

一、多态
1. 多态是针对对象而言,而非类
2. 格式: 父类名称 对象名 = new 子类名称()
或者 接口名称 对象名 = new 实现名称()
3. 引用情况下
直接调用成员变量,首先找父类,没有则向上找
直接调用成员方法,首先找子类,没有则向上找
间接调用成员变量,方法属于谁,则调用谁的成员变量
4. 对比
成员变量:编译看左边(父类),运行看左边(父类) 成员方法:编译看左边(父类),运行看右边(子类)
5. 多态好处
多态更好地实现抽象
Employee teacher = new Teacher();
teacher.work();//教课
Employee assistant = new Assistant();
assistant.work();//批改作业
6. 安全性
- 向上转型一定是安全的,但调用不了子类特有方法
Animal animal = new Cat();
- 向下转型是在向上转型的基础上进行的,实质是一个还原的动作
Animal animal = new Cat();
Cat cat = (Cat)animal;
7.多态判断问题
1. 如何才能判断一个父类类型的引用对象,本来的子类类型
/*
判断父类引用 animal 本来向上转型时是不是Dog类型
*/
if(animal instanceof Dog){
Dog dog = (Dog)animal;
dog.watchHouse();
}
8.多态的好处
/*
方法唯一,父类作为方法参数时,可以往里面传子类
*/
public static void main(String[] args){
giveMeAPet(new Dog());
giveMeAPet(new Cat());
}
public static void giveMeAPet(Animal animal){
if(animal instanceof Dog){
Dog dog = (Dog)animal;
dog.watchHouse();
}
if(animal instanceof Cat){
Cat cat = (Cat)animal;
cat.catchMouse();
}
}
二、内部类
1. 分类
a. 成员内部类
b. 局部内部类(包含匿名内部类)
2. 成员内部类
public class Body {
public class Heart{
...
}
}
编译后文件输出格式为
Body.class Body$Heart.class
1). 变量重名问题
public class Outer{
int num =10;
public class Inner{
int num =20;
public void MethodInner(){
int num =30;
System.out.println(num);//30
System.out.println(this.num);//20
System.out.println(Outer.this.num);//10
}
}
}
3. 局部内部类
定义在方法体中,不能用修饰符修饰
1). 局部内部类的final问题
/*
局部内部类,如果希望访问所在方法的局部变量,那么这个局部变量必须是【有效final】的(或者用final关键字修饰,或者只赋值一次)
备注:
从java8开始,只要局部变量事实不变,那么final关键字可以省略
原因:
1. new出来的对象在堆内存中
2. 局部变量时跟着方法走的,在栈内存中
3. 方法运行结束之后,立刻出栈,局部变量就会立刻消失
4. 但是new出来的对象会在堆当中持续存在,直到垃圾回收消失
如果methodOuter()在栈内存中用完消失,而new出来的
Inner对象还需要调用methodOuter() 中的局部变量,则需要定义局部常量为final,Inner对象会复制一份局部变量,以备自己使用,避免局部变量跟随方法出栈消失
*/
public class MyOuter{
public void methodOuter(){
int num =10;
class Inner(){
public void methodInner(){
System.out.println(num);
}
}
}
}
4.匿名内部类
重点掌握,将作为lambda表达式的基础
1). 使用情形
如果接口的实现类(或者是父类的子类)只需要使用唯一一次,此种情况可以省略该类的定义,而改用匿名内部类
/*
如果接口的实现类(或者是父类的子类)只需要使用唯一一次,此种情况可以省略该类的定义,而改用【匿名内部类】
格式:
接口名称/父类名称 对象名 = new 接口名称/父类名称(){
//覆盖重写所有抽象方法
};
*/
public static void main(String() args){
//myInterface oby = new MyInterfaceImpl();
//obj.method();
//使用匿名内部类
MyInterface obj = new MyInterface(){
@Override
public void method(){
System.out.println("匿名内部类实现了方法");
}
};
obj.method();
}
2). 注意事项
a. 匿名内部类,在【创建对象】时,只能使用唯一一次
b. 匿名对象,在【调用方法】时,只能使用唯一一次
c. 匿名内部类时省略了实现类/子类名称,但是匿名对象省略了对象名称,两者不是一回事
d. 匿名内部类不可以存在静态内容,匿名内部类晚于类加载,静态内容是跟随类加载。
三、Object类中的一些方法
1. toString()
直接打印对象,就是调用对象的toString() 方法,如果对象的类没有重写该方法,则调用Object类的toString(),对于Object类来说,就是打印地址值
常用的
Scanner和ArrayList类都重写了toString()方法
2. equals()方法
String s1 = null;
String s2 = "abc";
boolean b = s1.equals(s2);//报错空指针异常
boolean B = Objects.equals(s1,s2); //容忍空指针异常错误
四、可变参数
1.注意事项
- 一个方法的参数列表,只能有一个可变参数
- 如果方法的参数有多个,那么可变参数必须写在参数列表末尾
2.代码示例
public static int add(int... arr){
int sum =0;
for(int a:arr){
sum += a;
}
return sum;
}
3.可变参数的特殊写法
public static void method(Object ... obj){ ... }
五、异常
1. 处理机制图解
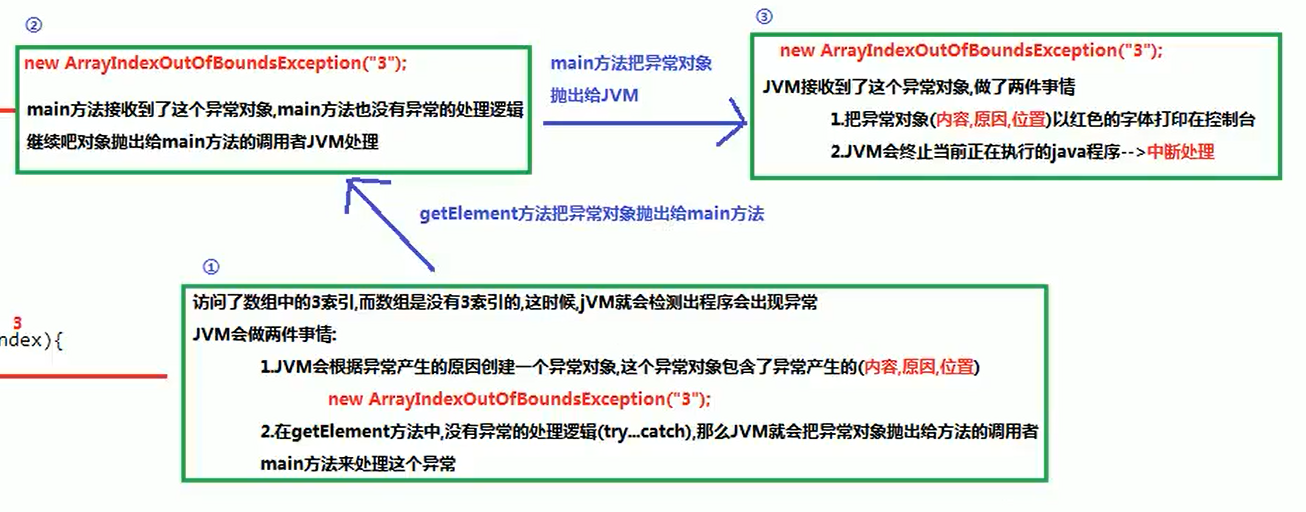
2.处理异常的常用关键字
1). 抛出异常throw
a. 作用:
可以使用
throw关键字在指定方法中抛出指定异常
b. 使用格式:
throw new xxxException("异常产生的原因");
c.注意事项
a).
