

基本概念
Kafka是一个分布式流处理平台,其运行在一个集群(单个或多个机器)上。其通过topic对消息进行分类,每个消息包含key,value,时间戳三个要素。客户端服务端之间使用TCP协议
核心API
- The Producer API 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic
- The Consumer API 允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理
- The Streams API 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换
- The Connector API 允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容
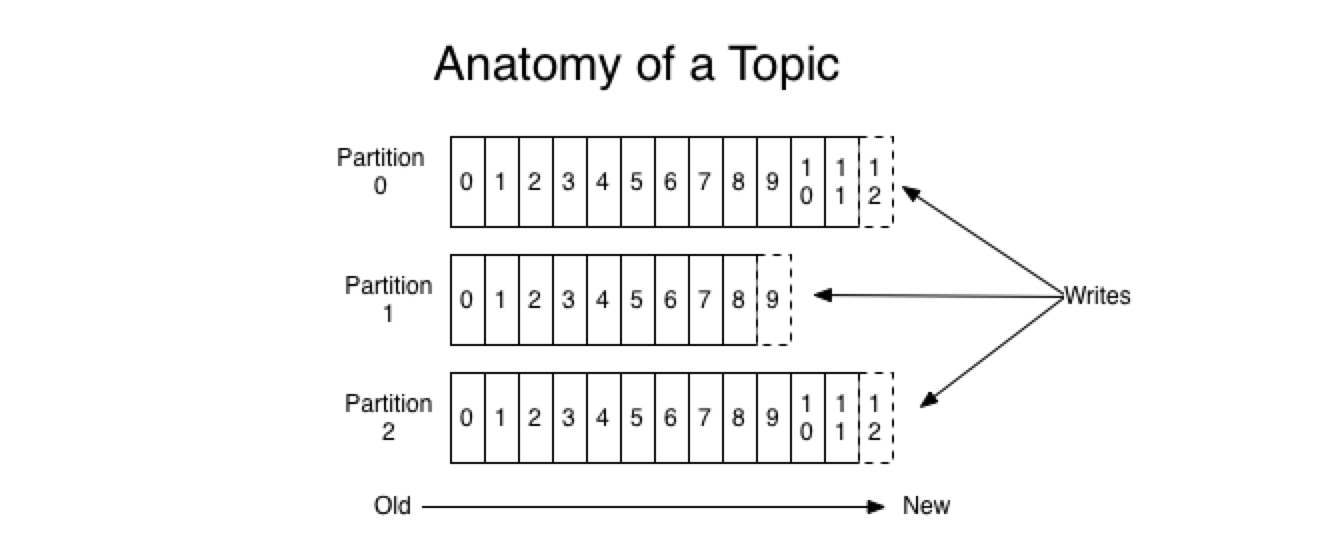
Topic和日志
Topic作为kafka的数据主题,其存储于多个分区日志(Partition)中,每个分区(Partition)都是有序且顺序不可变的记录集,每个分区中的每一个记录都会有一个唯一的offset用于标识其位置。Kafka会保存记录(无论是否被消费过)直到其过期。此外,因为kafka运行在一个集群上,因此,每一个分区都会在已配置的机器上进行容错备份。每个分区都会有一台server作为leader处理该分区的读写请求,其余server作为followers,当leader故障时,其余followers会选出一个作为新的leader接受读写请求。
消费者
消费者使用消费组的概念进行标识。发不到kafka的每一条记录会被分配给订阅消费组中的一个消费者实例进行消费。消费者实例既可以存在于一个机器的多个进程,又可以存在于不同的机器上。
如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例,每个分区对应一个消费者实例
如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程.
Kafka只保证每个分区中的记录是有序的,不保证不同分区之间的有序性,如果需要实现Topic不同分区之间的有序性,可以通过只使用一个分区的方式来实现,这即意味着每个消费者组中只有一个消费者实例消费该Topic(每个分区仅绑定到消费者组中的一个消费者实例)
Kafka作为消息系统
传统队列仅仅能够保证消息的存储有序性,当消费时,服务器按照顺序分配消息,但是因为存在网络的延迟性,无法保证消息按照存储顺序消费,因此在并行的消费者中,无法保证消息的有序性,仅仅可以通过只使用一个消费者的方式解决该问题。
而Kafka使用分区的方式解决了该问题。通过将每个分区分配给消费者组中的一个实例,kafka能够为一个消费者池提供顺序保证和负载均衡。但是需要注意的是,消费者组中的实例数不能超过分区的数量
分区的意义
- 分区通过将Topic的消息分别存储在不同的分区文件解决了服务器对单文件的最大大小限制
- Kafka通过将分区绑定到消费者组中的一个实例为消费者池提供了顺序保证和负载均衡
- 每个分区作为在kafka集群不同机器上同步的单元集
