

实验目的
- 掌握生成语法分析器的方法,加深对语法分析原理的理解。
- 掌握设计、编制并调试语法分析程序的思想和方法。
- 本实验是高级语言程序设计、数据结构和编译原理中词法分析原理等知识的综合。
实验内容
布置内容及要求
- 输入:
- 无二义性的上下文无关文法G
- 一段词法分析的输出记号流
- 输出:
- 如果分析成功:一棵构造好的语法树
- 如果分析失败:抛出语法错误
- 要求:
- 可以引入3.1.2中的错误处理机制,试图检查出所有可能存在的语法错误
建议思路
输入无二义性的上下文无关文法G
- 消除G的左递归(算法3.1和算法3.2),得到G1
- 提取G1的公共左因子(算法3.3),得到G2
- 对G2构造文法符号的first集合(算法3.5)
- 对G2构造每个非终结符的follow集合(算法3.6)
- 根据3和4的结果构造预测分析表M(算法3.7)
- 以M和记号流为输入实现驱动器算法(算法3.4)
个人理解
- 使用Java语言(个人选择),实现直接左递归算法、间接左递归算法(调用直接左递归)、提取公共左因子算法、FIRST集合构造算法、FOLLOW集合构造算法、预测分析表构造算法、预测分析表驱动算法,个人将其封装进6个类中。
- 表驱动算法需要输出树形图,个人使用了辅助树结构进行输出
实验程序清单
自定义数据结构
//文法数据类型
public class Grammar {
//将文法存储在链表中
LinkedList<LinkedList<String>> grammarLists;
HashMap<String, LinkedList<String>> hashMap;
LinkedList<String> terminatorLinkedList;
}
//FIRST集合数据类型
public class First {
LinkedList<LinkedList<String>> firstLinkedLists;
HashMap<String, LinkedList<String>> firstMap;
}
//FOLLOW集合数据类型
public class Follow {
LinkedList<LinkedList<String>> followLinkedLists;
HashMap<String, LinkedList<String>> followMap;
}
//预测分析表数据类型
public class ForecastAnalysisTable {
LinkedList<String> lefts;
HashMap<String, HashMap<String, String>> tableMap;
LinkedList<String> terminatorLinkedList;
}
//驱动器类数据类型
public class Driver {
TreeNode root;
}
//辅助树节点数据类型
class TreeNode {
String value;
int length;
TreeNode parent;
LinkedList<TreeNode> childrenLinkedList;
}
主函数
因多数实验要求算法存在于内部调用中,主程序无法完整表达,故分别将test代码贴出
//消除左递归算法
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"S->Aa|b",
"A->Ac|Sd|ε"
}
);
//对文法中间接左递归进行处理
grammar.eliminateIndirectLeftRecursion();
//提取公共左因子算法
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"S->iCtS|iCtSeS|a",
"C->b"
}
);
grammar.extractLeftFactor();
}
//构造FIRST集合算法
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"L->E;L|ε",
"E->TE'",
"E'->+TE'|-TE'|ε",
"T->FT'",
"T'->*FT'|/FT'|modFT'|ε",
"F->(E)|id|num"
}
);
grammar.print();
First first = new First(grammar);
first.print();
//构造FOLLOW集合算法
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"L->E;L|ε",
"E->TE'",
"E'->+TE'|-TE'|ε",
"T->FT'",
"T'->*FT'|/FT'|modFT'|ε",
"F->(E)|id|num"
}
);
grammar.print();
Follow follow = new Follow(grammar);
follow.print();
//构造预测分析表算法
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"L->E;L|ε",
"E->TE'",
"E'->+TE'|-TE'|ε",
"T->FT'",
"T'->*FT'|/FT'|modFT'|ε",
"F->(E)|id|num"