throw关键字必须写在方法内部
b).throw关键字后边new的对象必须是Exception或者Exception的子类对象
c).throw关键字抛出指定的异常对象,我们就必须处理:throw关键字后边创建的是RuntimeException或者其子类对象,我们可以不处理,默认交给JVM处理(打印异常对象,中断程序);
throw关键字后边创建的是编译异常(代码报错),就必须处理异常,要么throws,要么try{}catch(){}处理。
/*
工作中,首先必须对方法传递的参数进行合法性校验,如果参数不合法,那么必须使用抛出异常的方式,告知方法调用者,传递的参数有问题
*/
public static int getElement(int[] arr,int index){
/*
我们可以对传递过来的参数数组,进行合法性校验,如果数组arr的值为null
那么就抛出空指针异常,告知方法调用者“传递的数组值是null”
*/
if(arr == null){
//交给了JVM处理,NullPointerException异常是RuntimeException
throw new NullPointerException("传递的数组的值为空");
}
int ele = arr[index];
return ele;
}
注意: Objects类中的静态方法
public static<T> T requireNonNull(T obj): 查看指定引用对象不是null
源码:
public static <T> T requireNonNull(T obj){
if(obj == null){
throw new NullPointerException();
}
return obj;
}
上述代码可优化为
public static void method(Object obj){
Objects.requireNonNull(obj);
//重载
Objects.requireNonNull(obj,"传递的数组的值为空");
}
2).抛出异常throws
a. 作用
当方法内部抛出异常对象的时候,那么我们就必须处理这个异常对象,可以使用throws关键字处理异常对象,会把异常对象声明抛出给方法的调用者处理(自己不处理,给别处理),最终交给JVM处理,即中断处理
b. 格式
在方法名后
public void method() throws xxxException,yyyException{
throw new xxxException("产生原因");
throw new yyyException("产生原因");
}
c. 注意事项
throws关键字必须写在方法声明处throws关键字后声明的异常必须是Exception或者其子类- 方法内部如果声明多个异常对象,那么
throws后边也必须声明多个异常,如果throw的异常对象有继承关系,直接声明父类异常即可- 调用了一个声明抛出异常的方法,就必须处理声明的异常,要么继续使用
throws声明抛出,交给方法调用者处理,最终交给JVM,要么try{}catch(){}自己处理异常- 如果方法中
throw的异常对象是编译异常,则方法名需要throws编译异常
3). 捕获异常try catch
a. 存在的意义
当希望执行异常的后续代码时(throws会请求JVM中断程序),则自己捕获异常,执行catch(){}后,继续执行之后代码
b. 格式
try{
可能产生异常的代码
}catch(定义一个异常的变量,用来接收try中抛出的异常对象){
异常的处理逻辑,一般记录到一个日志中
return;//可以结束程序
}
...catch(){
//catch可以有多个,但异常对象如果有继承关系,则子类异常变量必须写在上面,否则报错,原因是多态,JVM按照catch顺序查找异常对象类型,如果父类在前,父类可以指向子类引用(导致子类变量虽然定义,但未被使用),但不详细,因此需要报错
}
c. 异常对象的常用方法
getMessage()打印简短描述toString()打印详细信息printStackTrace()JVM打印异常对象默认调用的信息最全面的方法
4). finally代码块
a. 作用
