

哈希与一致性哈希
前言
上篇文章 支付系统 - 雪花算法与多键分表 提到了对传入 Long 类型的数值进行哈希以保证其均匀,但是因为篇幅原因没有展开, 故这篇补上。
本文从以下几点展开:
- 哈希算法是什么
- 哈希算法应用场景
- 常见的哈希算法
- 哈希算法应用时存在的问题
- 哈希如何才能均匀
- 为什么需要一致性哈希
- 一致性哈希的实现
哈希算法是什么
首先需要声明哈希算法不是指一种算法的具体实现,而是指一类算法,我们来看看维基百科怎么说:
散列函数(英语:Hash function)又称散列算法、哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值(hash values,hash codes,hash sums,或 hashes)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表。
如今,散列算法也被用来加密存在数据库中的密码(password)字符串,由于散列算法所计算出来的散列值(Hash Value)具有不可逆(无法逆向演算回原本的数值)的性质,因此可有效的保护密码。
维基中提到的数字指纹也被称为消息摘要,英文名称是message digest。其实就是运算后的哈希值或者称为散列值。下文为了描述起来方便,统一称为哈希值。
说的这么学院派不好理解,你可以认为函数func(x)=y,这个y就是哈希值,函数本身就是哈希算法的具体实现。
那哈希算法主要的用途是什么呢?宽泛一点说是做比较,虽然很多程序也把它用来加密。
另外,许多哈希算法都是满足以下三大特性的:
- 安全性
通过该算法得到的消息摘要不可被反解,意味着你不可以通过结果反推出原始待运算的数据。
- 固定长度
通过该算法得到的消息摘要长度是固定的,无论原始待运算数据长度是长或者短(非开车)。
- 唯一性
通过该算法得到的消息摘要是唯一的,不同的原始数据不能得到相同的哈希值。
哈希算法应用场景
安全加密
OK,想想我们经常使用的账号密码登录功能,那我们的密码是在数据库中如何保存的呢?这里直接给出定论:任何安全的应用都不应该存储用户密码明文在数据库中(还记得 CSDN 密码泄露事件吗?)。
因此,一些普通的应用可以使用哈希算法来对密码进行加密,存储在库中的密码值即哈希值。我们可以使用同样的算法在应用中计算并比较两个值是否相同,以此来确定密码正确与否。
直接使用哈希算法保存密码是不建议的。因为如果攻击者拿到了数据库权限,通过彩虹表反查出了某一用户哈希值对应的原始密码。那库中和其具有相同原始密码的用户,账户也就泄露了。一般的做法是加盐 hash(x + salt ) = y,特别注意每一个用户需要具有不同的盐值。这样就防止了一个密码被破 Jie,其他密码相同用户也被破 Jie 的风险。
其实,这里加盐也不是特别安全。一般的应用在安全和开发之间合理取舍,安全无上限,安全领域的话题本文不再班门弄斧了。
数据校验
想象一下你在网站上下载大文件的时候,是怎么确定下载下的文件是完整的呢?看一下我们熟悉的JDK:

Checksum:总和检验码,校验和。在数据处理和数据通信领域中,用于校验目的的一组数据项的和。这些数据项可 以是数字或在计算检验总和过程中看作数字的其它字符串。通常是以十六进制为数制表示的形式。 【作用】就是用于检查文件完整性,检测文件是否被恶意篡改,比如文件传输(如插件、固件升级包等)场景使用。
