

08 BDT(提升树)
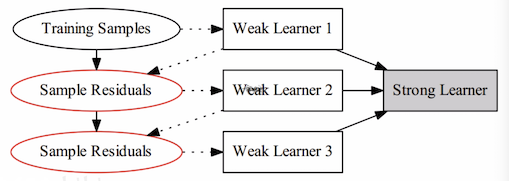
我们先看下简单的提升树(Boosting Decision Tree),提升树是以 CART 决策树为基学习器的集成学习方法
提升树实际上就是加法模型和前向分布算法,将其表示为
在前向分布算法第 m 步时,给定当前的模型 ,求解
得到第 m 棵决策树。不同问题的提升树的区别在于损失函数的不同,如分类用指数损失函数,回归使用平方误差损失
当提升树采用平方损失函数时,第 m 次迭代时表示为
称 r 为残差,所以第 m 棵决策树是对该残差的拟合。要注意的是提升树算法中的基学习器 CART 树是回归树
09 GBDT(梯度提升树)
GBDT 全称为:Gradient Boosting Decision Tree,即梯度提升决策树,理解为梯度提升+决策树。Friedman 提出了利用最速下降的近似方法,利用损失函数的负梯度拟合基学习器:
为了求导方便,在损失函数前面乘以 1/2
对 F (Xi)求导,则有
残差是梯度的相反数,即
在BDT 中使用负梯度作为残差进行拟合。
GBDT 的梯度提升流程
输入:训练集:
初始化:
for t=1 to T do
- 计算负梯度
- 拟合残差得到基学习器
- 得到基学习的权重:
- 更新
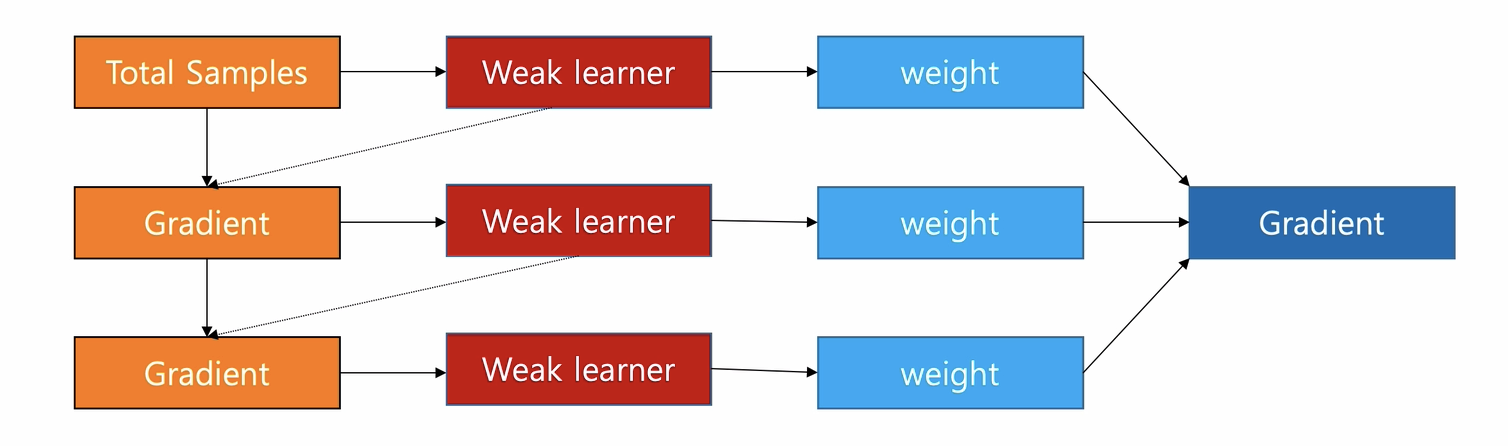
GBDT 与提升树的区别是残差使用梯度替代,而且每个基学习器有对应的参数权重
GBDT 的流程
GBDT 是使用梯度提升的决策树(CART), CART 树回归将空间划分为 K 个不相交的区域,并确定每个区域的输出 k,数学表达如下
GBDT 的流程(回归)
输入:训练集:
初始化:
for t-1 to T do
-
计算负梯度:
-
拟合残差得到回归树,得到第t颗树的叶节点区域
-
更新
得到加法模型
GBDT 的流程(分类)
GBDT 用于分类仍然使用 CART 回归树,使用 softmax 进行概率的映射,然后对概率的残差进行拟合。
For m=1 to M do:
- For k=1 to K do:
- endFor
