

一. 视频编码
1. 原理:
如此大的数据量如果直接进行存储或传输将会遇到很大困难,因此必须采用压缩技术以减少码率。数字化后的视频信号能进行压缩主要依据两个基本条件:
-
数据冗余。例如如空间冗余、时间冗余、结构冗余、信息熵冗余等,即图像的各像素之间存在着很强的相关性。消除这些冗余并不会导致信息损失,属于无损压缩。
-
视觉冗余。人眼的一些特性比如亮度辨别阈值,视觉阈值,对亮度和色度的敏感度不同,使得在编码的时候引入适量的误差,也不会被察觉出来。可以利用人眼的视觉特性,以一定的客观失真换取数据压缩。这种压缩属于有损压缩。
数字视频信号的压缩正是基于上述两种条件,使得视频数据量得以极大的压缩,有利于传输和存储。
一般的数字视频压缩编码方法都是混合编码,即使用三种方式相结合来进行压缩编码。
- 变换编码
- 熵编码
- 运动估计和运动补偿
通常使用变换编码来消去除图像的帧内冗余,用运动估计和运动补偿来去除图像的帧间冗余,用熵编码来进一步提高压缩的效率。
更深入的知识可以参考下面的博客:
视频压缩编码和音频压缩编码的基本原理Java雷霄骅 blog.csdn.net/leixiaohua1…
1.1 冗余的种类
视频具有很强的相关性,即视频中的数据有很大的重复,如我们在电影或者电视剧中,我们可以看到很多时候,都是人物在动,而背景不变,所以背景的数据我们可以只保留一份,达到视频压缩的目的
视频压缩的过程实际上就是去冗余的过程,编码也是去冗余的过程
常见的冗余的种类如下:
- 空间冗余: 图像相邻像素之间有很强的相关性
- 时间冗余: 视频序列的相邻图像之间内容相似
- 编码冗余: 不同像素值出现的概率不同
- 视觉冗余: 人的视觉系统对某些细节不敏感
- 知识冗余: 规律性的结构可由先前知识和背景知识得到
上面提到的三种编码的实际上就是去掉了上面冗余中的几种
2. 压缩编码的方法
我们已经知道了视频的压缩有三种编码的方法,但是他们实现的原理和操作是什么呢?我将在本部分来进行阐述
一般的数字视频压缩编码方法都是混合编码,即将变换编码,运动估计和运动补偿,以及熵编码三种方式相结合来进行压缩编码
通常使用变换编码来消去除图像的帧内冗余,用运动估计和运动补偿来去除图像的帧间冗余,用熵编码来进一步提高压缩的效率
这三种编码的具体分析见下面这个博客
2.1 变换编码
将空间域描述的图像信号变换成频率域,然后对变换后的系数进行编码处理。
一般来说,图像在空间上具有较强的相关性,变换频率域可以实现去除相关与能量集中。
常用的正交变换有离散傅里叶变换,离散余弦变换等等。
2.2 熵编码 (实际上就是去编码冗余)
熵编码是因编码后的平均码长接近信源熵值而得名。
熵编码多用可变字长编码(VLC,Variable Length Coding)实现。
