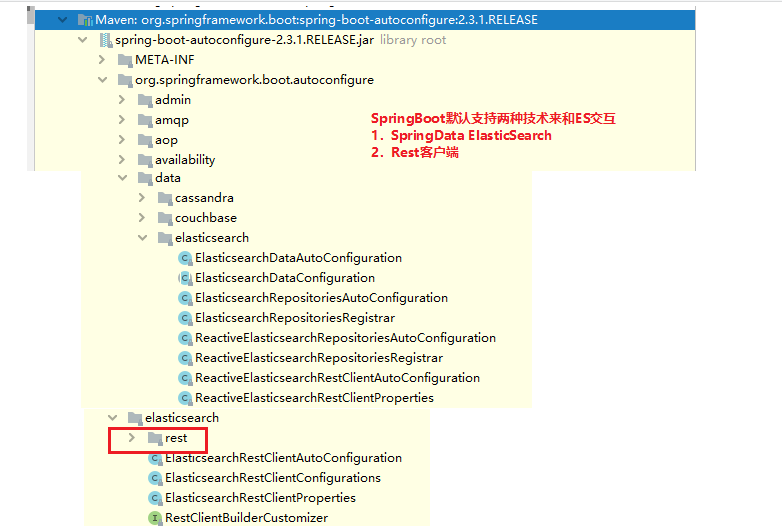
这是SpringData对ElasticSearch的一些自动配置。
4.1. 整合ElasticSearch方式1
Rest客户端交互
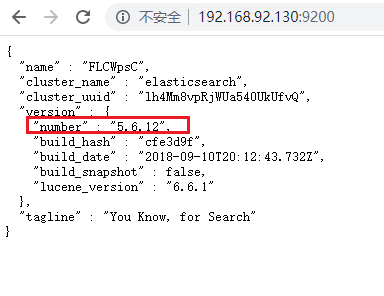
1. 导入Rest依赖
选择:REST High Level
因为ElasticSearch是5.X版本的,所以Rest用5版本的。

注意: High/Low Level 都要导入
Rest客户端整合没弄好,后面在补。
5. 痛苦。
版本差异太大,下次用到这个在针对学一学吧。
整个视频的坑全踩了,就这个没弄,一块疙瘩。
懂得舍弃,不要钻牛角尖...
