

引子
最近很多学弟已经从校园走向了社会,回首才发现我已经从学校毕业出来两年了。
两年时间,学会了很多技能,也经历了一些有意思的项目,但是一直都没有好好的做个记录。所以作为一个老学长也想写些自己的经验给前途无量的学弟,也记录一下自己遇到的有意思的项目。
本篇旨在记录一个工作中遇到的问题,以还原工作场景为目的。
场景描述:
此前,项目需增设一个接口,提供延时提交的批量处理信息能力。
场景为由业务同学提供一批数据(百万量级),后端接口处理完数据后,调用下游链路接口进行二次处理,形成最终统计信息的需求。同时下游链路有限流要求(每三秒钟才能调用一次下游接口),所以最终形成一个延时提交的批处理接口。
需求实现: 数据文本上传(Apache Commons FileUpload) → 文本读取 (fileReader)→ 启动线程 → 接口调用
源码抽象
此处仅展示文本读取和线程处理过程
import lombok.extern.slf4j.Slf4j;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@Slf4j
public class BatchUploadService {
private final static String txtFilePath = "/user/example/txt/";
public void batchTransfer(String fileName){
new Runnable(){
public void run() {
String fileNameComplete = txtFilePath + fileName;
//TODO 此处可做文件校验
try{
BufferedReader reader = new BufferedReader(new FileReader(fileNameComplete));
int counter = 0;
ArrayList<String> transferList = new ArrayList<>();
do{
String line = reader.readLine();
if(line == null){
break;
}
counter++;
if(counter%10 == 0){
//TODO 执行下游链路调用方法;
methodCall(transferList);
transferList.removeAll(transferList);
Thread.sleep(3000);
transferList.add(line);
log.info(line);
}else{
transferList.add(line);
log.info(line);
}
}while(true);
//TODO 执行下游链路调用方法,把不可被整除部分提交;
methodCall(transferList);
}catch (IOException ioException){
log.info(ioException.getMessage(),ioException.getStackTrace());
}catch (Exception exception){
log.info(exception.getMessage(),exception.getStackTrace());
}
};
};
}
//TODO 下游链路调用接口
public void methodCall(List<String> transferList){
log.info("此为链路调用接口,作演示,无具体业务实现");
}
}
代码中已忽略许多业务实现的细节,仅提供功能展示部分。
问题发生:
该接口在需求上线运行2月后,在对比日志数据和文本数据,发现存在极少部分数据未处理进结果集中,512063条丢失了268条。由此产生一系列问题定位过程。没错,接下来才是正文。顺带提一句,代码中批处理线程中未做日志记录,是因为在下游链路调用接口中做了日志记录,意为以链路接口调用是否成功为最终导向。
问题定位:
1. 问题发生后,凭借以往经验,对循环的边界值进行了排查
循环的边界问题:
循环会有达到条件的边界,如上代码中即为(counter%10)这一条件。如果在缺少 transferList.add(line);这行代码,此处可能会每10条丢失一条数据。
如何定位:
边界问题非常常见,定位也很容易;
首先可以查看丢失条数,如果总条数为512063条,基于以上条件,丢失条数因为512063 /10 = 51206条(取整)。
其次可以查看位于边界的数据是否在被处理,基于以上条件,即为10、20、30……条。
再次可以利用批处理接口导入一个大于条件数量的数据文件进行尝试。
2. 由于数据量达百万级,丢失的数据如何定位成了最大的问题。此时我们拥有的条件有处理完成的数据(存储于mysql),初始的数据文本(txt格式)。基于已有的条件,我们怀疑了初始数据文本是否存在重复记录、空行问题。
数据重复问题:
sublime text解决方法:
将数据文本文件以sublime打开,首先先Sort Lines,将文本排序,去掉空行,然后利用正则表达式,选择出重复的记录并替换。正则公式如下:
(.*)(?=.*\n\1)
linux解决方法:
查不重复记录
cat {fileName}|sort|uniq
删重复记录并生成为一个不重复文件
cat {fileName}|sort|uniq > {targetFileName}
解释一下命令:整个命令由管道符“|”承接,cat为读取文件命令,sort为排序命令,uniq为去重命令。为什么要sort?因为如果直接用cat后uniq,那么只会去掉相邻行重复记录,未能达到期望效果。
此番功夫下来,查出空行4条,重复行16条。所以说,上游数据提供的同学不处理好,下游的后端同学是要遭殃的呀。
3. 然鹅,还剩下还有248条呢?