由于哈希算法对数据很敏感,哪怕发生一点变化产生的哈希值都大相径庭。它的做法是对原始文件二进制进行哈希得到哈希值再和你下载下来的做比较。当然,如果文件是分段下载的,对每个段进行哈希再分别比较也是可以的。
唯一标识
不知道你有没有遇到过在云盘上传大文件时,发现瞬间上传完成了,这不是因为你的带宽大。而是因为云盘服务发现该文件已在服务端存在,所以简单的标记了下你的个人空间并且取消了你的上传行为。那它是怎么判断的呢?要知道文件虽然相同但标题不一定是一样的。一种思路是,获取原始文件二进制串取特定的多位进行组合然后哈希,做为该文件的摘要。这个摘要就可以做为该文件的唯一 Id。如此就可以精准的判断文件在服务端的信息了。
函数运算
首先哈希算法本身就是一个函数,那最简单的可以得到一个值,那这个值可以做为我们运算的一个元素。举个例子,在Java中计算对象的hashcode这就是一种运算。当然在这种场景下,运算效率和数据分布的均匀程度是需要重点关注的。
为什么需要关注均匀程度呢?以负载均衡举例,先假设这个算法是机器的某些属性进行哈希,然后以这个哈希值模机器节点的数量。也就是hash(machine_meta) mod machine_nodes。那么你想一下如果这个哈希算法运算后的哈希值不均匀,就容易出现数据倾斜的问题。现象是有很多机器空闲,资源得到了极大的浪费。
常见的哈希算法
这里只是简单介绍,感兴趣的可以自己去 Google 一下,你会得到不一样的快乐。
MD5
MD5 信息摘要算法(英语:MD5 Message-Digest Algorithm),是一种被广泛使用的密码散列函数,通过输入不定长度信息经过程序流程,生成四个 32 位数据,最后联合起来产生出一个 128 位(16 字节)的散列值(hash value),用于确保信息传输完整一致。MD5 算法因其普遍、稳定、快速的特点,仍广泛应用于普通数据的加密保护领域。它由 MD2、MD3、MD4 发展而来。一般为了位数短些,我们都会把它转成 16 进制进行存储。
SHA-1
SHA-1(英语:Secure Hash Algorithm 1,中文名:安全散列算法 1)是一种密码散列函数,美国国家安全局设计,并由美国国家标准技术研究所(NIST)发布为联邦数据处理标准(FIPS)。SHA-1 可以生成一个被称为消息摘要的 160 位(20 字节)散列值,散列值通常的呈现形式为 40 个十六进制数。
AES
高级加密标准(英语:Advanced Encryption Standard,缩写:AES),在密码学中又称 Rijndael 加密法,是美国联邦政府采用的一种区块加密标准。这个标准用来替代原先的 DES,已经被多方分析且广为全世界所使用。经过五年的甄选流程,高级加密标准由美国国家标准与技术研究院(NIST)于 2001 年 11 月 26 日发布于 FIPS PUB 197,并在 2002 年 5 月 26 日成为有效的标准。现在,高级加密标准已然成为对称密钥加密中最流行的算法之一。
哈希算法应用时存在的问题
任何技术都有其缺点,哈希算法也不例外。以下篇幅讲讲使用哈希算法设计数据结构时遇到的问题。
散列冲突