其基本原理是对信源中出现概率大的符号赋予短码,对于出现概率小的符号赋予长码,从而在统计上获得较短的平均码长。
可变字长编码通常有霍夫曼编码、算术编码、游程编码等。
2.3 运动估计,运动补偿和运动表示
运动估计和运动补偿是消除图像序列时间方向相关性的有效手段。
上面介绍的变换编码,熵编码都是在以一帧图像的基础上进行的,通过这些方法可以消除图像内部各像素在空间上的相关性,即去除帧内冗余
实际上图像信号除了空间上的相关性外,还有时间上的相关性。例如对于像新闻联播这种背景静止,画面主体运动较小的数字视频,每一幅画面之间的区别很小,画面之间的相关性很大。
对于这种情况我们没有必要对每一帧图像单独进行编码,而是可以只对相邻视频帧中变化的部分进行编码,从而进一步减小数据量,这方面的工作是由运动估计和运动补偿来实现的。
- 运动估计
将当前的输入图像分割成若干彼此不相重叠的小图像子块,例如一帧图像为1280720,首先将其以网格状形式分成4045个尺寸为1616彼此没有重叠的图像块,然后在前一图像或者后一图像某个搜索窗口的范围内为每一个图像块寻找一个与之最为相似的图像块,这个搜寻的过程叫做运动估计
- 运动补偿
通过计算最相似的图像块与该图像块之间的位置信息,可以得到一个运动矢量。
这样在编码的过程中就可以将当前图像中的块与参考图像运动矢量所指向的最相似的图像块相减,得到一个残差图像块,由于每个残差图像块中的每个像素值都很小,所以在压缩编码中可以获得更高的压缩比。
-
压缩数据类型
由于编码过程中需要使用参考图像来进行运动估计和运动补偿,因此参考图像的选择显得很重要。
一般情况下编码器的将输入的每一帧图像根据其参考图像的不同分成 3 种不同的类型:I(Intra)帧、B(Bidirection prediction)帧、P(Prediction)帧
I 帧只使用本帧内的数据进行编码,在编码过程中它不需要进行运动估计和运动补偿。显然,由于 I 帧没有消除时间方向的相关性,所以压缩比相对不高。
P 帧在编码过程中使用一个前面的 I 帧或 P 帧作为参考图像进行运动补偿,实际上是对当前图像与参考图像的差值进行编码。
B 帧的编码方式与 P 帧相似,惟一不同的地方是在编码过程中它要使用一个前面的 I 帧或 P 帧和一个后面的 I 帧或 P 帧进行预测。由此可见,每一个 P 帧的编码需要利用一帧图像作为参考图像,而 B 帧则需要两帧图像作为参考。相比之下,B 帧比 P 帧拥有更高的压缩比。
I帧是去除空间冗余,P,B是去除时间冗余
2.4 混合编码
上面介绍了视频压缩编码过程中的几个重要的方法。在实际应用中这几个方法不是分离的,通常将它们结合起来使用以达到最好的压缩效果。