}
);
grammar.print();
ForecastAnalysisTable forecastAnalysisTable = new ForecastAnalysisTable(grammar);
forecastAnalysisTable.print();
//预测分析表驱动算法
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"L->E;L|ε",
"E->TE'",
"E'->+TE'|-TE'|ε",
"T->FT'",
"T'->*FT'|/FT'|modFT'|ε",
"F->(E)|id|num"
}
);
grammar.print();
Driver driver = new Driver(grammar, "id+id*id;");
调用函数清单
篇幅有限,仅列出函数名及注释
/**
* 使用String数组初始化文法
*
* @param stringsArray String数组
*/
public Grammar(String[] stringsArray) {}
/**
* 打印产生式
*
* @param production 产生式
* @return 返回字符串化的产生式,形如A->α|β
*/
private String printProduction(LinkedList<String> production) {}
/**
* 判断链表代表的产生式是否为直接左递归,若是则消除之
*
* @param production 待处理产生式
* @return 若未进行直接左递归消除则直接返回原式(即该产生式未出现直接左递归),否则返回后产生式
*/
protected LinkedList<LinkedList<String>> eliminateProductionLeftRecursion(LinkedList<String> production) {}
/**
* 判断产生式是否为直接左递归
*
* @param production 待判断产生式
* @return true|false
*/
private boolean isDirectLeftRecursion(LinkedList<String> production) {}
/**
* 判断产生式是否为间接左递归
*
* @param production 待判断产生式
* @return true|false
*/
private boolean isIndirectLeftRecursion(LinkedList<String> production) {}
/**
* 消除文法间接左递归主函数,由Grammar类直接调用
*/
protected void eliminateIndirectLeftRecursion() {}
/**
* 消除文法直接左递归主函数,由Grammar类直接调用
*/
protected void eliminateDirectLeftRecursion() {}
/**
* 提取公共左因子算法
*/
protected void extractLeftFactor() {}
/**
* 计算两个产生式右部公共左因子长度
*
* @param s1 右部1
* @param s2 右部2
* @return 公共左因子长度
*/
private int commonLeftFactorLength(String s1, String s2) {}
/**
* 判断传入产生式是否存在公共左因子
*
* @param production 待判断产生式
* @return 返回判断结果
*/
private boolean isCommonLeftFactor(LinkedList<String> production) {}
/**
* 构造FIRST集合
*
* @param grammar 文法
*/
public First(Grammar grammar) {}
/**
* 删除重复元素
*
* @param firstCollection 待删除重复元素的FIRST集合
*/
private void removeDuplicates(LinkedList<String> firstCollection) {}
/**
* 构造FOLLOW集合
*
* @param grammar 文法
*/
public Follow(Grammar grammar) {}
/**
* 删除重复元素
*
* @param followMap hashMap
* @param key key
*/
private void removeDuplicates(HashMap<String, LinkedList<String>> followMap, String key) {}
/**
* 构造预测分析表
*
* @param grammar 文法
*/
public ForecastAnalysisTable(Grammar grammar) {}
/**
* 构造语法驱动器
*
* @param grammar 文法
* @param inputCharacterStream 输入字符流
*/
public Driver(Grammar grammar, String inputCharacterStream) {}