这个问题其实特别简单,按照固定长度原则,如果你设计的算法最后结果是生成16位的比特,那么它总数是1 << 16个,按照唯一性原则也就是原始待运算数据超过1 << 16后,就会出现重复的值,这就是所谓的散列冲突,又言哈希碰撞。注意,并不是说只有满了才会出现哈希碰撞,因为算法设计的原因也会造成。因此,评判一个哈希函数设计的优劣,碰撞率也是一个重要的因素。
可能有的朋友会想如果增加结果位数呢?答案是治标不治本,只要理论上有最大值,那它肯定会出现冲突的情况。那怎么解决这个问题呢?快来跟小编一起看看吧(有 nei 味吗):
常见的解决散列冲突有两种方法,开放寻址法和链表法。
开放寻址法
在此方法下还有几种经典的实现,如线性探测法、二次方探测、双重散列。下面依次来说明:
1)线性探测法
这种方法很简单。举个例子,当你去电影院发现自己的座位被占了,那么你就会依次看看后面还有没有空位,直到找到为止。理解到这里就行了,缺点是当你来晚了以后你去找的时候发现很多位置都被别人占了。最惨的情况是,假设一共只有1000个座位,你的1号位被占了,当你找到1000的时候才发现了空位。可想而知,最坏的情况下时间复杂度为O(n)。
另外,这个例子举得不是那么恰当,按照哈希精神(我瞎叫的)可能会有很多人和你买了一个座号,领会精神,下文就不再特别指出这个例子的不当之处了。
2)二次方探测
这种方法也很简单,属于上面的优化。你不是一个一个看有没有空位吗?我机灵一点,一次多看几个。举例:我买了5号位被人占了,那我先往后看看5+1^2=6有没有位置,如果没有再往前看看5-1^2=4有没有位置,如果还没有再看5+2^2=9有没有位置,然后5-2^2=1直到找到为止。这,简直就是反复横跳。为了方便理解,我画了张图。
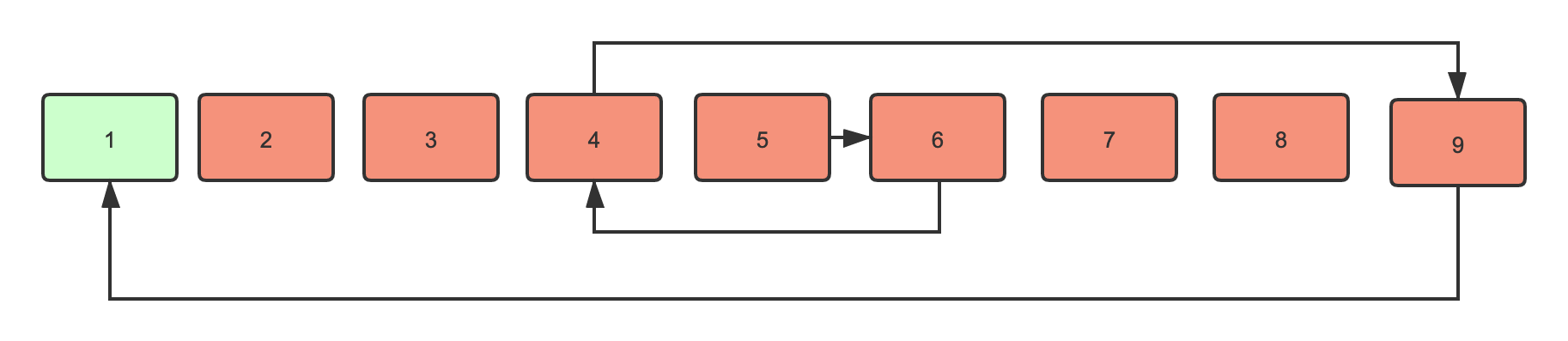
其中只有一个的位置是没有冲突的,所以经过几次探测确定了这个槽位置。
3)双重散列
简单的说就是两个哈希算法hash1(x)=y,y被占了,在使用hash2(x)=z,如果z有空位就结束。当然如果再次哈希时还是冲突,那么还需要再解决,可以是继续往下探测。需要注意的是如果设计不当会出现循环哈希。
事实上,一般的哈希结构设计时会有加载因子的概念,英文是load factor。表示在所有可提供的存储空间中,元素填满的比例。举例说,就是电影院满座1000,加载因子设为0.75那只有750个座位可选。也就是说最少有250个空位,那你再次遇到占座的情况时重新挑座位就不那么费工夫了。缺点也很明显,设置小了浪费空间,设置大了容易冲突,根据场景自己取舍吧。

看见这个loadFactor了没,没错就是这个家伙,在HashMap中默认值是0.75。
链表法
这种就更简单了。举例,还是你在电影院被占座了,这次工作人员不让你自己再瞎找座位了,而是给你放个小凳子让你坐过道里。然后可能你会发现有很多兄弟也被工作人员安排坐你旁边了,你一打问原来这些兄弟和你买的票是同一个座位号。
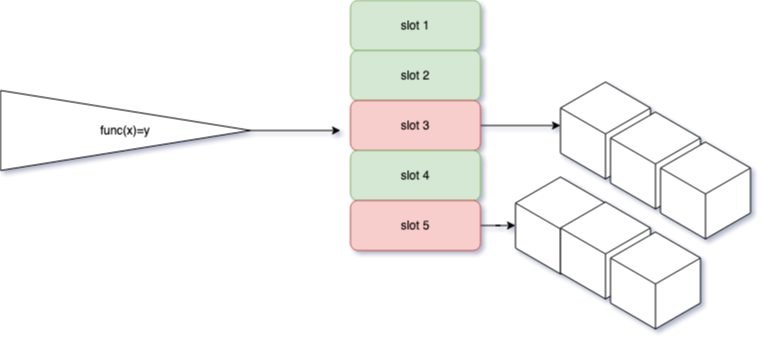
说正式点就是,当哈希得到的结果位置已经被别的元素占据就在此位置外挂一条链表,并插入进去即可。看图,红色的代表已经存在哈希值,然后将自身元素保存在外挂链表中。这里就不讲具体的实现了,领会精神。
哈希如何才能均匀
这个问题请参考以下链接,除了一些优化以外更多的是经验值。
- 经典的 Times 33 哈希算法
- 为什么 Java String 哈希乘数为 31?
