

磁盘
关于磁盘的种种,可以参考下让 CPU 告诉你硬盘和网络到底有多慢这篇文章,该文中直观的表述了磁盘和网络在读写数据时的耗时情况。
磁盘寻址和内存寻址时间差异

磁盘数据读取和内存数据读取时间差异

再者还需要知道一点:
当程序要读取的数据时传入内存地址(行地址+列地址),如果数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,通过柱面号,磁头号,扇区号定位磁盘位置,找到数据的起始位置并向后连续读取一页或几页载入内存中。
也就是说当内存中找不到想要读取的数据时,会去磁盘当中读取,而磁盘IO就会成为瓶颈了。从磁盘读取数据这里又有一个名词,叫做磁盘的吞吐量,也就是每秒磁盘 I/O 的流量,即磁盘写入加上读出的数据的大小
当磁盘中的数据量很大时,需要从磁盘中读取一个数据,是会非常非常耗时的,而这个时间也是随着磁盘数据量的增大而增大,为什么呢?
那是因为,这个时候是会发生全量IO的,也就是说,为了找到数据A,磁盘会去遍历所有磁盘上的数据,来找到数据A,磁盘的数据量增大,当然为了查找数据A的时间成本也会大大提升。
数据库
由以上全量IO我们可以想到,如果避免了全量IO是不是磁盘读取的速度会提升很多?
这里首先抛出两个思想名词:分治和以空间换时间
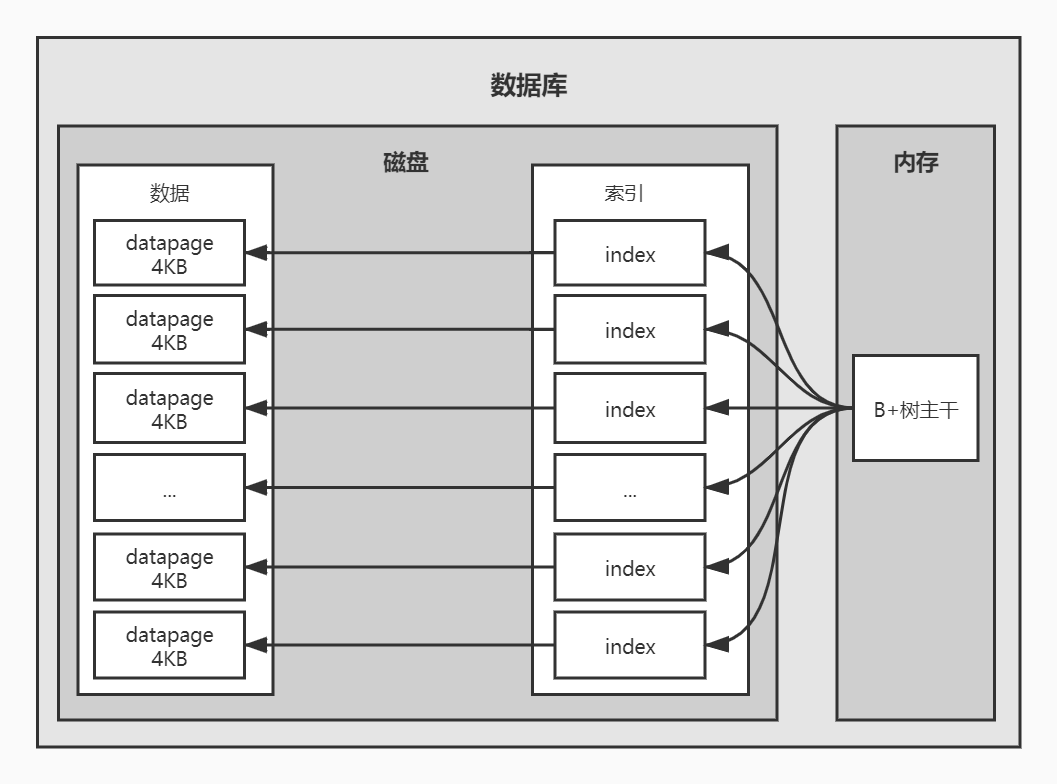
而数据库的存储结构就应用了这两个思想,很好的解决了全量IO的问题,首先来看一张图:
-
- 当我们需要查询一个数据A时,在内存中先通过B+树结构查找到数据A对应的索引内存地址;
-
- 通过步骤一查找到的内存地址去磁盘中找到该索引,将该索引内容从磁盘读取到内存中,在内存中解析出索引中存储的该数据A存储的datapage的地址;
-
- 最后再通过步骤二获取的数据A的datapage的地址去磁盘中把对应地址的datapage的内从读取到内存中,遍历该datapage中的数据找到数据A
由以上步骤,可以看出,从原来的磁盘全量IO变成了只对4KB大小的datapage进行遍历即可,假设原来有1000条数据,每个datapage数据页中仅包含4条数据,也就是会有250个datapage,从之前的遍历1000个数据到现在只要遍历4个数据就可以找到结果了。
当然,这其中增加了索引文件的存储空间,以空间换取了时间的概念。
- 最后再通过步骤二获取的数据A的datapage的地址去磁盘中把对应地址的datapage的内从读取到内存中,遍历该datapage中的数据找到数据A
问题1:为什么datapage是4KB大小?
问题2:datapage中的数据存储方式?
问题3:当数据库需要存储的数据量非常大时,会变慢吗?
得看具体的业务场景,如下:
1] 查询操作,恰好命中了索引。那么数据量增大也不会造成什么影响,通过索引可以很快找到对应数据;
2] 查询操作,未命中索引。那这种情况会造成全表扫描,也就是全量IO了,那是会变慢的;
3] 写操作。这种情况也会变慢,因为还要维护索引,所以写速度会变慢。
4] 高并发场景下。如果同一时间很多请求来查找数据库,如果这个查找的数据量超过了磁盘吞吐量,那也会变慢。
从上面数据库结构的简单解析,数据库不仅仅上面这点,我们可以得出以下链路:读取数据时:内存查索引地址 -> 磁盘索引 -> 磁盘数据。可以看到通过数据库,无论如何是绕不开磁盘这一关的,也就是说,每次我们从数据库查询数据时,都会产生磁盘IO的消耗。那怎么避免这个磁盘IO呢?(这里只从磁盘和内存分析为什么使用redis,当然直接访问数据库还有其他问题限制,比如数据库连接池、数据库本身处理数据的能力等等)
redis和memcache
由于数据库操作必须要进行磁盘IO(这里不讨论数据库的query cache),如果我们经常进行相同的查询操作,那就可以把这部分数据直接加载到内存中供用户访问了,于是,redis就可以运用起来了。
问题1:为什么redis是key/value形式存储,不像mysql一样使用sql?
因为redis是作为no-sql数据库形式存在的,mysql是关系型数据库,数据与数据之间是有关联约束的,而no-sql没有,直接通过key/value形式就可以保存数据及查询数据,且内存大小远远小于磁盘大小,如果数据量很大,超出了内存限制,那也无法实现数据之间的关联和约束,因为所有数据无法完全加载到内存中。
redis和memcache的区别?
redis的value是有类型的,每个类型都到对应相应的方法,取数据时redis可以取相应数据,在redis层进行计算获取想要的数据并返回,而memcache则将所有数据全部返回,由应用端进行计算,redis减少了传输IO量