一些代码无论是否出现异常,都需要执行,可以用finally声明,在finally代码块中存在的代码一定会被执行到,至于try catch,可以执行到catch之后的语句,但执行不到try出现异常后的代码语句
b. 格式
/*
1. 必须和try一起使用
2. 一般用于资源释放(资源回收),无论程序是否出现异常,最后都要资源释放(IO)
*/
public static void main(String[] args){
try{
readFile("test.txt");
}catch(IOException e){
e.printStackTrace();
}finally{
//无论是否出现异常,都会执行,因此最好不在此处写return
System.out.println("资源释放");
}
}
5). 辨析
编译期异常必须在代码层面上处理,用throws或者try catch
运行期异常可以在代码层面上不处理,JVM会中断处理
3.自定义异常类
1).格式
public class xxxException extends Exception | RuntimeException{
添加一个空参数构造方法
添加一个带异常信息的构造方法
}
2).注意
- 自定义异常类一般以Exception结尾
- 自定义异常类必须继承
Exception或者RuntimeException
其中Exception代表编译期异常,如果方法内部抛出编译期异常,就必须处理,要么throws, 要么try catch
RuntimeException代表运行期异常,无需处理
3).代码
/*
参考源码,使用父类方法
*/
public RegisterException extends Exception{
public RegisterException{
super();
}
public RegisterException(String message){
super(message);
}
}
六、并发与并行
并发: 交替执行
并行: 同时执行
七、 Lambda表达式
JDK1.8新特性
0. 使用前提
- 使用lambda表达式必须具有接口,且接口中有且仅有一个抽象方法,有且仅有一个抽象方法的接口,称为函数式接口
- 使用lambda表达式必须有上下文推断,即方法的参数或者局部变量类型必须是lambda对应的接口类型,才能使用lambda作为该接口的实例
1. 面向对象思想
做一件事情,找一个能解决这个事情的对象,调用对象的方法,完成事情
2. 函数式编程思想
只要能获取结果,谁去做,怎么做都不重要,只重视结果,不重视过程
3. 代码
public static void main(String[] args){
//使用匿名内部类实现多线程
new Thread(new Runnable(){
@Override
public void run(){ System.out.println(Thread.currentThread().getName()+"新线程创建了");
}
}).start;
//使用lambda表达式实现多线程
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"新线程创建了");
}).start;
}
4. 标准格式
lambda表达式由3部分组成:
(参数列表) -> { 一些重写方法的代码}
- 一些参数
如果参数数据类型通过上下文推导,则可省略
如果括号中的参数只有一个,那么数据类型和()都可省略
- 一个箭头
把参数传递给方法体
- 一段代码
如果只有一行代码,其中的
return {} ;均可省略,要省略必须一起省略
八、 File
-
windows中文件分隔符(pathSeparator)是
;文件名分隔符(separator)是\ -
Linux中文件分隔符是
:文件名分隔符是/ -
定义文件路径字符串是可以通过
File.separator获取系统字符串类型的文件名分隔符 -
打印文件对象,重写了
toString()方法,即getPath()方法。实则打印其路径public String toString(){ return getPath(); } -