- Why does Java's hashCode() in String use 31 as a multiplier?
为什么需要一致性哈希
一致性哈希最早是 1997 年在麻省理工大学提出的一种解决热点问题的算法。后来在分布式环境被广泛使用。
试想象一下分布式应用中常见的场景:有N台服务器需要提供缓存服务,我们需要将不同应用请求流量平均负载到不同的机器上。也就是每台机器承载1/N的流量。你写了一个算法,就是简单的取模(忘了说了取模也是哈希算法),可能是这样的简单且朴实无华uid mod machine_nodes得到一个0到machine_nodes-1之间的数,这样就能正确的路由到机器上。当然前提是这个哈希值要是均匀的,否则有些机器可能会流量很多,而有些则无所事事。
然后愉快的上线了,突然有一天一台机器宕掉了。幸好机智的你写的程序非常的 robust,做了自动探活,把这个服务节点摘掉了。那么问题来了,以前哈希路由的机器现在拒绝服务,意味着这个路由算法需要更改为uid mod machine_nodes-1。可是我们的缓存数据是死的,现在需要做数据迁移。并且在此期间内,大量缓存集体失效会造成应用程序大量流量打到数据库,严重影响上层业务的稳定性甚至造成奔溃。想想有多少比例机器需要做迁移呢?答案是(N-1)/N,不信我来帮你捋一下:
比如有 3 台机器,hash 值 1-6 在这3台上的分布就是:
1 mod 3 = 12 mod 3 = 23 mod 3 = 04 mod 3 = 15 mod 3 = 26 mod 3 = 0
3 6落到了machine_0,1 4落到了machine_1,2 5落到了machine_2。
现在机器machine_1挂了,数据分布情况变为了:
1 mod 2 = 12 mod 2 = 03 mod 2 = 14 mod 2 = 05 mod 2 = 16 mod 2 = 0
2 4 6落到了machine_0,1 3 5落到了machine_2。
注意这里machine_2就是取模后结果为1对应的新机器。
为了方便理解,我画了个图:
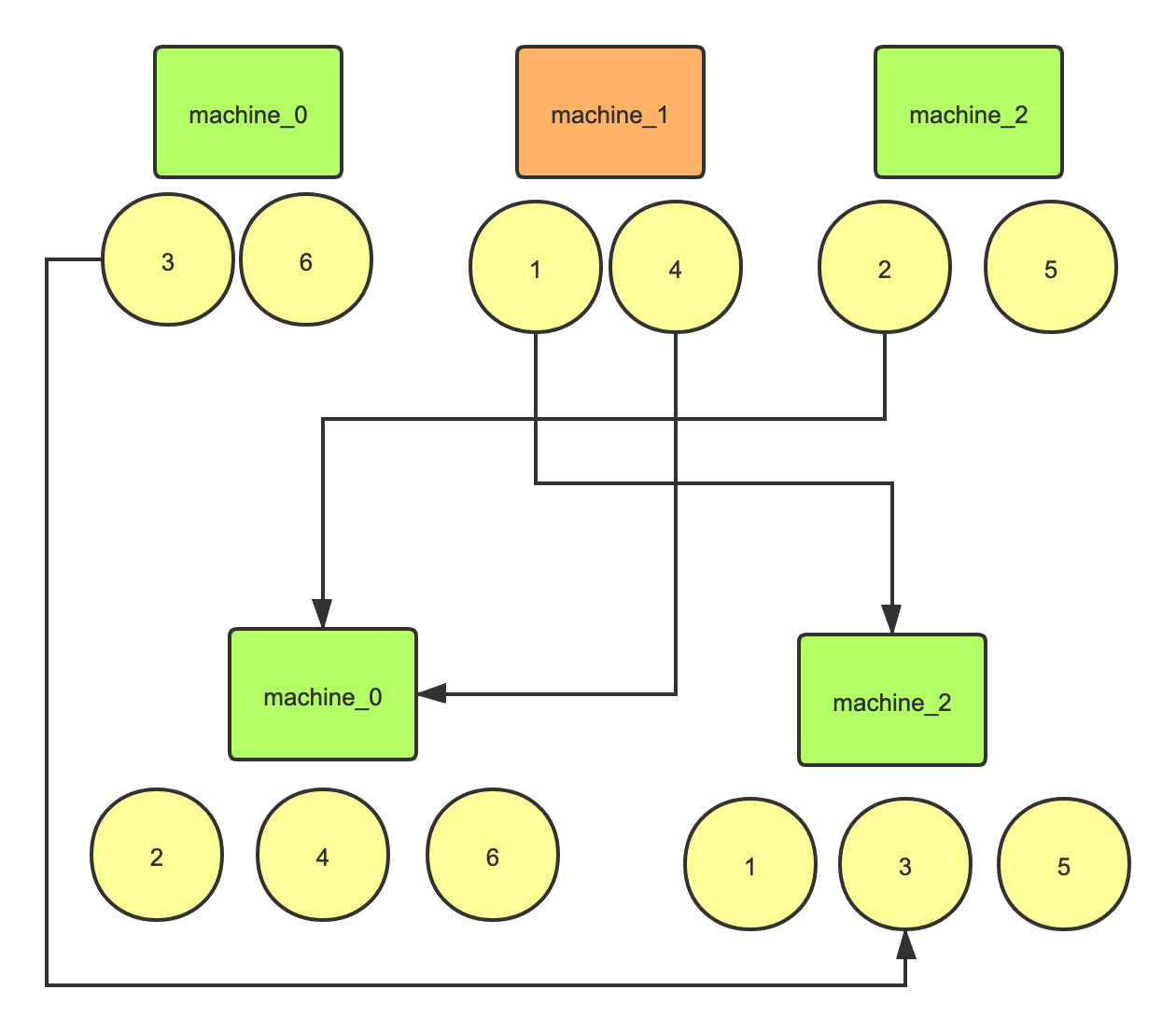