下图给出了混合编码(即变换编码 + 运动估计和运动补偿 + 熵编码)的模型。该模型普遍应用于 MPEG1,MPEG2,H.264 等标准中。
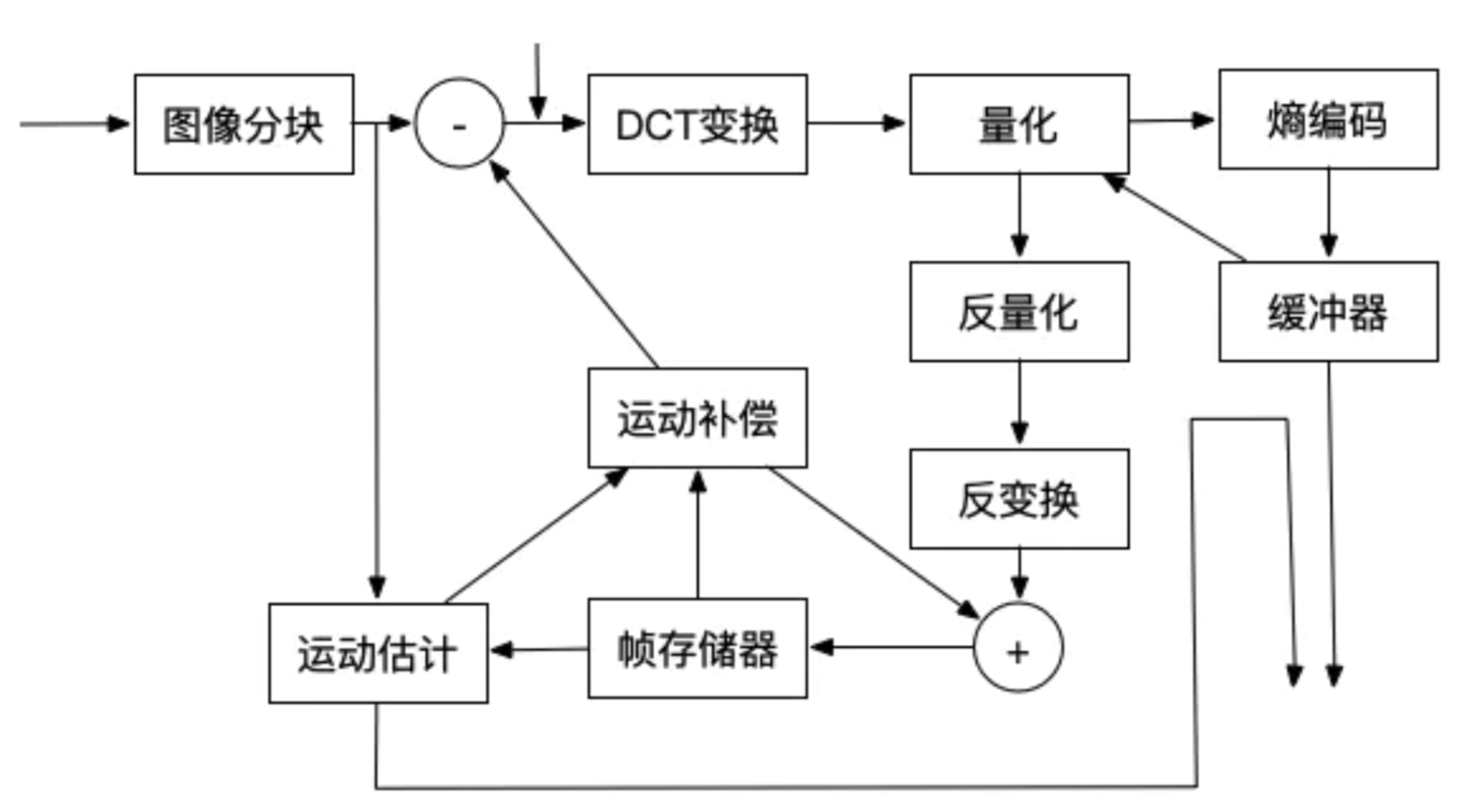
从图中我们可以看到
- 当前输入的图像首先要经过分块,
- 分块得到的图像块要与经过运动补偿的预测图像相减得到差值图像 X,
- 然后对该差值图像块进行 DCT 变换和量化,量化输出的数据有两个不同的去处:
- 一个是送给熵编码器进行编码,编码后的码流输出到一个缓存器中保存,等待传送出去。
- 另一个应用是进行反量化和反变化后的到信号 X’,该信号将与运动补偿输出的图像块相加得到新的预测图像信号,并将新的预测图像块送至帧存储器。
变换编码和熵编码主要是在一帧上进行编码,所以是去空间冗余
运动估计和运动表示是去时间冗余
3. 视频编码器
我们在上面已经知道了视频编码常见的三种编码方法,但是我们不可能完全手动的实现这三种方法,所以有一些现成的工具来帮助我们来进行实现,即视频编码器
视频编码器主要有两种:
-
H.26x,如H.263,H.264
H.264: H.264/AVC 项目的目的是为了创建一个比以前的视频压缩标准,在更低的比特率的情况下依然能够提供良好视频质量的标准(如,一半或者更少于 MPEG-2,H.263, 或者 MPEG-4 Part2 )。同时,还要不会太大的增加设计的复杂性。 优势:
-
网络亲和性,即可适用于各种传输网络
-
比较高的视频压缩比,当初提出的指标是比 H.263,MPEG-4,约为它们的 2 倍
缺点:
- 由于其专利持有者过多,导致其商用费用过高
-
-
VP
VP9 由 Google 研发,可以免费使用。
在实际推广中,微软、苹果等公司不愿看到 VP9 一家独大,其他互联网厂商也不希望主流视频编码格式被垄断,因此目前在主要在 Google 自家的产品中得到支持
5. GOP
GOP指的是两个I帧之间的IPB帧和两个I帧中的前面一个I帧的总和,如 I P B B I PB I 中, I P B B和I P B就是一个GOP
一般来说: GOP 中的IPB帧越多,那么视频质量越好
I 帧存储的是一个完整的图像,P 帧是与前面一个I帧的差值图像,B 帧是与前面和后面的 I 帧,P 帧的差值图像
使用 P 帧,前面必须有一个 I 帧
视频 B 帧,前后必须有 I 帧或者 P 帧
所以,如果有缺失,会导致一些问题:
- 1. 花屏 : GOP 中的 P 帧 或 I 帧 丢失, 会导致解码图像出现错误
- 2. 卡顿 : 为了 防止花屏产生, 如果发现 P 或 I 帧丢失, 那么 整个 GOP 内的帧都不显示, 直到下一个 I 帧到来后显示, 这样就造成了 卡顿;
6. 帧 相关 参数
帧 相关 参数 :