常用方法
- 获取
public String getAbsolutePath()
public String getPath()
public String getName() //返回文件或目录名称
public long length() //以字节计
- 判断
public boolean exists()
public boolean isDirectory()
public boolean isFile()
- 创建删除
public boolean createNewFile() //创建文件的路径必须存在,否则抛出IOException
public boolean delete() // 直接在硬盘删除文件/文件夹,不走回收站,删除需谨慎
public boolean mkdir()
public boolean mkdirs() //创建此File表示的目录,包括任何必需但不存在的父目录,即多级文件夹
- 目录的遍历
public String[] list() //返回File数组,表示该File目录中所有子文件或目录,隐藏的也能获取到
public File[] listFiles() //返回File数组,表示该File目录中所有子文件或目录,隐藏的也能获取到
- 文件过滤器
listFiles(FileFilter filter)
File[] files = dir.listFiles(new FileFilter(){
@Override
public boolean accept(File pathName){
//返回true则将文件原路返回给方法调用者listFiles(FileFilter filter)方法,存储在File[]数组中
return pathName.getName().endsWith(".java");
}
});
//lambda表达式
File[] files = dir.listFiles(pathName -> pathName.getName).endsWith(".java"));
listFiles(FilenameFilter filter)
//lambda表达式
File[] files = dir.listFiles((dir, name)->name.getName().endsWith(".java"));
九、IO
1. 输出流
1). 图解
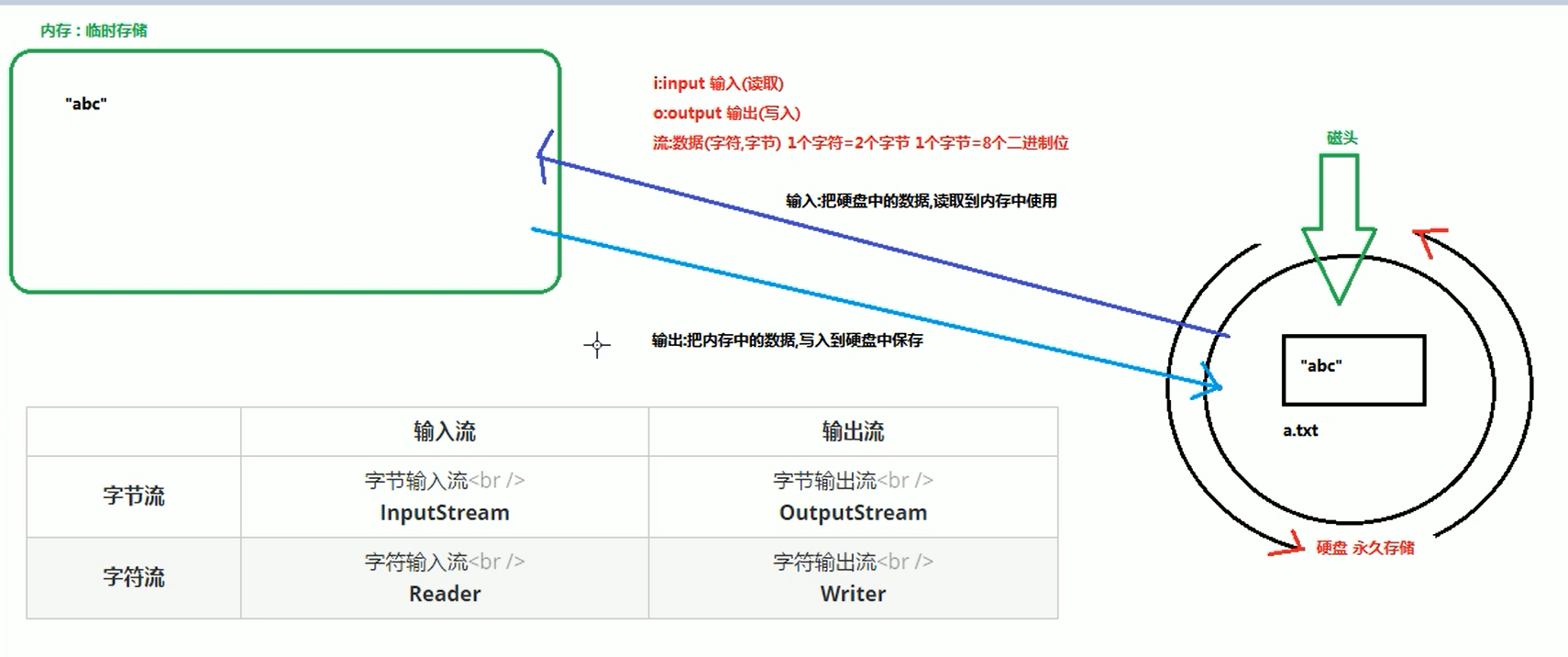
输入输出是相对于内存而言,输入即从硬盘中读取数据,输出即向硬盘中写入数据
2). 存储原理及打开原理
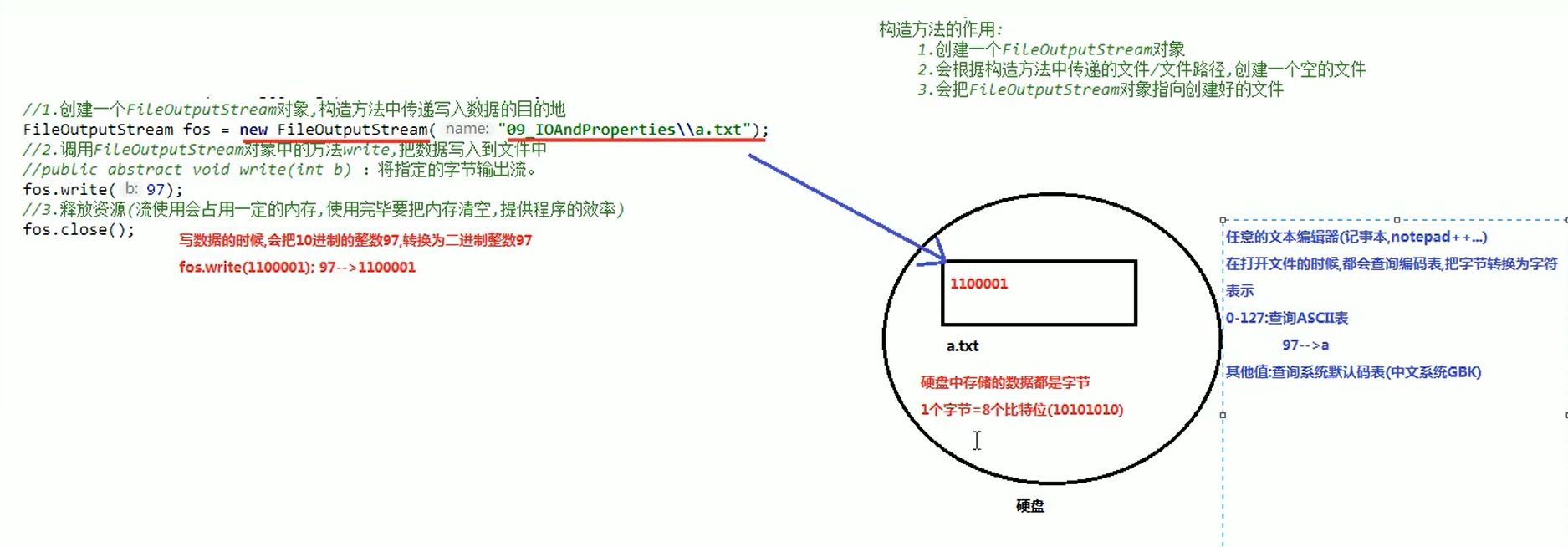
Java程序--> JVM --> OS --> 系统本地的文件写入方法 --> 向硬盘写入文件
3). 常用方法
FileOutputStream extends OutputStream
//续写
FileOutputStream(String name,boolean append) //创建一个具有指定name的文件写入数据的输出流,append为续写开关,值为true时则续写,为false则覆盖原文件
FileOutputStream(File file,boolean append)同上
//换行
/*
windows:\r\n
linux: /n
mac: /r
*/
FileOutputStream fos = new FileOutputStream("\\c.txt");
fos.write("\r\n".getBytes());
fos.close();
2. 输出流
1). 图解

read()方法读取完会向后移一位
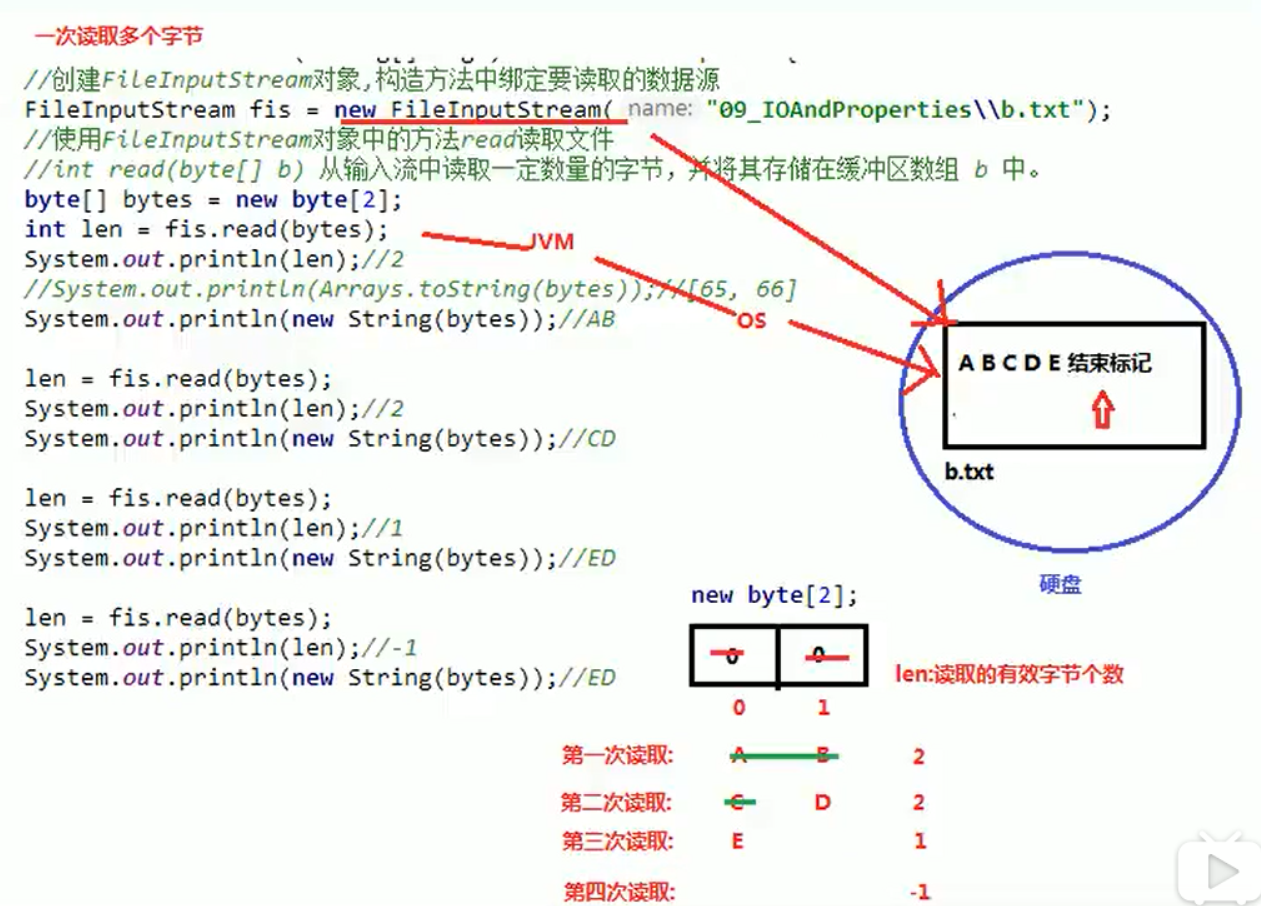
第三次和第四次读取的结果都为
ED
2). 读取原理
Java程序 --> JVM --> OS --> 系统本地的读取文件方法 --> 从硬盘读取文件
3).常用方法
/*
字节输入流一次读取多个字节的方法:
int read(byte[] b)从输入流中读取一定数量的字节,并将其存储在缓冲区数组b中
明确两件事:
1. 方法的参数byte[]的作用?