图画的有点乱,可以看出一共4条连线,占总数据6的2/3,并且两台机器做迁移成本还是很高的。满足上面的公式(N-1)/N,如果有1000台服务机器,挂掉了1台,需要做迁移的机器为999/1000这在分布式环境中会出现极大的不稳定。所以才有了一致性哈希算法的提出。
一致性哈希的原理
实际上一致性哈希也是采用取模的方式,不过模的不是机器数而是固定的2^32,二的三十二次方。
我们可以把这个看做是由2^32节点组成的圆,为了方便理解我又画了张图:
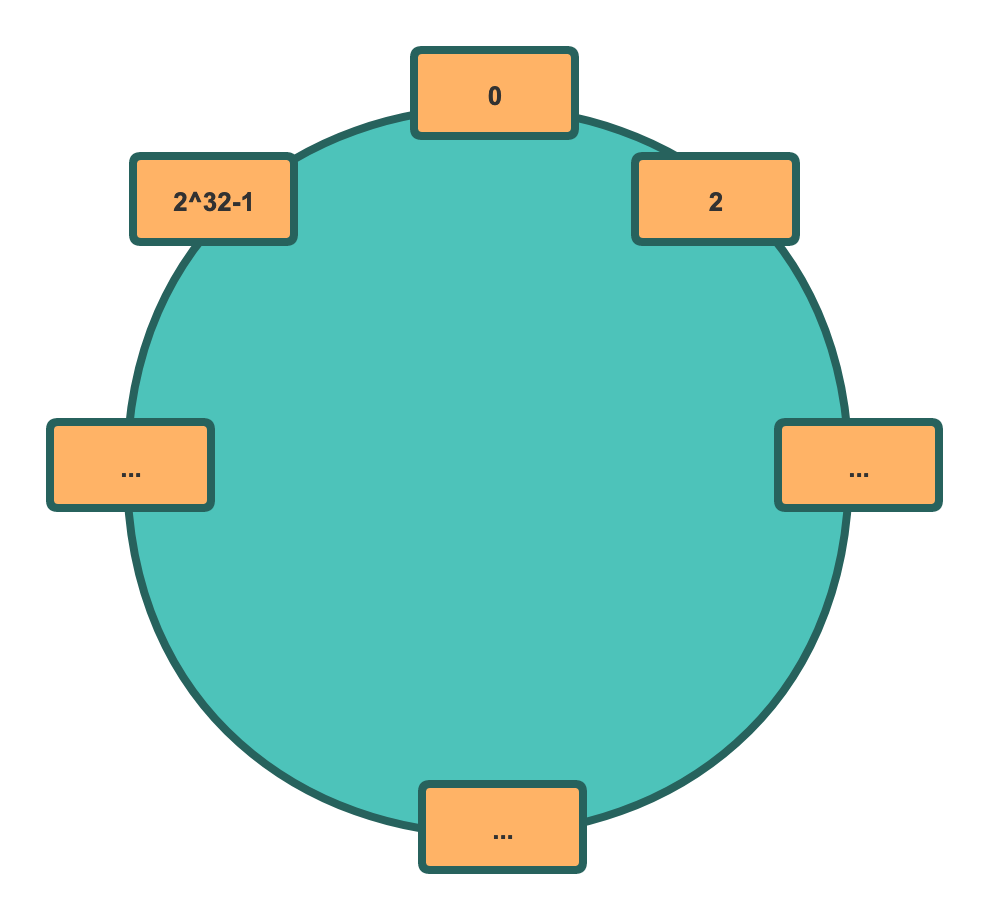
按照之前的理论,现在 hash 值 1-6也是可以映射到环上的某一节点上,通过1 2 3 4 5 6 mod 2^32。那我们服务器怎么在环上确定位置呢?一种常规的做法是使用服务器的元信息,如IP取模,即hash(Ip) mod 2^32。假设我们有三台机器A、B、C,取模后在环上的位置如图所示:
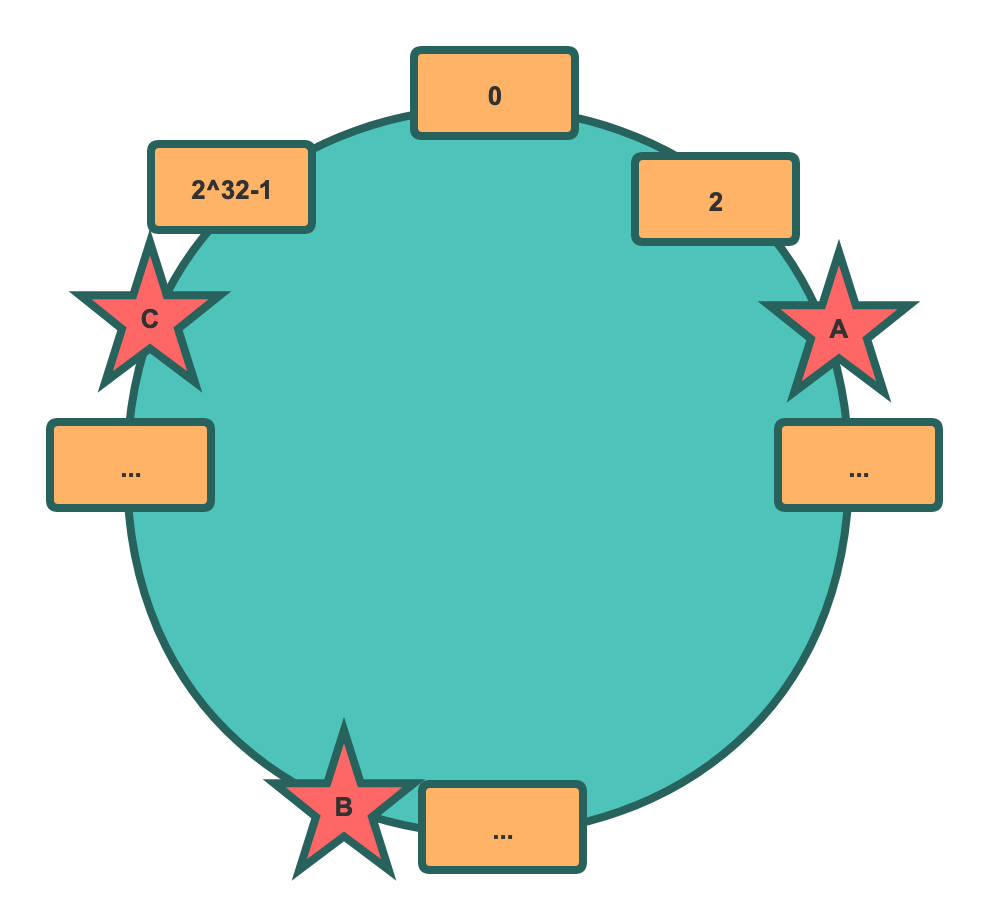
当然这是理想情况,那数据如何确定保存在哪个服务器呢?
