

from Towards Logical Specification of Statistical Machine Learning
Content
-
Preliminaries
前导知识,没怎么看懂,不过好像不影响后面
-
Techniques for Conditional Indistinguishability
-
Counterfactual Epistemic Operators
介绍了两个操作符,主要为形式化公平这个属性做准备
-
Conditional Indistinguishability via Counterfactual Knowledge
如何用上文描述的两个操作符去表示'Conditional Indistinguishability'
-
-
Formal Model for Statistical Classification
-
Statistical Classification Problems
给出了一些定义:
, L be a finite set of class labels, D be the finite set of input data (called feature vectors) that we want to classify.
: be a scoring function that gives a score f(v, ℓ) of predicting the class of an input datum (feature vector) v as a label ℓ.
: to represent that a label ℓ maximizes f(v, ℓ).
-
Modeling the Behaviours of Classifiers
给出了两个公式
ψ(x, y) to represent that C classifies a given input x as a class y.
h(x, y) to represent that y is the actual class of an input x.
-
-
Formalizing the Classification Performance
-
形式化 correctness
-
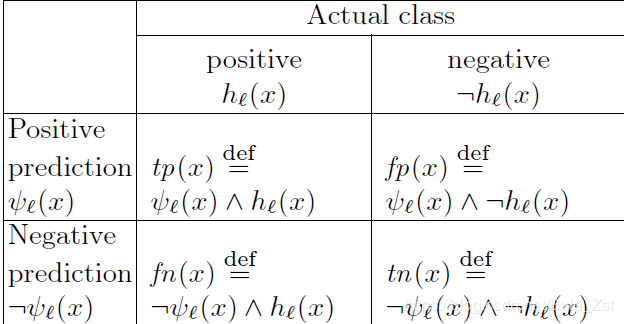
-
true positive:
.
-
the precision being within an interval I is given by:
or
.
-
and
.
-
and
.
-
and
.
-
-
Formalizing the Robustness of Classifiers
- Probabilistic Robustness against Targeted Attacks
- 定义:When a robustness attack aims at misclassifying an input as a specific target label, then it is called a targeted attack.
represents that the classifier C is confident that ϕ is true as far as it classifies the test data that are perturbed by a level ε of noise.
- D defined by
where v and v′ range over the datasets supp(σw(x)) and supp(σw′ (x)) respectively.
- 以下是给出的公式:
, which represents that a panda’s photo x will not be recognized as a gibbon at all after the photo is perturbed by noise.
.
- Probabilistic Robustness against Non-Targeted Attacks
.
- 结论:
.
- robustness can be regarded as recall in the presence of perturbed noise.
- Probabilistic Robustness against Targeted Attacks
-
Formalizing the Fairness of Classifiers
- 符号定义
.
.
- Group Fairness (Statistical Parity)
- 定义:the property that the output distributions of the classifier are identical for different groups.
.
.
.
- Individual Fairness (as Lipschitz Property)
- the property that the classifier outputs similar labels given similar inputs.
.
.
- Equal Opportunity
- the property that the recall (true positive rate) is the same for all the groups.
.
- 符号定义