起到缓冲作用,存储每次读取到的多个字节,一般定义为1024(1kB),或者1024的整数倍
2. 方法的返回值int是什么?
每次读取到的有效字节个数
*/
FileInputStream fis = new FileInputStream("\\b.txt");
byte[] bytes = new byte[1024];
int len =0;
while((len = fis.read(bytes)) != -1){
System.out.println(new String(bytes,0,len));//ABCDE
}
fis.close();
3. 文件复制

FileOutputStream fos = new FileOutputStream("\\des.jpg");
FileInputStream fis = new FileInputStream("\\src.jpg");
byte[] bytes = new byte[1024];
int len =0;
while((len = fis.read(bytes)) != -1){
fos.write(bytes);
}
//先关闭输出流(写入)
//再关闭输入流(读取)
fos.close();
fis.close();
4.字符输入输出流
1). 字节流读取中文存在的问题
windows中一个中文占两个字节
linux中一个中文占三个字节
2).辨析
字节流子类以抽象类inputstream/outputstream结尾
字符流子类以抽象类reader/writer结尾
字节流以字节为单位,字符流以字符为单位,读取写入操作方法类似
3). 常用类
java.io.FileReader extends InputStreamReader extends Reader // 文件字符输入流
5. 其他方法
- flush():
刷新缓冲区到文件,流对象可以继续使用
- close():
刷新缓冲区到文件,流对象关闭,不能再使用
6. 异常处理
/*
JDK1.7 在try后新加() 使用完毕后会自动释放
try(创建流对象;创建流对象,...){
可能出现异常的代码
}catch(异常对象){
异常逻辑处理
}
*/
/*
JDK1.9
A a;
B b;
try(a,b){
可能出现异常的代码
}catch(异常对象){
异常逻辑处理
}
*/
7. 缓冲流
1). 图解
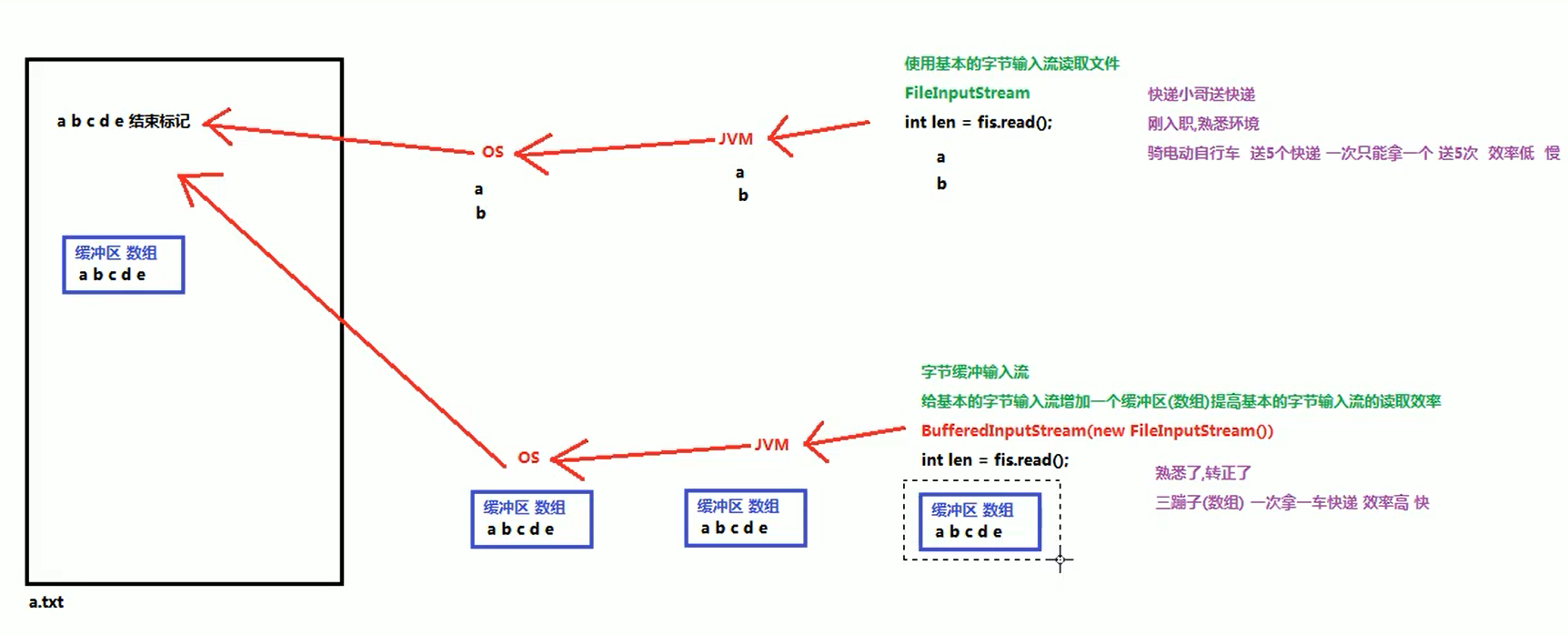
2). 常用类
BufferedOutputStream
BufferedInputStream
BufferedWriter
BufferedReader
3). 构造方法
-
BufferedOutputStream(OutputStream out)//创建一个新的缓冲输出流,以将数据写入指定的底层输出流 -
