简介
scrapyd_pyppeteer:包含 python3.8 selenium pyppeteer scrapy scrapyd scrapyd-client logparser 可以用于scrapydweb的scrapyd节点,使用pyppeteer,在scrapy中异步使用
【docker+pyppeteer跑通】想想空间很大,python版puppeteer,配合异步,docker的扩展。
网上没什么现成的资料,终于琢磨出来了。
splash集群渲染效果差,selenium gird内存原因等引发的长期不稳定问题,pyppeteer配合async作为一个重要补充。
快速尝试
1、启动 scrapyd
# dockerhub
# docker run -p 6800:6800 chinaclark1203/scrapyd_pyppeteer
# 阿里云
docker run -p 6800:6800 registry.cn-hangzhou.aliyuncs.com/luzihang/scrapyd_pyppeteer
scrapyd启动日志:
2020/7/2 下午5:41:46[2020-07-02 17:41:46,768] INFO in logparser.run: LogParser version: 0.8.2
2020/7/2 下午5:41:46[2020-07-02 17:41:46,769] INFO in logparser.run: Use 'logparser -h' to get help
2020/7/2 下午5:41:46[2020-07-02 17:41:46,769] INFO in logparser.run: Main pid: 10
2020/7/2 下午5:41:46[2020-07-02 17:41:46,769] INFO in logparser.run: Check out the config file below for more advanced settings.
2020/7/2 下午5:41:46
2020/7/2 下午5:41:46****************************************************************************************************
2020/7/2 下午5:41:46Loading settings from /usr/local/lib/python3.8/site-packages/logparser/settings.py
2020/7/2 下午5:41:46****************************************************************************************************
2020/7/2 下午5:41:46
2020/7/2 下午5:41:46[2020-07-02 17:41:46,770] DEBUG in logparser.run: Reading settings from command line: Namespace(delete_json_files=True, disable_telnet=False, main_pid=0, scrapyd_logs_dir='/code/logs', scrapyd_server='127.0.0.1:6800', sleep='10', verbose=False)
2020/7/2 下午5:41:46[2020-07-02 17:41:46,770] DEBUG in logparser.run: Checking config
2020/7/2 下午5:41:46[2020-07-02 17:41:46,770] INFO in logparser.run: SCRAPYD_SERVER: 127.0.0.1:6800
2020/7/2 下午5:41:46[2020-07-02 17:41:46,770] ERROR in logparser.run: Check config fail:
2020/7/2 下午5:41:46
2020/7/2 下午5:41:46SCRAPYD_LOGS_DIR not found: '/code/logs'
2020/7/2 下午5:41:46Check and update your settings in /usr/local/lib/python3.8/site-packages/logparser/settings.py
2020/7/2 下午5:41:46
2020/7/2 下午5:41:472020-07-02T17:41:46+0800 [-] Loading /usr/local/lib/python3.8/site-packages/scrapyd/txapp.py...
2020/7/2 下午5:41:472020-07-02T17:41:47+0800 [-] Scrapyd web console available at http://0.0.0.0:6800/
2020/7/2 下午5:41:472020-07-02T17:41:47+0800 [-] Loaded.
2020/7/2 下午5:41:472020-07-02T17:41:47+0800 [twisted.scripts._twistd_unix.UnixAppLogger#info] twistd 18.9.0 (/usr/local/bin/python 3.8.3) starting up.
2020/7/2 下午5:41:472020-07-02T17:41:47+0800 [twisted.scripts._twistd_unix.UnixAppLogger#info] reactor class: twisted.internet.epollreactor.EPollReactor.