/**
* 打印分析树
*
* @param root 根节点
*/
private void printAnalysisTree(TreeNode root) {}
/**
* 为树中所有节点计算长度
*
* @param root 根节点
*/
private void calculateLength(TreeNode root) {}
/**
* 按ppt版式将stack转为String用于打印查看
*
* @param stack 栈
* @return 返回字符串
*/
private String stackToString(Stack<String> stack) {}
调试过程和运行结果
总运行结果
测试内容
使用测试内容为教材原题
/**
* 完整语法编译测试1
* 测试用例
* "L->E;L|ε",
* "E->E+T|E-T|T",
* "T->T*F|T/F|TmodF|F",
* "F->(E)|id|num"
* <p>
* id+id*id;
*/
@org.junit.jupiter.api.Test
void allTest1() {
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"L->E;L|ε",
"E->E+T|E-T|T",
"T->T*F|T/F|TmodF|F",
"F->(E)|id|num"
}
);
//对文法中直接左递归进行处理
grammar.eliminateDirectLeftRecursion();
grammar.print();
Driver driver = new Driver(grammar, "id+id*id;");
}
测试结果
消除直接左递前,文法如下:
L->E;L|ε
E->E+T|E-T|T
T->T*F|T/F|TmodF|F
F->(E)|id|num
产生式: E->TE' 存在直接左递归
产生式: T->FT' 存在直接左递归
文法如下:
L->E;L|ε
E->TE'
E'->+TE'|-TE'|ε
T->FT'
T'->*FT'|/FT'|modFT'|ε
F->(E)|id|num
经过FIRST集合构造算法,得到FIRST集合为:
FIRST( F ) ={ ( id num }
FIRST( T' )={ * / mod ε }
FIRST( T ) ={ ( id num }
FIRST( E' )={ + - ε }
FIRST( E ) ={ ( id num }
FIRST( L ) ={ ( id num ε }
经过FOLLOW集合构造算法,得到FOLLOW集合为:
FOLLOW( L ) ={ # }
FOLLOW( E ) ={ ) ; }
FOLLOW( E' )={ ) ; }
FOLLOW( T ) ={ ) + - ; }
FOLLOW( T' )={ ) + - ; }
FOLLOW( F ) ={ ) * + - / ; mod }
预测分析表如下:
| ; | + | - | * | / | mod | ( | ) | id | num | # |
-------------------------------------------------------------------------------------------------------------------
L | | | | | | | E;L | | E;L | E;L | ε |
E | | | | | | | TE' | | TE' | TE' | |
E' | ε | +TE' | -TE' | | | | | ε | | | |
T | | | | | | | FT' | | FT' | FT' | |
T' | ε | ε | ε | *FT' | /FT' | modFT' | | ε | | | |
F | | | | | | | (E) | | id | num | |
Stack RemainInput Action
#L id+id*id;# pop(L),push(E;L) (L->E;L)
#L;E id+id*id;# pop(E),push(TE') (E->TE')
#L;E'T id+id*id;# pop(T),push(FT') (T->FT')
#L;E'T'F id+id*id;# pop(F),push(id) (F->id)
#L;E'T'id id+id*id;# pop(id),next(ip) id
#L;E'T' +id*id;# pop(T') (T'->ε)
#L;E' +id*id;# pop(E'),push(+TE') (E'->+TE')
#L;E'T+ +id*id;# pop(+),next(ip) +
#L;E'T id*id;# pop(T),push(FT') (T->FT')
#L;E'T'F id*id;# pop(F),push(id) (F->id)
#L;E'T'id id*id;# pop(id),next(ip) id
#L;E'T' *id;# pop(T'),push(*FT') (T'->*FT')
#L;E'T'F* *id;# pop(*),next(ip) *
#L;E'T'F id;# pop(F),push(id) (F->id)