BufferedOutputStream(OutputStream out,int size)//创建一个新的缓冲输出流,以将具有指定缓冲区大小的数据写入指定的底层输出流params: OutputStream out:字节输出流 可以传递FileOutputStream,缓冲区会给FileOutputStream增加一个缓冲区,提高FileOutputStream的写入效率
//1. 创建字节输出流对象
FileOutputStream fos = new FileOutputStram("\\des.txt");
//2. 创建字节输出缓冲流对象
BufferedOutputStream bos = new BufferedOutputStram(fos);
//3.调用字节输出缓冲流对象的write()方法向内存中写入数据,此时数据并未进入硬盘文件
bos.write("将数据写入到内部缓冲区中".getBytes());
//4.调用字节输出缓冲流对象的flush()方法把内存中数据刷新到硬盘文件中
bos.flush();
//5. 关闭字节输出缓冲流对象,释放资源。close()方法会事先调用flush()方法,因此第4步可省略
bos.close();
8. 转换流
1).编码
a. 结构
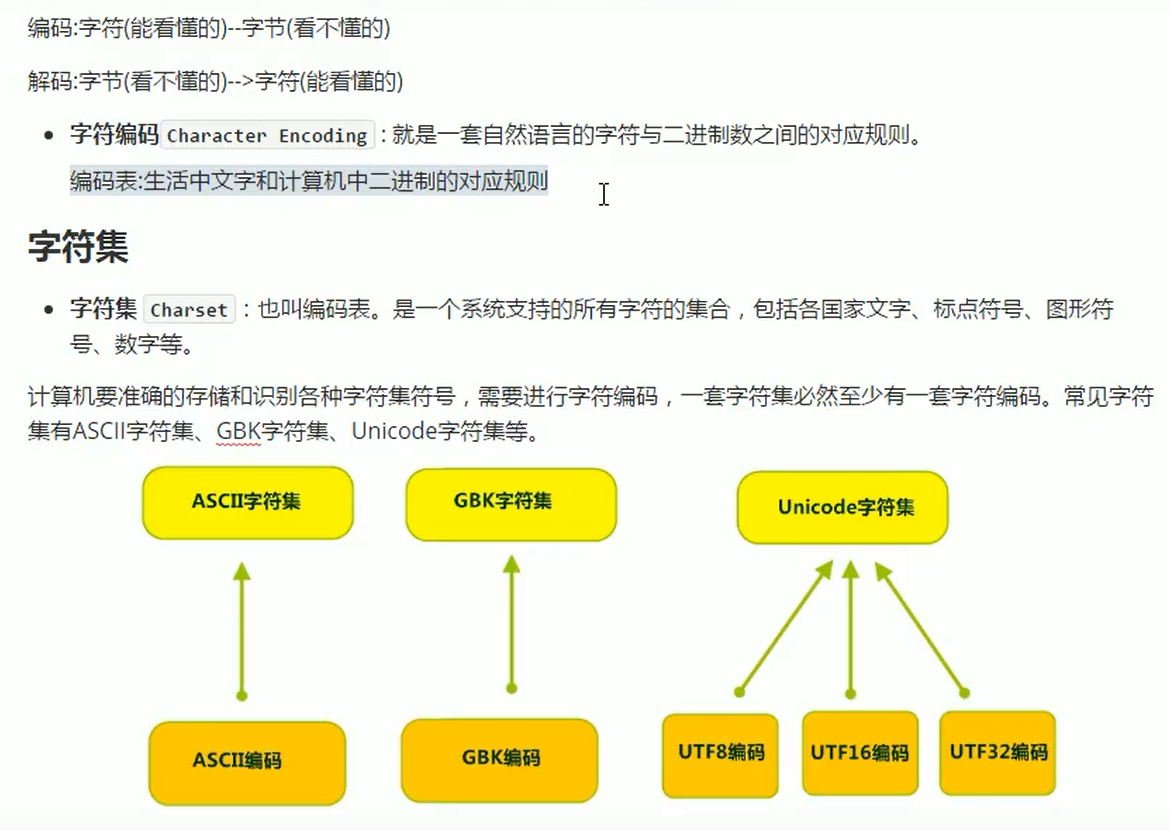
b. UTF-8编码表

c. 易发生的问题
FileReader可以读取IDE默认编码格式(UTF-8)的文件
FileReader读取系统默认编码(中文GBK)会产生乱码
d. 解决方法
转换流
2).转换流解决思路
a. 图解
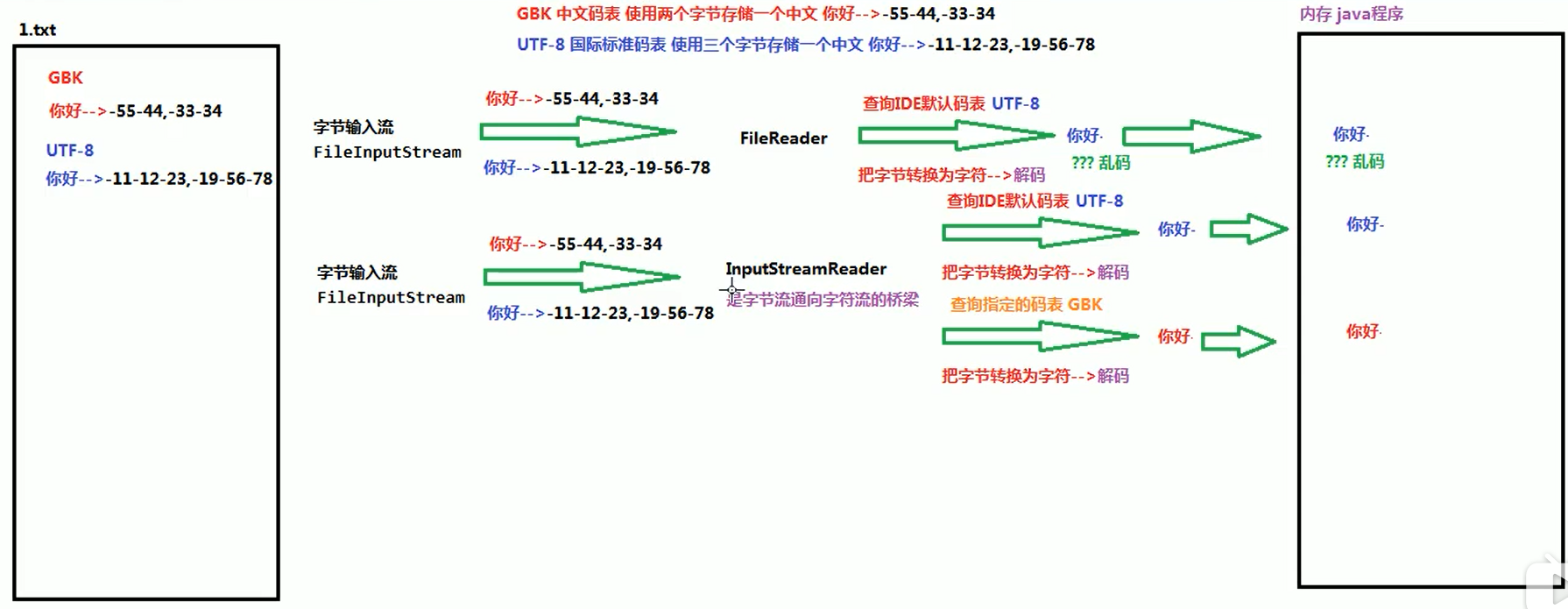
b. 代码
/*
OutputStreamWriter extends FileWriter
存在的意义就是filewriter不能指定写文件的编码格式,因此将字符流转换字节流指定编码格式
*/
public void write_utf_8() throws IOException{
//1. 创建OutputStreamWriter对象,构造方法中传递字节输出流和指定编码表名称
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("utf-8test.txt"),"utf-8");
//2.使用OutputStreamWriter对象中的方法write,把字符转换为字节存储缓冲区中
osw.write("你好");
//3. 使用flush,把缓冲区中数据刷新到硬盘文件中
osw.flush();
//4. 释放资源
osw.close();
}
9. 序列化流和非序列化流
1). 意义
字节或字符文件的输入输出有对应的字节流FileInputStream,...或字符流,FileReader,...
如果需要把对象保存到文件,对象的写入和读取需要相应的流
即ObjectOutputStream对象序列化流,这个过程称为对象序列化,调用的函数为writeObject(Obj object)
ObjectInputStream对象反序列化流,这个过程称为对象反序列化,调用的函数为readObject(Obj object)
2). 图解