此处有想作妖同学开始了一些另类的定位方法。240条,非常完成的数字,所以可能是同一块一起丢失的。所以我们开始了二分查找法。
将数据三等分,1~250001,250001~500000,500001~512063;我们非常寄希望于是在最后这一块的数据里面丢失的。怎么玩呢?因为文件是逐行读取的,所以从原始数据文件中,找到第1条和第250001条值,然后对比数据库中日志记录的第1条和第250001条值中间所有条数。结果是250000条,匹配,说明数据不在该区间中。此时,心中雀跃,可能是整块丢失的。如法炮制对比了后两个区间,然后数据就开始变得零散了,[250001~500000]中缺少了148条,[500001~512063]缺少了92条。很好,猜测希望破灭。但是还是有人继续用二分的方法定位下去了。不过这是条不归路,不费点力气是很难定位到丢失数据的。
4. 将数据导入mysql,进行数据比对。
最有效快捷的一招,为什么一开始不用这招呢?很简单,mysql数据是生产数据库,不能进行随意导入导出操作,不到不得已不会用这个方式。同时程序的发布窗口期没到,不能进行代码变更。
首先在生产环境先建一张表承载原始数据文件。同时按照批处理接口写一份相同的代码,将调用下游接口代码改成存入数据代码,发布作导入数据库用(这么做,从侧面也验证了批量接口是否有问题)。
最终结果是部分原始数据无法进行下游链路操作,所以在methodCall这个接口中出了异常。同时没有做日志记录,导致了数据丢失。
5. 一些有意思的技能
此处中间因为一些数据丢失的定位非常难,所以在一些情况下我们还用到了excel的vlookup函数,进行了两列值的对比,找出不存在的值。
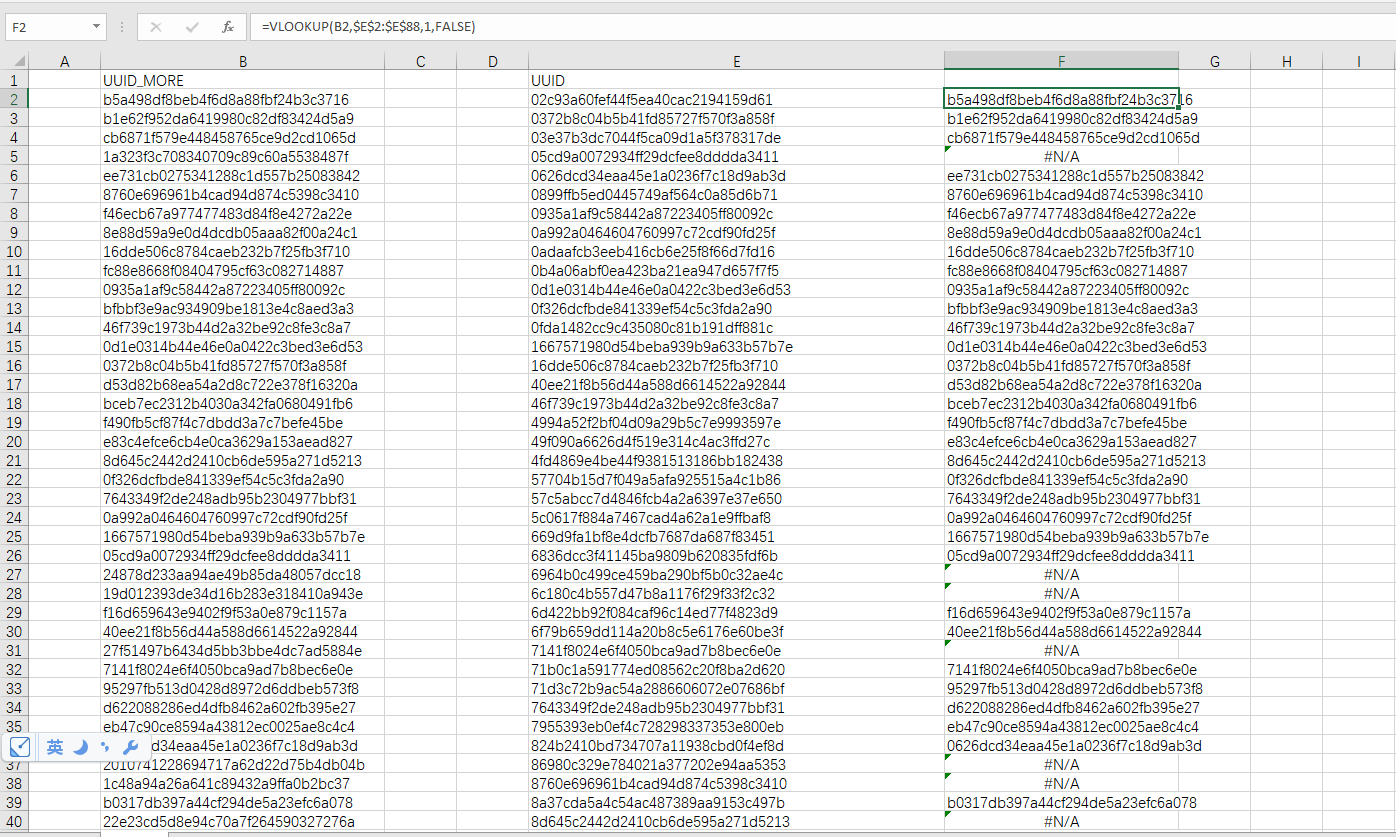
vlookup函数解释
VLOOKUP(lookup_value,table_array,col_index_num,range_lookup)
| 参数 | 简单说明 | 输入数据类型 |
|---|---|---|
| lookup_value | 要查找的值 | 数值、引用或文本字符串 |
| table_array | 要查找的区域 | 数据表区域 |
| col_index_num | 返回数据在查找区域的第几列数 | 正整数 |
| range_lookup | 精确匹配/近似匹配 | FALSE(或0)/TRUE(或1或不填) |
复盘一下
问题发生非常偶然,处理过程也非常有趣,几个同事间处理的方式也各有千秋。这就是真实的工作场景,学校里带出来的只会是java的关键字用法,运行原理,底层技术等等。这些技能很硬,但是在实际的工作中,我们更需要一些多样化的技能。比如我上文中提到的正则表达式、linux命令、vlookup函数。
本篇为给予一些初出校园的同学一些实际开发中问题处理的介绍。也力求为同学展示一下程序员的一些问题定位、处理方式。