#L;E'T'id id;# pop(id),next(ip) id
#L;E'T' ;# pop(T') (T'->ε)
#L;E' ;# pop(E') (E'->ε)
#L; ;# pop(;),next(ip) ;
#L # pop(L) (L->ε)
# # accept
预测分析成功,生成语法分析树如下:
L
E(L) ;(L) L(L)
T(E) E'(E) ε(L)
F(T) T'(T) +(E') T(E') E'(E')
id(F) ε(T') F(T) T'(T) ε(E')
id(F) *(T') F(T') T'(T')
id(F) ε(T')
Process finished with exit code 0
消除左递归算法测试
直接左递归测试
测试内容
使用消除左递归算法测试直接左递归文法,内容为课后习题


/**
* 消除左递归测试,直接左递归
* 测试用例
* "E->E+T|T",
* "T->T*F|F",
* "F->(E)|-F|id"
*/
@org.junit.jupiter.api.Test
void eliminateLeftRecursionTest2() {
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"E->E+T|T",
"T->T*F|F",
"F->(E)|-F|id"
}
);
//对文法中直接左递归进行处理
grammar.eliminateDirectLeftRecursion();
System.out.print("经过消除文法左递归算法,");
grammar.print();
}
测试结果
消除直接左递前,文法如下:
E->E+T|T
T->T*F|F
F->(E)|-F|id
产生式: E->TE' 存在直接左递归
产生式: T->FT' 存在直接左递归
经过消除文法左递归算法,文法如下:
E->TE'
E'->+TE'|ε
T->FT'
T'->*FT'|ε
F->(E)|-F|id
Process finished with exit code 0
间接左递归测试
测试内容
使用消除左递归算法测试间接左递归文法,内容为PPT例题

/**
* 消除左递归测试,间接左递归
* 测试用例
* "S->Aa|b",
* "A->Ac|Sd|ε"
*/
@org.junit.jupiter.api.Test
void eliminateLeftRecursionTest1() {
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"S->Aa|b",
"A->Ac|Sd|ε"
}
);
//对文法中间接左递归进行处理
grammar.eliminateIndirectLeftRecursion();
}
测试结果
文法中存在 A 与 S 间接左递归
消除直接左递前,文法如下:
S->Aa|b
A->Ac|Aad|bd|ε
产生式: A->bdA'|A' 存在直接左递归
经过消除文法左递归算法,文法如下:
S->Aa|b
A->bdA'|A'
A'->cA'|adA'|ε
Process finished with exit code 0
提取公共左因子算法测试
非循环提取公共左因子算法测试
测试内容
使用提取公共左因子算法测试非循环文法,内容为PPT例题

/**
* 提取公共左因子测试1
* 测试用例
* "S->iCtS|iCtSeS|a",
* "C->b"
*/
@org.junit.jupiter.api.Test
void extractLeftFactorTest1() {
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"S->iCtS|iCtSeS|a",
"C->b"
}
);
grammar.extractLeftFactor();
}
测试结果
此时,文法如下:
S->iCtS|iCtSeS|a
C->b
产生式: S->iCtS|iCtSeS|a 存在公共左因子: iCtS ,对其进行处理
此时,文法如下:
S->iCtSS'|a
S'->eS|ε
C->b
提取左因子算法处理完毕
Process finished with exit code 0
循环提取公共左因子算法测试
测试内容
使用提取公共左因子算法测试循环文法,内容为课后作业习题,为算法直观输出,与作业解答符号有些许不同
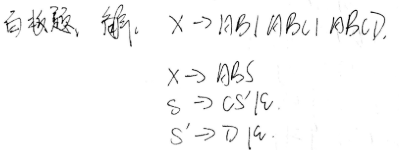
/**
* 提取公共左因子测试2
* 测试用例:课后作业
* "X->AB|ABC|ABCD"
*/
@org.junit.jupiter.api.Test
void extractLeftFactorTest2() {
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"X->AB|ABC|ABCD"
}
);
grammar.extractLeftFactor();
}
测试结果
此时,文法如下:
X->AB|ABC|ABCD
产生式: X->AB|ABC|ABCD 存在公共左因子: AB ,对其进行处理
此时,文法如下:
X->ABX'
X'->CD|C|ε
产生式: X'->CD|C|ε 存在公共左因子: C ,对其进行处理
此时,文法如下:
X->ABX'