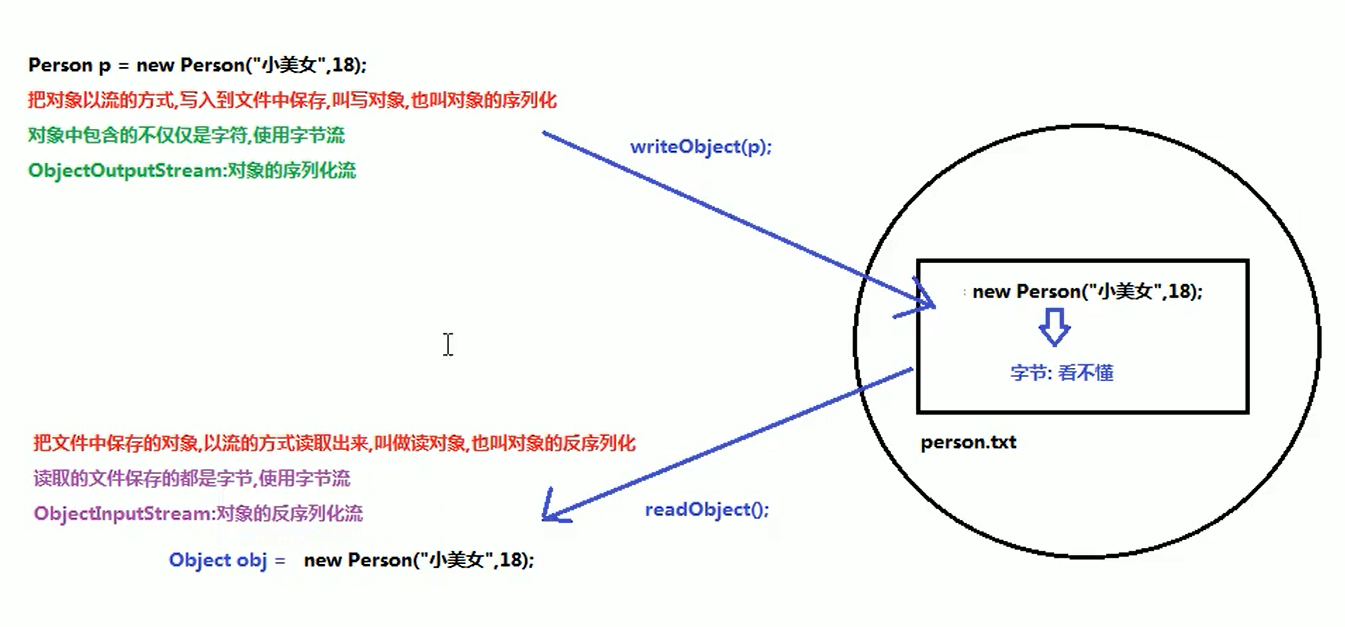
3). 重点
- 进行序列化、反序列化的对象,其类均必须
implements Serializable Serializable为标记型接口(其接口中无任何代码)- 反序列化时,
ObjectInputStream的readObject()还会存在ClassNotFoundException - 反序列化的对象必须存在其类的class文件
- 反序列化时,能找到class文件,但class文件在序列化之后发生改变,则会抛出
InvalidClassException - serialVersionUID
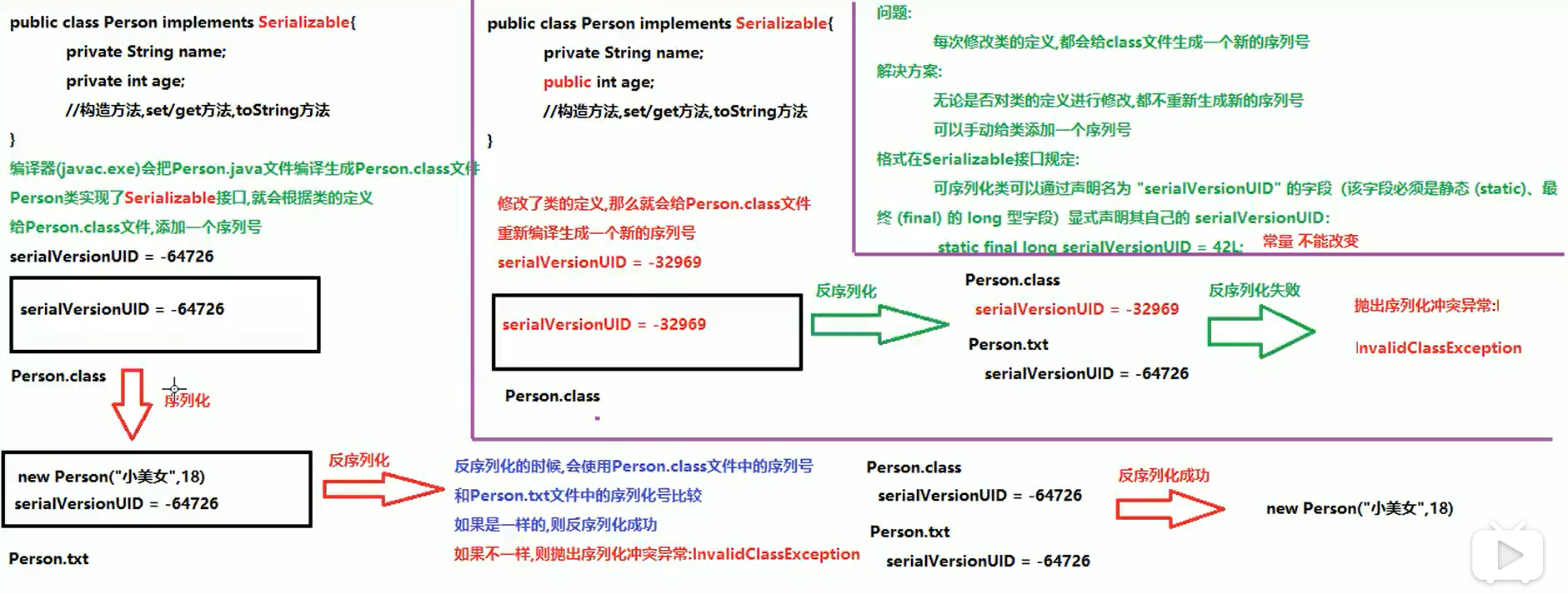
static修饰的成员变量不能进行序列化,因为其一般优先于对象加载,能够实现序列化的都是对象transient(瞬态)修饰的成员变量同样不能进行序列化,因此不需要序列化的成员变量(或节省空间,或可以推导),可以用transient修饰(static修饰多有不便)
4).实现
a. 序列化
public class Person implements Serializable{
...
}
public static void main(String[] args) throws IOException{
//1. 构造方法如下
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("\\person.txt"));
//2. 写入对象方法如下
oos.writeObject(new Person("郭靖",20));
//3. 释放资源
oos.close();
}
b. 反序列化
public static void main(String[] args) throws IOException, ClassNotFoundException{
//1. 构造方法如下
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("person.txt"));
//2. 读取对象函数如下
Object obj = ois.readObject();
//3. 资源释放
ois.close();
//4. 打印读取的对象
System.out.println(obj);
}
10. 打印流
public static void main(String[] args) throws FileNotFoundException{
System.out.println("在控制台输出");
//创建打印流
PrintStream ps = new PrintStream("destinationIsChanged.txt");
//改变输出语句的目的
System.setOut(ps);
//测试
System.out.println("在destinationIsChanged.txt输出");
//释放资源
ps.close();
}
十、 Properties集合