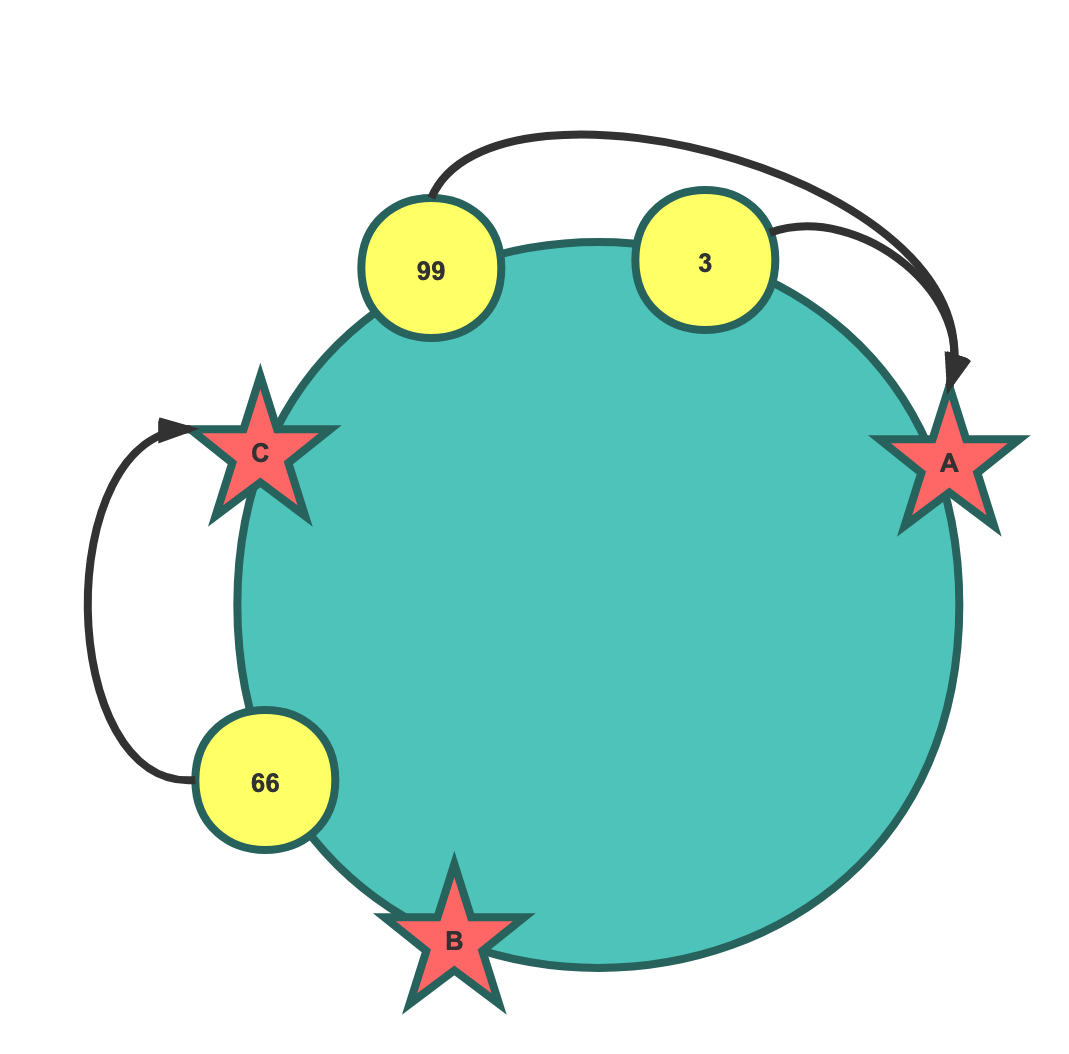
如图示,某元素经过哈希后得到哈希值3按环中顺时针方向遇到的下一个机器节点为A,那它就保存在A服务器上,99也是。顺理成章,66保存在C服务器。
很容易理解对不对?但是这种算法能解决普通取模带来的数据搬移问题吗?假设现在图中的C机器宕机了,66只需要搬移到A机器即可,A机器不用搬移数据到B机器。在环中只有部分链路的数据需要搬移,这是很明显的好处。
但是,上面也说了这是理想的服务器分布情况,很均匀的一分为三,保证每台机器保留1/3的数据。实际情况恐怕没这么理想,它可能是这样的:

oh my god,这种情况下我们应该这么做呢?大部分的数据都落在了A机器上,出现了很严重的数据倾斜。
机智的前辈搞出了虚拟节点的概念,虽然我并不在那里,但是你可以认为那里就是我的地盘。看图:

如图,这样数据就可以均匀的分布在虚拟节点上。虚拟节点越多,hash 环上的节点就越多,缓存被均匀分布的概率就越大。
如此,问题便被解决了,同样是生活在二十一世纪的科技从业者,为什么思想差距这么大呢?不过,虽然我想不到,但是我可以实现啊。
一致性哈希的实现
这里写了一段伪代码,供参考,领会精神即可。
public class ConsistentHash {
private final IHashFunction hashFunction; //哈希函数
private final int numberOfReplicas; //所有的节点数
private final SortedMap<Integer /** 节点哈希 **/, MachineNode /** 机器信息**/> circle = new TreeMap<Integer, MachineNode>(); //共有numberOfReplicas个元素
public ConsistentHash(IHashFunction hashFunction, int numberOfReplicas, Collection<MachineNode> nodes) {
this.hashFunction = hashFunction;
this.numberOfReplicas = numberOfReplicas;
//构建哈希环
for (MachineNode node : nodes) {
add(node);
}
}
public void add(MachineNode node) {
for (int i = 0; i < numberOfReplicas; i++) {
//树中的元素会按照自然排序
circle.put(hashFunction.hash(node.toString() + i), node);
}
}
//沿环的顺时针找到虚拟节点
public MachineNode get(Object key) {