X'->CX''|ε
X''->D|ε
提取左因子算法处理完毕
Process finished with exit code 0
FIRST集合构造算法测试
测试内容
使用FIRST集合构造算法测试,测试内容为PPT例题
/**
* 构造FIRST集合测试1
* 测试用例
* "L->E;L|ε",
* "E->TE'",
* "E'->+TE'|-TE'|ε",
* "T->FT'",
* "T'->*FT'|/FT'|modFT'|ε",
* "F->(E)|id|num"
*/
@org.junit.jupiter.api.Test
void constructFIRSTCollectionTest1() {
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"L->E;L|ε",
"E->TE'",
"E'->+TE'|-TE'|ε",
"T->FT'",
"T'->*FT'|/FT'|modFT'|ε",
"F->(E)|id|num"
}
);
grammar.print();
First first = new First(grammar);
first.print();
}
测试结果
文法如下:
L->E;L|ε
E->TE'
E'->+TE'|-TE'|ε
T->FT'
T'->*FT'|/FT'|modFT'|ε
F->(E)|id|num
经过FIRST集合构造算法,得到FIRST集合为:
FIRST( F ) ={ ( id num }
FIRST( T' )={ * / mod ε }
FIRST( T ) ={ ( id num }
FIRST( E' )={ + - ε }
FIRST( E ) ={ ( id num }
FIRST( L ) ={ ( id num ε }
Process finished with exit code 0
FOLLOW集合构造算法测试
测试内容
使用FOLLOW集合构造算法测试,测试内容为PPT例题
/**
* 构造FOLLOW集合测试1
* 测试用例
* "L->E;L|ε",
* "E->TE'",
* "E'->+TE'|-TE'|ε",
* "T->FT'",
* "T'->*FT'|/FT'|modFT'|ε",
* "F->(E)|id|num"
*/
@org.junit.jupiter.api.Test
void constructFOLLOWCollectionTest1() {
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"L->E;L|ε",
"E->TE'",
"E'->+TE'|-TE'|ε",
"T->FT'",
"T'->*FT'|/FT'|modFT'|ε",
"F->(E)|id|num"
}
);
grammar.print();
Follow follow = new Follow(grammar);
follow.print();
}
测试结果
文法如下:
L->E;L|ε
E->TE'
E'->+TE'|-TE'|ε
T->FT'
T'->*FT'|/FT'|modFT'|ε
F->(E)|id|num
经过FOLLOW集合构造算法,得到FOLLOW集合为:
FOLLOW( L ) ={ # }
FOLLOW( E ) ={ ) ; }
FOLLOW( E' )={ ) ; }
FOLLOW( T ) ={ ) + - ; }
FOLLOW( T' )={ ) + - ; }
FOLLOW( F ) ={ ) * + - / ; mod }
Process finished with exit code 0
预测分析表构造算法测试
测试内容
使用预测分析表构造算法测试,测试内容为PPT例题
/**
* 构造预测分析表测试
* 测试用例
* "L->E;L|ε",
* "E->TE'",
* "E'->+TE'|-TE'|ε",
* "T->FT'",
* "T'->*FT'|/FT'|modFT'|ε",
* "F->(E)|id|num"
*/
@org.junit.jupiter.api.Test
void constructForecastAnalysisTableTest() {
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"L->E;L|ε",
"E->TE'",
"E'->+TE'|-TE'|ε",
"T->FT'",
"T'->*FT'|/FT'|modFT'|ε",
"F->(E)|id|num"
}
);
grammar.print();
ForecastAnalysisTable forecastAnalysisTable = new ForecastAnalysisTable(grammar);
forecastAnalysisTable.print();
}
测试结果
文法如下:
L->E;L|ε
E->TE'
E'->+TE'|-TE'|ε
T->FT'
T'->*FT'|/FT'|modFT'|ε
F->(E)|id|num
经过FIRST集合构造算法,得到FIRST集合为:
FIRST( F ) ={ ( id num }
FIRST( T' )={ * / mod ε }
FIRST( T ) ={ ( id num }