java.util.Properties extends HashTable<k,v> implements Map<k,v>
1. 特性
- 表示一个持久的属性集,可保存在流中或从流中加载
- Properties集合是唯一和流相结合的集合
- key和value默认为字符串
2. 常用方法
-
Object setProperty(String key,String value) // 调用Hashtable中的put()方法 -
String getProperty(String key)//通过key获取value -
Set<String> stringPropertyNames() // 返回此属性列表的键集合,相当Map集合中的keySet()方法 -
void store(OutputStream out,String comments) //把集合中的临时数据,持久化写入到硬盘存储 -
void store(Writer writer,String comments)params:
OutputStream out: 字节输出流,不能写入中文
Writer writer: 字符输出流,可以写入中文
String comments: 注释,解释说明保存的文件用处,一般使用"",不能使用中文,会乱码,默认是Unicode编码
//默认键值均为String
Properties prop = new Properties();
prop.setProperty("machieal","11");
FileWriter fw = new FileWriter("\\test.txt");
prop.store(fw,"save data");
fw.close();
-
void load(InputStream in) //把硬盘中保存的文件(键值对),读取到集合中使用 -
void load(Reader reader)params:InputStream in: 字节输入流,不能读取含有中文的键值对
Writer writer: 字符输入流,可以读取含有中文的键值对
Notices
a. 存储键值对的文件中,键值默认的连接符号可以使用=,空格(或其他符号)
b. 存储键值对的文件中,可以使用
#进行注释 ,被注释的键值对不会再被读取c. 存储键值对的文件中,键值默认都是字符串,不用再加引号
//1. 创建集合对象
Properties prop = new Properties();
//2.使用Properties集合对象中的load()读取文件,流对象匿名创建使用完会自动关闭
prop.load(new FileReader("\\prop.txt"));
//3. 遍历Properties集合
Set<String> set = prop.stringPropertyNames();
for(String key : set){
String value = prop.getProperty(key);
System.out.println(key + "=" + value);
}