- 1.SPS (Sequence Parameter Set) 序列集参数 :由于其专利持有者过多,导致其商用费用过高,在推广中面临较大阻力 存放内容 ① 帧数 ② 参考帧数目 ③ 解码图像尺寸 ④ 帧场编码模式选择标识 ;
- 2.PPS (Picture Parameter Set) 图像参数集 : 存放内容 : ① 片组数目 ② 初始量化参数 ③ 去方块滤波系数调整标识 ④ 熵编码模式选择标识 ;
更具体的可以参考下面这篇博客
二. 音频编码
我们上面介绍了视频的编码方式,同理,我们也可以对音频来进行编码
1. 时域掩蔽和频域掩蔽
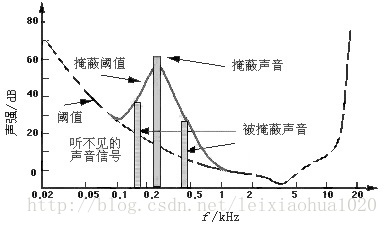
- 频域掩蔽
一个频率的声音能量小于某个阈值之后,人耳就会听不到,这个阈值称为最小可闻阈。当有另外能量较大的声音出现的时候,该声音频率附近的阈值会提高很多,即所谓的掩蔽效应
人耳对2KHz~5KHz的声音最敏感,而对频率太低或太高的声音信号都很迟钝,当有一个频率为0.2KHz、强度为60dB的声音出现时,其附近的阈值提高了很多。
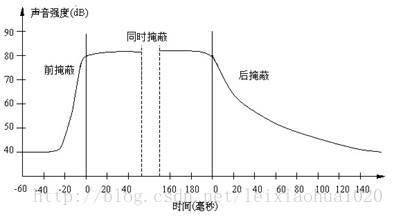
- 时域掩蔽
当强音信号和弱音信号同时出现时,还存在时域掩蔽效应,前掩蔽,同时掩蔽,后掩蔽
- 前掩蔽是指人耳在听到强信号之前的短暂时间内,已经存在的弱信号会被掩蔽而听不到
- 同时掩蔽是指当强信号与弱信号同时存在时,弱信号会被强信号所掩蔽而听不到。
- 后掩蔽是指当强信号消失后,需经过较长的一段时间才能重新听见弱信号,称为后掩蔽。这些被掩蔽的弱信号即可视为冗余信号。
2. 压缩编码
数字音频编码领域存在着不同的编码方案和实现方式, 但基本的编码思路大同小异
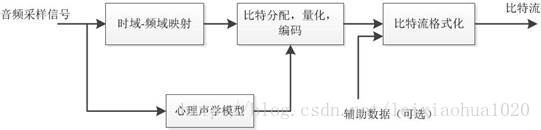
对每一个音频声道中的音频采样信号,
- 首先都要将它们映射到频域中, 这种时域到频域的映射可通过子带滤波器实现。
- 每个声道中的音频采样块首先要根据心理声学模型来计算掩蔽门限值
- 然后由计算出的掩蔽门限值决定从公共比特池中分配给该声道的不同频率域中多少比特数,接着进行量化以及编码工作
- 最后将控制参数及辅助数据加入数据之中,产生编码后的数据流。
3. 编码方式
下面的内容参考自
根据编码方式的不同,音频编码技术分为三种:波形编码、参数编码和混合编码。一般来说,波形编码的话音质量高,但编码速率也很高;参数编码的编码速率很低,产生的合成语音的音质不高;混合编码使用参数编码技术和波形编码技术,编码速率和音质介于它们之间。
1、波形编码
波形编码是指不利用生成音频信号的任何参数,直接将时间域信号变换为数字代码,使重构的语音波形尽可能地与原始语音信号的波形形状保持一致