FIRST( E' )={ + - ε }
FIRST( E ) ={ ( id num }
FIRST( L ) ={ ( id num ε }
经过FOLLOW集合构造算法,得到FOLLOW集合为:
FOLLOW( L ) ={ # }
FOLLOW( E ) ={ ) ; }
FOLLOW( E' )={ ) ; }
FOLLOW( T ) ={ ) + - ; }
FOLLOW( T' )={ ) + - ; }
FOLLOW( F ) ={ ) * + - / ; mod }
预测分析表如下:
| ; | + | - | * | / | mod | ( | ) | id | num | # |
-------------------------------------------------------------------------------------------------------------------
L | | | | | | | E;L | | E;L | E;L | ε |
E | | | | | | | TE' | | TE' | TE' | |
E' | ε | +TE' | -TE' | | | | | ε | | | |
T | | | | | | | FT' | | FT' | FT' | |
T' | ε | ε | ε | *FT' | /FT' | modFT' | | ε | | | |
F | | | | | | | (E) | | id | num | |
Process finished with exit code 0
预测分析表驱动算法测试
测试内容
使用预测分析表驱动算法测试,测试内容为PPT例题
/**
* 预测分析表驱动测试
* 测试用例
* "L->E;L|ε",
* "E->TE'",
* "E'->+TE'|-TE'|ε",
* "T->FT'",
* "T'->*FT'|/FT'|modFT'|ε",
* "F->(E)|id|num"
* <p>
* id+id*id;
*/
@org.junit.jupiter.api.Test
void predictiveAnalysisTest() {
//初始化文法
Grammar grammar = new Grammar(
new String[]{
"L->E;L|ε",
"E->TE'",
"E'->+TE'|-TE'|ε",
"T->FT'",
"T'->*FT'|/FT'|modFT'|ε",
"F->(E)|id|num"
}
);
grammar.print();
Driver driver = new Driver(grammar, "id+id*id;");
}
测试结果
文法如下:
L->E;L|ε
E->TE'
E'->+TE'|-TE'|ε
T->FT'
T'->*FT'|/FT'|modFT'|ε
F->(E)|id|num
经过FIRST集合构造算法,得到FIRST集合为:
FIRST( F ) ={ ( id num }
FIRST( T' )={ * / mod ε }
FIRST( T ) ={ ( id num }
FIRST( E' )={ + - ε }
FIRST( E ) ={ ( id num }
FIRST( L ) ={ ( id num ε }
经过FOLLOW集合构造算法,得到FOLLOW集合为:
FOLLOW( L ) ={ # }
FOLLOW( E ) ={ ) ; }
FOLLOW( E' )={ ) ; }
FOLLOW( T ) ={ ) + - ; }
FOLLOW( T' )={ ) + - ; }
FOLLOW( F ) ={ ) * + - / ; mod }
预测分析表如下:
| ; | + | - | * | / | mod | ( | ) | id | num | # |
-------------------------------------------------------------------------------------------------------------------
L | | | | | | | E;L | | E;L | E;L | ε |
E | | | | | | | TE' | | TE' | TE' | |
E' | ε | +TE' | -TE' | | | | | ε | | | |
T | | | | | | | FT' | | FT' | FT' | |
T' | ε | ε | ε | *FT' | /FT' | modFT' | | ε | | | |
F | | | | | | | (E) | | id | num | |
Stack RemainInput Action
#L id+id*id;# pop(L),push(E;L) (L->E;L)
#L;E id+id*id;# pop(E),push(TE') (E->TE')
#L;E'T id+id*id;# pop(T),push(FT') (T->FT')
#L;E'T'F id+id*id;# pop(F),push(id) (F->id)
#L;E'T'id id+id*id;# pop(id),next(ip) id
#L;E'T' +id*id;# pop(T') (T'->ε)