if (circle.isEmpty()) {
return null;
}
//计算数据的哈希值
int hash = hashFunction.hash(key);
if (!circle.containsKey(hash)) { //如果数据的哈希值没有落在节点上
//找到该哈希值自然排序后的所有后续节点
SortedMap<Integer, MachineNode> tailMap = circle.tailMap(hash);
//有就取后续的第一个,否则就取所有节点的第一个
hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
}
// 如果数据的哈希值正好落在了节点上那直接取节点信息
return circle.get(hash);
}
//机器信息
private static class MachineNode {
private String ip;
@Override
public String toString() {
return this.ip;
}
}
//哈希函数
private static interface IHashFunction {
int hash(Object key);
}
这段代码很简单,需要注意的是TreeMap这中数据结构会按照元素的自然顺序排序,并且可以很轻松的从某个key开始获取后面的元素。我举个例子:
TreeMap map = new TreeMap<Integer, MachineNode>();
MachineNode A = new MachineNode();
MachineNode B = new MachineNode();
MachineNode C = new MachineNode();
MachineNode E = new MachineNode();
map.put(5, E);
map.put(1, A);
map.put(2, B);
map.put(3, C);
System.out.println(JSON.toJSONString(map));
// {1:{},2:{},3:{},5:{},6:{}}
SortedMap tailMap = map.tailMap(4);
System.out.println(JSON.toJSONString(tailMap));
// {5:{},6:{}}
看到这里我想你应该懂了,为什么要使用这种数据结构来实现了。哦,对了哈希算法需要自己实现。
综上,一致性哈希算法只是一种减少由扩缩容引起的命中率下降的手段,和高可用或者强一致性没有关系。如果想要学习一致性哈希怎么实现,也可以参考文章 对一致性 Hash 算法,Java 代码实现的深入研究 的内容。
后语
本文都是本人经验的一些总结,难免疏漏甚至是错误,如果有不合理、不足,还望指正。哦对了,如果对你有帮助请点赞,如果对你没帮助请举报。