波形编码的基本原理是在时间轴上对模拟语音信号按一定的速率抽样,然后将幅度样本分层量化,并用代码表示,简单来说就是使用数字信号来表示模拟信号
波形编码优点:
- 方法简单、易于实现
- 适应能力强并且语音质量好
波形编码缺点:
- 压缩比相对较低,需要较高的编码速率
一般来说,波形编码的复杂程度比较低,编码速率较高、通常在 16 kbit/s 以上,质量相当高。但编码速率低于 16 kbit/s 时,音质会急剧下降。
1.1 PCM 脉冲编码
最简单的波形编码方法是PCM(Pulse Code Modulation,脉冲编码调制)
它只对语音信号进行采样和量化处理。
优点:编码方法简单,延迟时间短,音质高,重构的语音信号与原始语音信号几乎没有差别
缺点:编码速率比较高(64 kbit/s),对传输通道的错误比较敏感。
2、参数编码
参数编码是从语音波形信号中提取生成语音的参数,使用这些参数通过语音生成模型重构出语音,使重构的语音信号尽可能地保持原始语音信号的语意。
也就是说,参数编码是把语音信号产生的数字模型作为基础,然后求出数字模型的模型参数,再按照这些参数还原数字模型,进而合成语音。
参数编码的编码速率较低,可以达到 2.4 kbit/s,产生的语音信号是通过建立的数字模型还原出来的,因此重构的语音信号波形与原始语音信号的波形可能会存在较大的区别、失真会比较大。而且因为受到语音生成模型的限制,增加数据速率也无法提高合成语音的质量。
不过,虽然参数编码的音质比较低,但是保密性很好,一直被应用在军事上。典型的参数编码方法为 LPC(Linear Predictive Coding,线性预测编码)。
3、混合编码
混合编码是指同时使用两种或两种以上的编码方法进行编码。这种编码方法克服了波形编码和参数编码的弱点,并结合了波形编码高质量和参数编码的低编码速率,能够取得比较好的效果。
三. 编码格式

AVI(.AVI):
- 优点是图像质量好。由于无损AVI可以保存 alpha 通道,经常被我们使用
- 缺点太多,体积过于庞大,而且更加糟糕的是压缩标准不统一
- 只有它不支持流媒体格式
- 支持所有的音视频编码格式
pcm:
音质好,体积大
WAV: PCM加上了44字节的头部,其他与PCM相同
在Windows平台WAV是支撑度最好的,可能是因为WAV是Windows出品的
一般音乐创作中优先选择WAV
MP3
一般MPEG-1,MPEG-2被叫做MP3
而MPEG-4就被叫做MP4
丢掉了PCM中人耳听不到的声音,同时使用感知编码,利用心理学模型,去掉了一些人耳不敏感的声音
是普及度最大的音频编码格式
参考博客
DCT与VLC编码讲解 www.cnblogs.com/stnlcd/p/72…