#L;E' +id*id;# pop(E'),push(+TE') (E'->+TE')
#L;E'T+ +id*id;# pop(+),next(ip) +
#L;E'T id*id;# pop(T),push(FT') (T->FT')
#L;E'T'F id*id;# pop(F),push(id) (F->id)
#L;E'T'id id*id;# pop(id),next(ip) id
#L;E'T' *id;# pop(T'),push(*FT') (T'->*FT')
#L;E'T'F* *id;# pop(*),next(ip) *
#L;E'T'F id;# pop(F),push(id) (F->id)
#L;E'T'id id;# pop(id),next(ip) id
#L;E'T' ;# pop(T') (T'->ε)
#L;E' ;# pop(E') (E'->ε)
#L; ;# pop(;),next(ip) ;
#L # pop(L) (L->ε)
# # accept
预测分析成功,生成语法分析树如下:
L
E(L) ;(L) L(L)
T(E) E'(E) ε(L)
F(T) T'(T) +(E') T(E') E'(E')
id(F) ε(T') F(T) T'(T) ε(E')
id(F) *(T') F(T') T'(T')
id(F) ε(T')
Process finished with exit code 0
程序的主要部分及其功能说明
Grammar构造算法(Grammar.java)
- 接收String[] stringsArray类型输入字符流,将其构造为Grammar
- Grammar包含grammarLists、hashMap两部分存储文法内容及结构,terminatorLinkedList部分用于存储终结符集
- 提前存储多种存储方式以便后续操作简便性
消除左递归算法(Grammar.eliminateIndirectLeftRecursion())
- 遍历所有产生式,进行间接左递归展开
- 间接左递归展开完成后,遍历所有产生式
- 对其中直接左递归展开式做直接左递归消除
提取公共左因子算法(Grammar.extractLeftFactor())
- 遍历文法所有产生式,判断当前产生式是否存在公共左因子,若存在,进行处理
- 对单个产生式分离左部、计算右部公共左因子
- 根据所得公共左因子,对产生式进行变换,并暂存入中间链表
- 统一对文法中存在公共左因子的产生式进行替换
- 循环算法,若文法发生变动,则再次检查文法是否存在公共左因子,直至文法在提取左因子算法中不存在变动为止
构造FIRST集合算法(First.java)
- 接收Grammar类型数据构造FIRST集合
- 自下而上遍历文法计算FIRST集
- 遍历右部,对非终结符/符号终结符/其他终结符分别做处理
- 去除firstCollection中的重复项
- 将产生式FIRST集合从头部插入文法FIRST集合链表,与教学计算方案一致
构造FOLLOW集合算法(Follow.java)
- 接收Grammar类型数据构造Follow集合
- 自上而下遍历文法,初始化FOLLOW集的HashMap
- 自上而下遍历文法,为每个FOLLOW集合进行寻找
- 对每一个左部,遍历所有文法产生式右部,查找可加入FOLLOW集合的元素
- 对遍历中的右部,判断当前产生式右部包含此待求FOLLOW集非终极符,若不包含则直接跳过,若包含直接定位之
- 根据此非终结符后follow元素进行分别处理
- 删除FOLLOW集合中重复项
预测分析表构造算法(ForecastAnalysisTable.java)
- 接收Grammar类型数据构造ForecastAnalysisTable预测分析表
- 调用First.java、Follow.java计算FIRST、FOLLOW集合
- 遍历文法所有产生式,对文法的每个产生式A->α执行操作
- 遍历右部进行行构造
- 对右部为ε/右部首位为非终结符/右部首位为终结符情况分别处理
预测分析表驱动算法(Driver.java)
- 接收Grammar类型数据及inputCharacterStream输入字符串构造预测分析表进行驱动计算
- 构造栈和存储剩余输入字符流的StringBuilder
- 初始化树及树节点栈用于存放分析树
- 循环驱动直至接收到来着成功匹配或匹配失败的break信号
- 判断预测分析是否结束
- 计算剩余输入中的下一终结符
- 判断pop与ip内容,执行对应操作
- 生成并打印语法分析树
实验收获体会
- 深刻理解了与法遍历器构建流程
- 复习了语法分析树中树结构运用及拓扑算法运用
- 本次实验吸取词法分析经验,在动手写代码前提前设计构造数据结构,大多数据结构存储了链表与hashMap表两种结构,各自在某些算法中发挥了速度优势
- 写算法时封装了较多方法,提高了复用性
改进意见
- 因本次实验时间较紧,在实现了流程可从头到尾运行与可输出树形图的基础上,并未实现3.1.2中的错误处理机制,可在空余时间补全
- 间接左递归与直接左递归的耦合做的不够好,二义性文法未做抛错处理
- 树形图打印部分对节点长度计算使用了拓扑算法,可改用树的深度遍历更节省时间复杂度
完整代码
链接: pan.baidu.com/s/15ofrVDzN… 提取码: w3z9