2020/7/2 下午5:41:472020-07-02T17:41:47+0800 [-] Site starting on 6800
2020/7/2 下午5:41:472020-07-02T17:41:47+0800 [twisted.web.server.Site#info] Starting factory <twisted.web.server.Site object at 0x7f680d7bf790>
2020/7/2 下午5:41:472020-07-02T17:41:47+0800 [Launcher] Scrapyd 1.2.0 started: max_proc=200, runner='scrapyd.runner'
2、访问 scrapyd
127.0.0.1:6800
3、进入容器运行测试代码
➜ ~ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2c3aba2b8d2b 192.168.95.55:7777/scrapyhub/scrapyd_pyppeteer "./entrypoint.sh" 4 minutes ago Up 4 minutes 0.0.0.0:6800->6800/tcp bold_gagarin
7a299c33e17c joyzoursky/python-chromedriver:3.7 "bash" 2 days ago Up 2 days magical_galileo
➜ ~ docker exec -it 2c3aba2b8d2b bash
root@2c3aba2b8d2b:/code# python
Python 3.8.3 (default, Jun 9 2020, 17:39:39)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
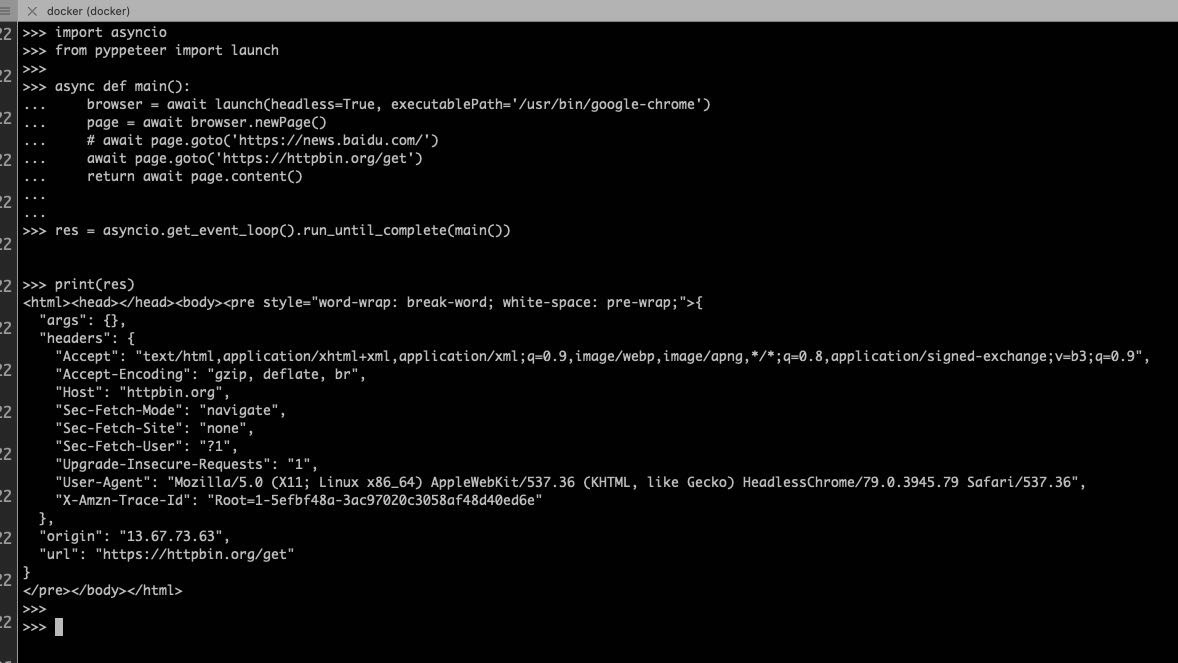
>>> import asyncio
syncio.get_event_loop().run_until_complete(main())
print(res)>>> from pyppeteer import launch
>>>
>>> async def main():
... browser = await launch(headless=True,executablePath='/usr/bin/google-chrome', args=['--no-sandbox', '--disable-dev-shm-usage'])
...
... page = await browser.newPage()
... await page.setViewport(viewport={'width': 1280, 'height': 800})
... await page.setExtraHTTPHeaders(
... {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
... )
... # await page.goto('http://www.jcfc.cn/')
... await page.goto('https://httpbin.org/get')
... # await page.goto('https://news.baidu.com/')
... # await page.screenshot(path='example.png', fullPage=True)
... await asyncio.sleep(5)
... return await page.content()
...
>>> res = asyncio.get_event_loop().run_until_complete(main())
>>> print(res)
<html><head></head><body><pre style="word-wrap: break-word; white-space: pre-wrap;">{
"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US",
"Host": "httpbin.org",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-5efe9ca3-a9d80461ef0dc7725f7e1539"
},
"origin": "13.67.73.63",
"url": "https://httpbin.org/get"
}
</pre></body></html>
>>>
测试代码:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=True,executablePath='/usr/bin/google-chrome', args=['--no-sandbox', '--disable-dev-shm-usage'])
page = await browser.newPage()
await page.setViewport(viewport={'width': 1280, 'height': 800})
await page.setExtraHTTPHeaders(
{'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
)
# await page.goto('http://www.jcfc.cn/')
await page.goto('https://httpbin.org/get')
# await page.goto('https://news.baidu.com/')
# await page.screenshot(path='example.png', fullPage=True)
await asyncio.sleep(5)
return await page.content()
res = asyncio.get_event_loop().run_until_complete(main())
print(res)